彻底搞懂编码ASCII、Unicode、GBK 和 UTF8 、UTF-16、UTF-32编码方式(非常经典)
GBK,ISO-8859-1,GB2312的本质区别
编码有几种 ,计算机最初是在美国等国家发明的 所以表示字符只有简单的几个字母只要对字母进行编码就好 我们标准码 iso-8859-1 这就是一个标准
但是后来计算机普及了 于是就中国要使用计算机了 但是机器不认得中文,于是就有了国际码。 gbk gb2312都是这类。两个其实一个,一个是标准(发布的代号),一个是简称。后来多了个阿拉伯语、日语、韩语......所以就出来统一编码UniCode
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。此字符集主要支持欧洲使用的语言。
GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位,并涵盖了原Unicode中所有的汉字20902,总共收录了883个符号, 21003个汉字及提供了1894个造字码位。Windows 95系统就是以GBK为内码,又由于GBK同时也涵盖了Unicode所有CJK汉字,所以也可以和Unicode做一一对应。
请问URI和URL有什么区别?
URL是全球资源定位符的英文所写,您平时上网时在IE浏览器中输入的那个地址就是URL。比如:网易 http://www.163.com就是一个URL。
URI是Web上可用的每种资源 - HTML文档、图像、视频片段、程序,由一个通过通用资源标志符(Universal Resource Identifier, 简称"URI")进行定位。
URL的格式由下列三部分组成:
第一部分是协议(或称为服务方式);
第二部分是存有该资源的主机IP地址(有时也包括端口号);
第三部分是主机资源的具体地址。
URI一般由三部分组成:
访问资源的命名机制。
存放资源的主机名。
资源自身的名称,由路径表示。
URI 是从虚拟根路径开始的
URL是整个链接
如
URL http://zhidao.baidu.com/question/68016373.html
URI 是/question/68016373.html
常用URL编码表
%0A: linefeed(换行),很多手机url编码后会自动在句末添加%0A,后端会无法识别导致报错,因此需要把它去掉。
%20: space(空格)
只有
字母:a -> z、A -> Z
数字:0 -> 9
特殊符号:$-_.+!*'(),
以及某些保留字,
才可以不经过编码直接用于 URL。
一、问题的由来
URL就是网址,只要上网,就一定会用到。

一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “http://www.abc.com”,但是没有希腊字母的网址“http://www.aβγ.com”(读作阿尔法-贝塔-伽玛.com)。这是 因为网络标准RFC 1738 做了硬性规定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于 URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
下面就让我们看看,“URL编码”到底有多混乱。我会依次分析四种不同的情况,在每一种情况中,浏览器的URL编码方法都不一样。把它们的差异解释 清楚之后,我再说如何用Javascript找到一个统一的编码方法。
二、情况1:网址路径中包含汉字
打开IE(我用的是8.0版),输入网址“http://zh.wikipedia.org/wiki/春节 ”。 注意,“春节”这两个字此时是网址路径的一部分。

![]() 转存失败重新上传取消
转存失败重新上传取消
查看HTTP请求的头信息,会发现IE实际查询的网址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82 ”。 也就是说,IE自动将“春节”编码成了“%E6%98%A5%E8%8A%82”。

我们知道,“春”和“节”的utf-8编码分别是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照顺序,在每个字节前加上%而得到的。(具体的转码方法,请参考我写的《字符编码笔记》 。)
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
三、情况2:查询字符串包含汉字
在IE中输入网址“http://www.baidu.com/s?wd=春节 ”。注意,“春节”这两个字此时 属于查询字符串,不属于网址路径,不要与情况1混淆。

