centos6.8平台上安装hive(基于Mysql6.5 和hadoop2.7.3伪分布集群下)
一、安装JDK
解压jdk-8u111-linux-x64.tar.gz
重命名文件夹 mv /opt/j dk-8u111 /usr/java
配置环境变量
使环境变量生效
![]()
二、mysql5.6安装(centos6.8)
yum list installed | grepmysql
yum -y removemysql-libs.x86_64
wgethttp://dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm
rpm -ivhmysql-community-release-el6-5.noarch.rpm
yum clean all
yum installmysql-community-server
service mysqld start
mysql_secure_installation
登录mysql重设密码的问题

启动mysql:
#/etc/init.d/mysqld start

启动成功后查看mysql进程信息,获取mysqld_safe的安装目录(非常关键):
#ps -ef | grep -i mysql

可以看到mysqld_safe的安装位置(上面标红色框部分):/usr/bin/
接着执行一下命令停止mysql:
/etc/init.d/mysql stop
以安全方式启动mysql:
#/usr/bin/mysqld_safe --skip-grant-tables >/dev/null 2>&1 &![]()
稍等5秒钟,然后执行以下语句:
#/usr/bin/mysql -u root mysql
注意:mysql与mysql_safe目录一样,都是:/usr/bin/下,这个是通过“ps -ef | grep -i mysql”命令得到的。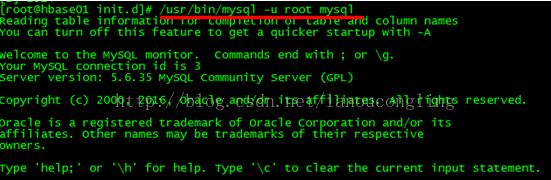
出现“mysql>”提示符后输入:
mysql> update user set password = Password('root') where User = 'root';

回车后执行(刷新MySQL系统权限相关的表):
mysql> flush privileges;
![]()
再执行exit退出:
mysql> exit;
退出后,使用以下命令登陆mysql,试试是否成功:
#mysql -u root -p
按提示输入密码:root
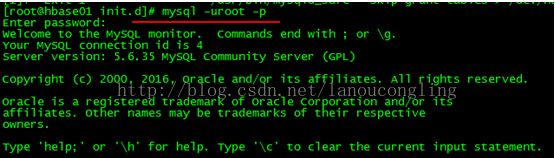
mysql> show databases;

配置hive需要的数据库内容
创建hive运行所需要的元数据数据库:
create database myhive;

创建hive运行所需要的用户,该用户应该能够在说有的机器上登录:
create user myhive@'%' identified by 'myhive';
![]()
给新创建的hive用户授权,应该允许该用户操作hive数据库下的所有内容:
grant all on myhive.* to myhive@'%'identified by 'myhive';
![]()
更新权限:
flush privileges;

验证是否可以远程登录:(在windows下)
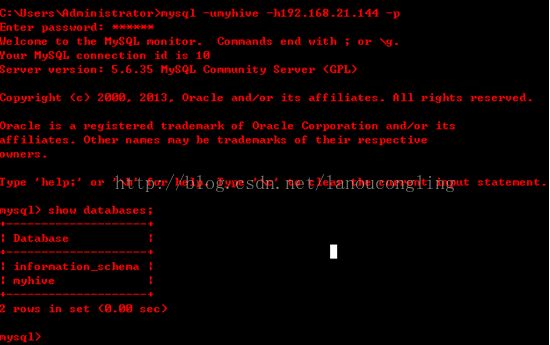
三、安装hadoop
确保ssh是已经安装和运行
service sshdstatus ;如果没有运行,service sshd start;如果没有安装,运行yum install ssh\* -y。
![]()
关闭SELinux
vim/etc/selinux/config
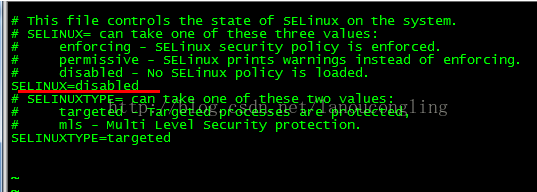
关闭完成后,重启linux。
![]()
调整防火墙默认设置
修改防火墙的默认准入策略为允许,并保持防火墙设置。(生产环境下最好针对单个接口进行准入准出设置)。

