k8s安装prometheus-operator问题处理记录
一、环境
1.系统:centos7
2.kubernetes version:1.6.2
3.网络使用 calico
4. 安装prometheus-operator 0.11.3版本
二、问题
1. 网络问题
简单描述:安装完prometheus-operator 后,所有容器已经启动,但是ping不通grafana。不能正常访问grafana
断定问题: calicoctl get workloadendpoint没有grafana的集群IP(172.16.63.172)信息
(1)问题排查
查看k8s状态
[root@docker225 ~]# kubectl get pods -o wide -n monitoring
NAME READY STATUS RESTARTS AGE IP NODE
alertmanager-main-0 2/2 Running 0 1y 172.16.63.164 192.168.14.225
alertmanager-main-1 2/2 Running 0 16h 172.16.63.173 192.168.14.225
alertmanager-main-2 2/2 Running 0 16h 172.16.63.174 192.168.14.225
grafana-1482444427-c75ts 2/2 Running 0 1y 172.16.63.172 192.168.14.225
kube-state-metrics-1587421894-hs01m 1/1 Running 0 1y 172.16.63.165 192.168.14.225
node-exporter-zbf01 1/1 Running 0 1y 192.168.14.225 192.168.14.225
prometheus-k8s-0 2/2 Running 0 1y 172.16.63.163 192.168.14.225
prometheus-k8s-1 2/2 Running 0 16h 172.16.63.175 192.168.14.225
prometheus-operator-277826456-q7t8h 1/1 Running 2 1y 172.16.63.166 192.168.14.225
查看services
[root@docker225 ~]# kubectl get svc -n monitoring
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main 10.254.197.166 9093:30903/TCP 1y
alertmanager-operated None 9093/TCP,6783/TCP 1y
grafana 10.254.213.82 3000:30902/TCP 1y
kube-state-metrics 10.254.59.234 8080/TCP 1y
node-exporter None 9100/TCP 1y
prometheus-k8s 10.254.219.93 9090:30900/TCP 1y
prometheus-operated None 9090/TCP 1y
prometheus-operator 10.254.191.143 8080/TCP 1y
查看ip
grafana-1482444427-c75ts 2/2 Running 0 1y 172.16.63.172 192.168.14.225
grafana 10.254.213.82 3000:30902/TCP 1y
问题:
访问http://192.168.14.225:30902失败,因为172.16.63.172 访问不通
-
在master节点ping 172.16.63.172
[root@docker225 ~]# ping 172.16.63.172 connect: Network is unreachable kubectl get pods -o wide --all-namespaces -
主要断定错误
calicoctl get workloadendpoint
下面没有grafana-1482444427-c75ts相关信息[root@docker225 ~]# calicoctl get workloadendpoint NODE ORCHESTRATOR WORKLOAD NAME docker225 k8s app-test1.app-test4-service1-4-4-3832218445-jm9vz eth0 docker225 k8s default.prometheus-operator-277826456-txw91 eth0 docker225 k8s kube-system.heapster-v1.3.0-2713982671-0n9bm eth0 docker225 k8s kube-system.kube-dns-3412393464-2hrk2 eth0 docker225 k8s kube-system.monitoring-influxdb-grafana-v4-dz9wj eth0 docker225 k8s monitoring.alertmanager-main-0 eth0 docker225 k8s monitoring.alertmanager-main-1 eth0 docker225 k8s monitoring.alertmanager-main-2 eth0 docker225 k8s monitoring.kube-state-metrics-1587421894-hs01m eth0 docker225 k8s monitoring.prometheus-k8s-0 eth0 docker225 k8s monitoring.prometheus-k8s-1 eth0 docker225 k8s monitoring.prometheus-operator-277826456-q7t8h eth0 -
在容器内没有ifconfig命令
kubectl exec -it grafana-1482444427-c75ts -n monitoring sh登录[root@docker225 kube-prometheus]# kubectl exec -it grafana-1482444427-c75ts -n monitoring sh Defaulting container name to grafana. Use 'kubectl describe pod/grafana-1482444427-c75ts' to see all of the containers in this pod. # ifconfig sh: 1: ifconfig: not found -
参考查看