查看HTTP请求的头信息,会发现IE将“春节”转化成了一个乱码。
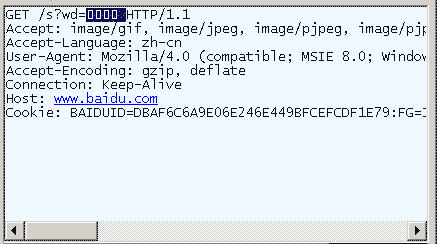
![]() 转存失败重新上传取消
转存失败重新上传取消
切换到十六进制方式,才能清楚地看到,“春节”被转成了“B4 BA BD DA”。
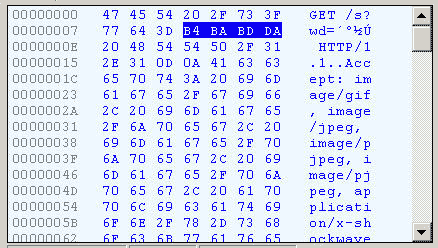
我们知道,“春”和“节”的GB2312编码(我的操作系统“Windows XP”中文版的默认编码)分别是“B4 BA”和“BD DA”。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。
Firefox的处理方法,略有不同。它发送的HTTP Head是“wd=%B4%BA%BD%DA”。也就是说,同样采用GB2312编码,但是在每个字节前加上了%。
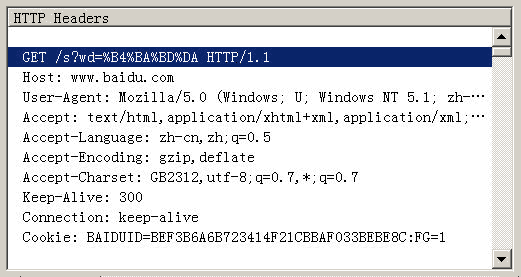
所以,结论2就是,查询字符串的编码,用的是操作系统的默认编码。
四、情况3:Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验 ,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。

Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。

所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
五、情况4:Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的 文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是“春节”这两个字
http_request.open('GET', url, true);
那么,无论网页使用什么字符集,IE传送给服务器的总是“q=%B4%BA%BD%DA”,而Firefox传送给服务器的总是“q=%E6%98 %A5%E8%8A%82”。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是 采用utf-8编码。这就是我们的结论4。
六、Javascript函数:escape()
好了,到此为止,四种情况都说完了。
假定前面你都看懂了,那么此时你应该会感到很头痛。因为,实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结 果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致 的,所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因, 很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果 是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在/u0000到/u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是 unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。

![]() 转存失败重新上传取消
转存失败重新上传取消
还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出, 默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处 理成空格。所以,使用的时候要小心。
七、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。

它对应的解码函数是decodeURI()。

![]() 转存失败重新上传取消
转存失败重新上传取消
需要注意的是,它不对单引号'编码。
八、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分 进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。