修改linux机器的hosts文件,将本机名称和ip进行映射(如果是集群,需要映射其他机器)
vim /etc/hosts

测试是否能ping

Hadoop2.7.3安装
准备软件:复制hadoop-2.7.3.tar.gz的软件到linux的/opt/下。
将上传的hadoop压缩文件解压到/bigdata/中:tar -zxvf hadoop-2.7.3.tar.gz -C
重命名hadoop-2.7.3文件为hadoop
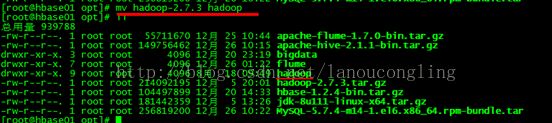
修改配置文件(hadoop2.x的配置文件路径进行了调整:
/hadoop/hadoop-2.7.3/etc/hadoop/)
配置hadoop-env.sh

配置core-site.xml
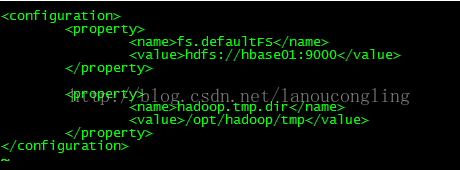
其中,tmp.dir指定的目录不需要手工创建,format名称节点的时候会自动创建(创建的是name相关的)。
配置hdfs-site.xml
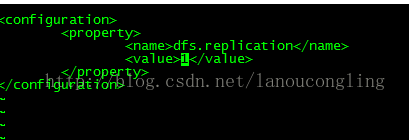
该文件这里了只配置了一个参数,用来指定datanode数据副本的备份个数。
配置mapred-site.xml
该文件默认不存在,但是存在一个mapred-site.template文件,将该文件命名为mapred-site.xml.修改命名后的文件的内容如下:
![]()
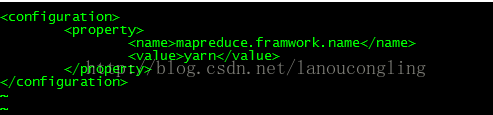
配置yarn-site.xml
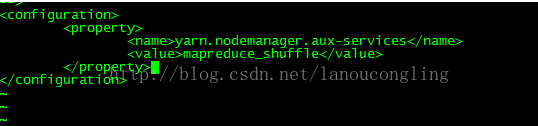
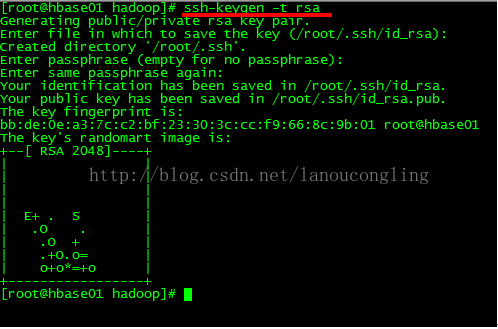
配置root到本机的免登录。
ssh-keygen -trsa生成公钥和私钥
ssh-copy-idpseudohadoop将公钥复制给本机(localhost也行)
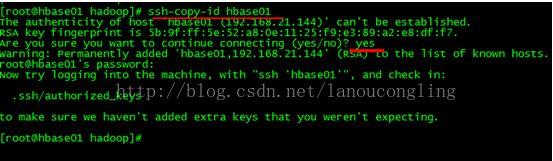
测试ssh localhost直接登录成功。
格式化和启动
由于没有添加hadoop相关的环境变量,以下操作必须处于hadoop的根目录下。
格式化namenode

启动hdfs

启动yarn

测试是否启动成功(jps)
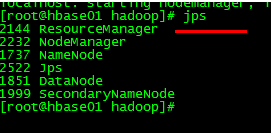
四、安装hive2.1.1
上传apache-hive-2.1.1-bin.tar.gz到linux的/opt目录下。
解压apache-hive-2.1.1-bin.tar.gz到当前文件夹:tar -zxvfapache-hive-2.1.1-bin.tar.gz
并重命名为hive