ip route,没有172.16.63.172相关信息[root@docker225 ~]# ip route default via 192.168.14.1 dev eno16777736 proto static metric 100 blackhole 172.16.63.128/26 proto bird 172.16.63.163 dev calid75abf4f5e0 scope link 172.16.63.164 dev cali11239f98883 scope link 172.16.63.165 dev cali6023fc95ae3 scope link 172.16.63.166 dev cali7071edc8f29 scope link 172.16.63.167 dev cali4b6e0fbac0b scope link 172.16.63.168 dev caliaa714b4436c scope link 172.16.63.169 dev cali9e4b965a8fa scope link 172.16.63.170 dev calicdafc5613c9 scope link 172.16.63.171 dev cali95761c45089 scope link 172.16.63.173 dev cali8bac6c0ff3f scope link 172.16.63.174 dev cali15c7619fccc scope link 172.16.63.175 dev cali1abad8afd57 scope link 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 192.168.14.0/24 dev eno16777736 proto kernel scope link src 192.168.14.225 metric 100 [root@docker225 ~]#
参考
Kubernetes主机间curl cluster ip时不通
(2)解决方法
删除原来的grafana之后重装即可。推断是k8s安装时出错
cd prometheus-operator-0.11.3/contrib/kube-prometheus
#删除相关k8s内容
kubectl -n monitoring delete -f manifests/grafana/
#重新应用
kubectl -n monitoring apply -f manifests/grafana/
查看pod的网络,monitoring.grafana-1482444427-wp5nz为对应的k8s名称
[root@docker225 kube-prometheus]# calicoctl get workloadendpoint --workload=monitoring.grafana-1482444427-wp5nz
NODE ORCHESTRATOR WORKLOAD NAME
docker225 k8s monitoring.grafana-1482444427-wp5nz eth0
[root@docker225 kube-prometheus]# calicoctl get workloadendpoint
NODE ORCHESTRATOR WORKLOAD NAME
docker225 k8s app-test1.app-test4-service1-4-4-3832218445-jm9vz eth0
docker225 k8s default.prometheus-operator-277826456-txw91 eth0
docker225 k8s kube-system.heapster-v1.3.0-2713982671-0n9bm eth0
docker225 k8s kube-system.kube-dns-3412393464-2hrk2 eth0
docker225 k8s kube-system.monitoring-influxdb-grafana-v4-dz9wj eth0
docker225 k8s monitoring.alertmanager-main-0 eth0
docker225 k8s monitoring.alertmanager-main-1 eth0
docker225 k8s monitoring.alertmanager-main-2 eth0
docker225 k8s monitoring.grafana-1482444427-wp5nz eth0
docker225 k8s monitoring.kube-state-metrics-1587421894-hs01m eth0
docker225 k8s monitoring.prometheus-k8s-0 eth0
docker225 k8s monitoring.prometheus-k8s-1 eth0
docker225 k8s monitoring.prometheus-operator-277826456-q7t8h eth0
访问到grafana
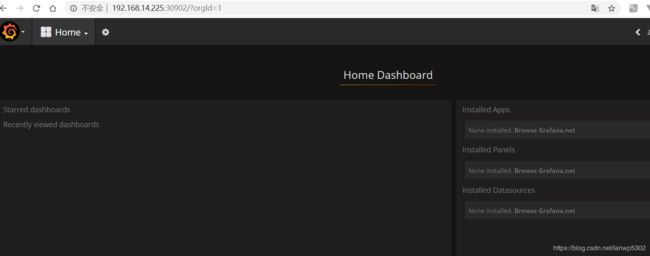
用到的命令
查看指定空间的svc
kubectl get svc -n monitoring
如果没有加空间则查看默认空间default下的信息
kubectl get svc
查看所有空间
kubectl get svc --all-namespaces
查看pod信息
kubectl get pod[s] -n monitoring
查看pod错误
kubectl [-n monitoring] describe pod [pod_name没有指定pod_name则查看空间下所有]
kubectl describe pod [-n monitoring]
2.集群node节点连接不正常
问题描述
由于k8s master主机重启后导致,node节点 status为 node为NoReady状态。导致prometheus安装时不能正常
[root@docker176 ~]# kubectl get node
NAME STATUS AGE VERSION
192.168.14.175 Ready 7d v1.6.2
192.168.14.176 Ready 1h v1.6.2
修复方式
kubelet安装在物理机上,执行systemctl restart kubelet重新启动node节点即可
如果 kubectl get node为非正常状态,则将节点删除之后重启kubelet就可以自动注册到集群中。对应命令
kubectl get node
kubectl delete nodeName
systemctl restart kubelet
查看kubectl -n monitoring get pod,svc 查看状态是否正常running。正常即可查看监控信息
kubectl -n monitoring get pod,svc