它对应的解码函数是decodeURIComponent()。
PS1 :
网页里的form编码其实不完全取决于网页编码,form标记中有一个accept-charset属性,在非ie浏览器种,如果将其赋值(比如 accept-charset="UTF-8"),则表单会按照这个值表示的编码方式进行提交。
在ie下,我的兼容解决办法是:
form1.οnsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
一、编码历史与区别
一直对字符的各种编码方式懵懵懂懂,什么ANSI UNICODE UTF-8 GB2312 GBK DBCS UCS……是不是看的很晕,假如您细细的阅读本文你一定可以清晰的理解他们。Let's go!
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为"字节"。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为"计算机"。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。遇上00x10, 终端就换行,遇上0x07, 终端就向人们嘟嘟叫,例好遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0x20以下的字节状态称为"控制码"。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的"Ascii"编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集"。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 "GB2312"。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 "DBCS"(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍:
"一个汉字算两个英文字符!一个汉字算两个英文字符……"
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显示汉字,就必须装上一个"汉字系统",专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么"倚天汉字系统"才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办?
真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了——一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称 "UNICODE"。
UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ascii里的那些“半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于"半角"英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的strlen函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从 UNICODE 开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的"一个字符"!同时,也都是统一的"两个字节",请注意"字符"和"字节"两个术语的不同,“字节”是一个8位的物理存贮单元,而“字符”则是一个文化相关的符号。在UNICODE 中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
作者自己添加,这里要注意了,这里就出现了,
宽窄字符是与一个字符所占的字节数有关,如果
一个字符只占一个字节,那么那么它就是窄字符,一个宽字符通常占2个字节。在c/c++/objective c
中,如果你想把一个窄字符(例如ASCII 字符)表示为宽字符通常的做法是使用wchar来取代char,例如
wchar t = 'A';
wchar_t * p = L"Hello!" ;
这里每一个字符都占了2个字节,并且采用了unicode编码。
从前多种字符集存在时,那些做多语言软件的公司遇上过很大麻烦,他们为了在不同的国家销售同一套软件,就不得不在区域化软件时也加持那个双字节字符集咒语,不仅要处处小心不要搞错,还要把软件中的文字在不同的字符集中转来转去。UNICODE 对于他们来说是一个很好的一揽子解决方案,于是从 Windows NT 开始,MS 趁机把它们的操作系统改了一遍,把所有的核心代码都改成了用 UNICODE 方式工作的版本,从这时开始,WINDOWS 系统终于无需要加装各种本土语言系统,就可以显示全世界上所有文化的字符了。
但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。
如前所述,UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。如果还不够也没有关系,ISO已经准备了UCS-4方案,说简单了就是四个字节来表示一个字符,这样我们就可以组合出21亿个不同的字符出来(最高位有其他用途),这大概可以用到银河联邦成立那一天吧!
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到UTF时并不是直接的对应,而是要过一些算法和规则来转换。
受到过网络编程加持的计算机僧侣们都知道,在网络里传递信息时有一个很重要的问题,就是对于数据高低位的解读方式,一些计算机是采用低位先发送的方法,例如我们PC机采用的 INTEL 架构,而另一些是采用高位先发送的方式,在网络中交换数据时,为了核对双方对于高低位的认识是否是一致的,采用了一种很简便的方法,就是在文本流的开始时向对方发送一个标志符——如果之后的文本是高位在位,那就发送"FEFF",反之,则发送"FFFE"。不信你可以用二进制方式打开一个UTF-X格式的文件,看看开头两个字节是不是这两个字节?
讲到这里,我们再顺便说说一个很著名的奇怪现象:当你在 windows 的记事本里新建一个文件,输入"联通"两个字之后,保存,关闭,然后再次打开,你会发现这两个字已经消失了,代之的是几个乱码!呵呵,有人说这就是联通之所以拼不过移动的原因。
其实这是因为GB2312编码与UTF8编码产生了编码冲撞的原因。
从网上引来一段从UNICODE到UTF8的转换规则:
Unicode
UTF-8
0000 - 007F
0xxxxxxx
0080 - 07FF
110xxxxx 10xxxxxx
0800 - FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如"汉"字的Unicode编码是6C49。6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是其UTF8的编码。
而当你新建一个文本文件时,记事本的编码默认是ANSI, 如果你在ANSI的编码输入汉字,那么他实际就是GB系列的编码方式,在这种编码下,"联通"的内码是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了吗?第一二个字节、第三四个字节的起始部分的都是"110"和"10",正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节的10去掉,我们就得到了"00001 101010",再把各位对齐,补上前导的0,就得到了"0000 0000 0110 1010",不好意思,这是UNICODE的006A,也就是小写的字母"j",而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。这就是只有"联通"两个字的文件没有办法在记事本里正常显示的原因。
而如果你在"联通"之后多输入几个字,其他的字的编码不见得又恰好是110和10开始的字节,这样再次打开时,记事本就不会坚持这是一个utf8编码的文件,而会用ANSI的方式解读之,这时乱码又不出现了。
好了,终于可以回答NICO的问题了,在数据库里,有n前缀的字串类型就是UNICODE类型,这种类型中,固定用两个字节来表示一个字符,无论这个字符是汉字还是英文字母,或是别的么。
如果你要测试"abc汉字"这个串的长度,在没有n前缀的数据类型里,这个字串是7个字符的长度,因为一个汉字相当于两个字符。而在有n前缀的数据类型里,同样的测试串长度的函数将会告诉你是5个字符,因为一个汉字就是一个字符。
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3.Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例,演示如何实现UTF-8编码。
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
6. Unicode与UTF-8之间的转换
通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序Notepad.exe。打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条。
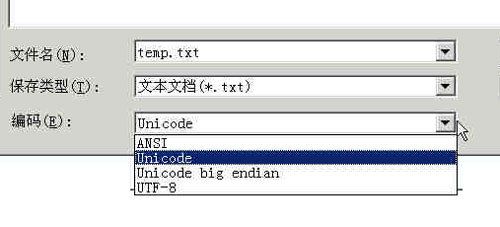
里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
3)Unicode big endian编码与上一个选项相对应。我在下一节会解释little endian和big endian的涵义。
4)UTF-8编码,也就是上一节谈到的编码方法。
选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。
7. Little endian和Big endian
上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是”大头方式“(Big endian),第二个字节在前就是”小头方式“(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