添加hive的环境变量到/etc/profile中:
在最后追加如下内容:
![]()
生效环境变量:source /etc/profile
修改配置
hive-env.sh
进入到hive的conf目录,cp hive-env.sh.template hive-env.sh
hive-env.sh
头部添加:export JAVA_HOME=/usr/java
修改HADOOP_HOME和HIVE_CONF_DIR
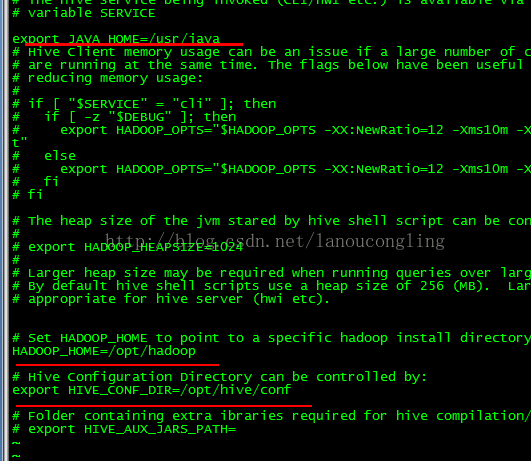
hive-site.xml
进入hive的conf目录,复制一个hive-site.xml文件出来:cp hive-default.xml.template hive-site.xml
vi hive-site.xml,尾行模式执行:18,$-1d 删除18到倒数第二行(显示行号尾行模式使用set nu)
在configuration之间添加如下内容(可根据自己的需要调整配置):
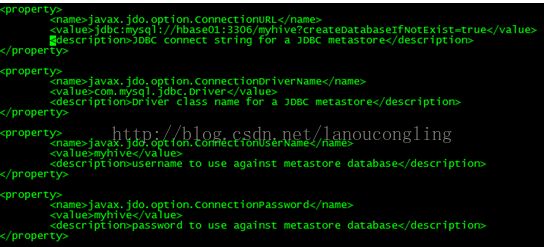
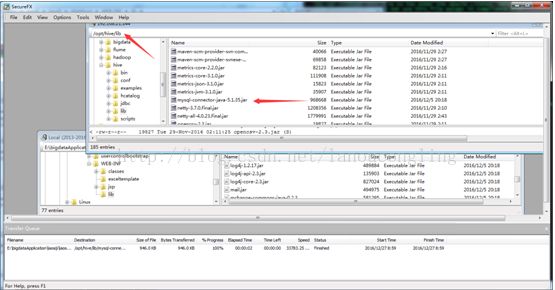
由于hive使用mysql作为元数据仓库,通过jdbc的方式进行连接,那么需要使用jdbc的jar包,复制相应版本的jdbc驱动包到$HIVE_HOME/lib目录下(该方式假设当前目录存在mysql驱动包):cp mysql-connector-java-5.1.35.jar $HIVE_HOME/lib
格式化元数据仓库(从hive2.0之后都要显示格式化元数据):
schematool -dbType mysql -initSchema

上边提示slf4j冲突,这里可以不处理,也可以删除hive下边的那一个(不能删除hadoop那个,因为hive使用了hadoop而hadoop没有使用hive,删除了hadoop的之后,hadoop就无法启动)。
rm -rf $HIVE_HOME/lib/log4j-slf4j-impl-2.4.1.jar
![]()
启动hdfs和yarn:$HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh(在这之前已经启动和yarn)
运行$HIVE_HOME/bin/hive 显示如下界面:

执行:show databases;

五、Hive启动hwi
默认hive不带hwi需要自己源代码编译。
解压源代码tar zxvfapache-hive-2.1.1-src.tar.gz
cd/opt/apache-hive-2.1.1-src/hwi/web/在该文件夹下执行:zip hive-hwi-2.1.1.zip ./*
cp hive-hwi-2.1.1.zip/opt/
修改hive-hwi-2.1.1.zip的扩展名为war:mv hive-hwi-2.1.1.zip hive-hwi-2.1.1.war

移动该文件到hive的lib目录中:mv hive-hwi-2.1.1.war/opt/hive/lib/
移动jdk的tools到hive的lib目录下:cp /usr/java/lib/tools.jar/opt/hive/lib/
![]()
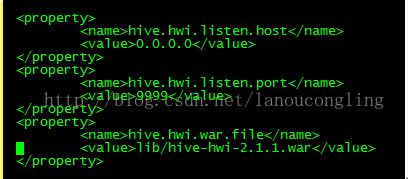
进入cd /opt/hive/conf编辑vi hive-site.xml
Ant的安装
导入jar包
解压
tar-zxvf apache-ant-1.9.7-bin.tar.gz
配置环境变量和path
vi /etc/prifile

环境变量生效
![]()
测试
http://hbase01:9999/hwi
如果访问失败,可以查看9999默认的访问端口是否打开
查看:netstat-ant | grep 9999
打开:hive --service hwi >/dev/null 2>&1 &

如果访问失败,可以多刷新几次;9999默认的访问端口,如果需要修改可以在hive-site.xml中进行。
此时就可以操作hive了