论文分享 - Machine Comprehension Using Match-LSTM and Answer Pointer
介绍
在Machine Comprehension(MC)任务中,早期数据库规模小,主要使用pipeline的方法;后来随着深度学习的发展,2016年,一个比较大规模的数据库出现了,即SQuAD。该文是第一个在SQuAD数据库上测试的端到端神经网络模型。主要结构包括两部分:Match-LSTM和Pointer-Net,并针对Pointer-Net设计了两种使用方法,序列模型(Sequence Model)和边界模型(Boundary Model)。最终训练效果好于原数据库发布时附带的手动抽取特征+LR模型。
- match-LSTM是作者早些时候在文本蕴含(textual entertainment)任务中提出的,可参考《Learning natural language inference with LSTM》
- 代码:https://github.com/shuohangwang/SeqMatchSeq
模型
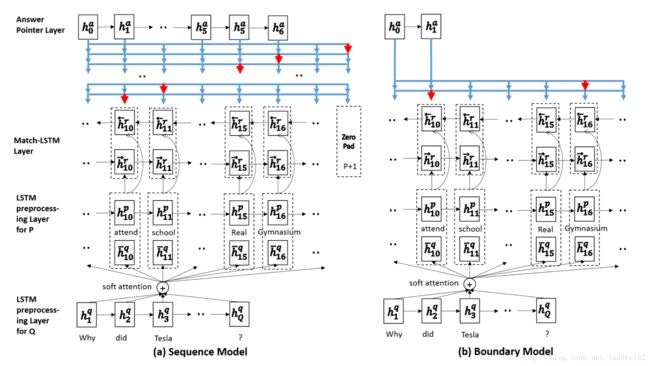
- 序列模型:使用Ptr-Net网络,不做连续性假设,预测答案存在与原文的每一个位置
- 边界模型:直接使用Ptr-Net网络预测答案在原文中起始和结束位置
这两种模型都分为三部分:
- LSTM预处理层:编码原文以及上下文信息
- match-LSTM层:匹配原文和问题
- Ans-Ptr层:从原文中选取答案
LSTM预处理层
直接使用单向LSTM,故而每一个时刻的隐含层向量输出只包含左侧上下文信息
match-LSTM层
在文本蕴含任务中,输入一个文本对,假设句T和蕴含句H,这里将question当做T,passage当做H。下面是match-LSTM的构建,实质上就是一个attention机制。
这里可以针对passage每一个词语输出一个 αi→ α i → 向量,这个向量维度是question词长度,故而这种方法也叫做question-aware attention passage representation。
下面将attention向量与原问题编码向量点乘,得到passage中第i个token的question关联信息,再与passage中第i个token的编码向量做concat,粘贴为一个向量 zi→ z i → ,然后输出到LSTM网络中。
上述就是match-LSTM的标准结构,这里更进一步,为了捕捉到更丰富的上下文信息,再增加一个反向match-LSTM网络。基本结构同上。最终,只需要将正向match-LSTM输出的隐含层向量 Hr−→ H r → 和反向match-LSTM输出的隐含层向量 Hr←− H r ← 拼接起来即可。
Answer-Pointer层
这块分为两种方法,即上文所提到的sequence model和boundary model,分别如下:
Sequence Model
序列模型不限定答案的范围,即可以连续出现,也可以不连续出现,因此需要输出答案每一个词语的位置。又因答案长度不确定,因此输出的向量长度也是不确定的,需要手动制定一个终结符。假设passage长度为P,则终结符为P+1。
对于pointer net网络,实质上仍然是一个attention机制的应用,只不过直接将attention向量作为匹配概率输出。
答案 a a 第k个词对应passage位置为:
对于输出,直接搜索所有位置,并取最大概率的即可;训练过程中,设计对数损失函数如下:
Boundary Model
边界模型直接假设答案在passage中连续出现,因此只需要输出起始位置s和终止位置e即可。基本结构同Sequence Model,只需要将输出向量改为两个,并去掉终结符。
同样,上述两种模型都可以改用双向LSTM。
实验
实验是在SQuAD数据库上进行的,包括两个评价指标:EM和F1,其中,EM指完全匹配程度。结果如下:

思考
- 观测数据发现长的答案更难预测,当答案包含大于9个tokens时,f1值跌落至55%左右,em值到30%左右
- 该模型更适合“是什么”类型问题,对于“为什么”类型效果较差
- 作者对上文中match-LSTM层的attention向量 α α 做可视化,与事实相符,该向量应该是描述question与passage每一个位置的相关程度的