8. 实例
下面,举一个实例。
打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit中的”十六进制功能“,观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的。
2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25。
3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储。
4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的。
二、编码转换
/** 中文字符串转UTF-8与GBK码示例
*/
public static void tttt() throws Exception {
String old = "手机银行";
//中文转换成UTF-8编码(16进制字符串)
StringBuffer utf8Str = new StringBuffer();
byte[] utf8Decode = old.getBytes("utf-8");
for (byte b : utf8Decode) {
utf8Str.append(Integer.toHexString(b & 0xFF));
}
// utf8Str.toString()=====e6898be69cbae993b6e8a18c
// System.out.println("UTF-8字符串e6898be69cbae993b6e8a18c转换成中文值======" + new String(utf8Decode, "utf-8"));//-------手机银行
//中文转换成GBK码(16进制字符串)
StringBuffer gbkStr = new StringBuffer();
byte[] gbkDecode = old.getBytes("gbk");
for (byte b : gbkDecode) {
gbkStr.append(Integer.toHexString(b & 0xFF));
}
// gbkStr.toString()=====cad6bbfad2f8d0d0
// System.out.println("GBK字符串cad6bbfad2f8d0d0转换成中文值======" + new String(gbkDecode, "gbk"));//----------手机银行
//16进制字符串转换成中文
byte[] bb = HexString2Bytes(gbkStr.toString());
bb = HexString2Bytes("CAD6BBFAD2F8D0D0000000000000000000000000");
byte[] cc = hexToByte("CAD6BBFAD2F8D0D0000000000000000000000000", 20);
String aa = new String(bb, "gbk");
System.out.println("aa====" + aa);
} /**
* 把16进制字符串转换成字节数组
* @param hexstr
* @return
*/
public static byte[] HexString2Bytes(String hexstr) {
byte[] b = new byte[hexstr.length() / 2];
int j = 0;
for (int i = 0; i < b.length; i++) {
char c0 = hexstr.charAt(j++);
char c1 = hexstr.charAt(j++);
b[i] = (byte) ((parse(c0) << 4) | parse(c1));
}
return b;
}
private static int parse(char c) {
if (c >= 'a')
return (c - 'a' + 10) & 0x0f;
if (c >= 'A')
return (c - 'A' + 10) & 0x0f;
return (c - '0') & 0x0f;
}
参考链接:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
参考链接:https://blog.csdn.net/zhanghuaichao/article/details/77862037
参考链接:https://blog.csdn.net/m0_37556444/article/details/83002947
参考链接:https://www.cnblogs.com/icooper/p/4583684.html
参考链接:http://www.doc88.com/p-3347645600298.html
参考链接:https://www.cnblogs.com/yingsong/p/8884692.html
汉字编码之GBK编码之概念
BK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年12月15日正式发布,这一版的GBK规范为1.0版。
一、字汇
GBK 规范收录了 ISO 10646.1 中的全部 CJK 汉字和符号,并有所补充。具体包括:
1. GB 2312 中的全部汉字、非汉字符号。
2. GB 13000.1 中的其他 CJK 汉字。以上合计 20902 个 GB 化汉字。
3. 《简化字总表》中未收入 GB 13000.1 的 52 个汉字。
4. 《康熙字典》及《辞海》中未收入 GB 13000.1 的 28 个部首及重要构件。
5. 13 个汉字结构符。
6. BIG-5 中未被 GB 2312 收入、但存在于 GB 13000.1 中的 139 个图形符号。
7. GB 12345 增补的 6 个拼音符号。
8. 汉字“〇”。
9. GB 12345 增补的 19 个竖排标点符号(GB 12345 较 GB 2312 增补竖排标点符号 29 个,其中 10 个未被 GB 13000.1 收入,故 GBK 亦不收)。
10. 从 GB 13000.1 的 CJK 兼容区挑选出的 21 个汉字。
11. GB 13000.1 收入的 31 个 IBM OS/2 专用符号。
12.未录入《新华字典》上的一些字,如“韡”的简体。
二、码位分配及顺序
GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。
全部编码分为三大部分:
1. 汉字区。包括:
a. GB 2312 汉字区。即 GBK/2: B0A1-F7FE。收录 GB 2312 汉字 6763 个,按原顺序排列。
b. GB 13000.1 扩充汉字区。包括:
(1) GBK/3: 8140-A0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
(2) GBK/4: AA40-FEA0。收录 CJK 汉字和增补的汉字 8160 个。CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。
(3) 汉字“〇”安排在图形符号区GBK/5:A996。
2. 图形符号区。包括:
a. GB 2312 非汉字符号区。即 GBK/1: A1A1-A9FE。其中除 GB 2312 的符号外,还有 10 个小写罗马数字和 GB 12345 增补的符号。计符号 717 个。
b. GB 13000.1 扩充非汉字区。即 GBK/5: A840-A9A0。BIG-5 非汉字符号、结构符和“〇”排列在此区。计符号 166 个。
3. 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
三、字形
GBK 对字形作了如下的规定:
1. 原则上与 GB 13000.1 G列(即源自中国大陆法定标准的汉字)下的字形/笔形保持一致。
2. 在 CJK 汉字认同规则的总框架内,对所有的 GBK 编码汉字实施“无重码正形”(“GB 化”);即在不造成重码的前提下,尽量采用中国新字形。
3. 对于超出 CJK 汉字认同规则的、或认同规则尚未明确规定的汉字,在 GBK 码位上暂安放旧字形。这样,在许多情况下 GBK 收入了同一汉字的新旧两种字形。
4. 非汉字符号的字形,凡 GB 2312 已经包括的,与 GB 2312 保持一致;超出 GB 2312 的部分,与 GB 13000.1 保持一致。
5. 带声调的拼音字母取半角形式。
若要查询具体字符的编码请前往:汉字字符集编码查询。
参考链接:https://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php
汉字编码之GBK编码之原理
续字符编码的学习。今天介绍一下GBK(汉字内码扩展规范),GB 2312 GB18030。引用网友的话可以概括一下:
GBK和UTF8的区别:GBK就是在保存你的帖子的时候,一个汉字占用两个字节。。外国人看会出现乱码,此为我中华为自己汉字编码而形成之解决方案。
UTF8就是在保存你的帖子的时候,一个汉字占用3个字节。。但是外国人看的话不会乱码,此为西人为了解决多字节字符而形成之解决方案。
笔者之前写过utf-8的博客【点击】
GBK——专门为解决汉字的编码而生成的解决方案。
那么,一个汉字究竟被存储为什么,就需要:先查unicode码表,然后根据在码表的位置进行计算。例如:“电”字,在码表中是3575,计算成utf8就是E794B5,而在GB2312的码表中为B5E7。
GBK的中文编码是双字节来表示的,英文编码是用ASC||码表示的,既用单字节表示。但GBK编码表中也有英文字符的双字节表示形式,所以英文字母可以有2种GBK表示方式。为区分中文,将其最高位都定成1。英文单字节最高位都为0。当用GBK解码时,若高字节最高位为0,则用ASC||码表解码;若高字节最高位为1,则用GBK编码表解码。
编码方式:
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。具体来说,定义的是下列字节:
GBK的编码范围
双字节符号可以表达的64K空间如下图所示。绿色和黄色区域是GBK的编码,红色是用户定义区域。没有颜色区域是不正确的代码组合:

要点总结
GBK编码是GB2312编码的超集,向下完全兼容GB2312。
GB18030编码向下兼容GBK和GB2312,
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换。
GBK,GB2312以及Unicode都既是字符集,也是编码方式,而UTF-8只是编码方式,并不是字符集
参考技术博客【点击】
GBK 码表 【点击转载处】
参考链接:https://blog.csdn.net/hherima/article/details/50801360
关于 GBK编码表与编码字库
GBK编码的单字节与双字节
gbk编码分两部分,一部分是单字节编码,另一部分是双字节编码。
gbk编码中,前128个编码都是单字节编码。单字节编码从00-7F,与ASCII相对应。
在单字节编码之后就是双字节编码。第一个字节范围是81-FE。第二字节的一部分领域在40–7E,其他领域在80–FE。
这样可以通过第一个字节就可以判断是单字节编码还是双字节编码。
详细内容:https://yq.aliyun.com/articles/27446
GBK 编码所有文字:http://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php
参考链接:https://blog.csdn.net/weixin_42056745/article/details/80066348
在UTF-8中,一个汉字为什么需要三个字节?
UNICODE是万能编码,包含了所有符号的编码,它规定了所有符号在计算机底层的二进制的表示顺序。有关Unicode为什么会出现就不叙述了,Unicode是针对所有计算机的使用者定义一套统一的编码规范,这样计算机使用者就避免了编码转换的问题。Unicode定义了所有符号的二进制形式,也就是符号如何在计算机内部存储的,而且每个符号规定都必须使用两个字节来表示,也就是用16位二进制去代表一个符号,这样就导致了一个问题,英文编码的空间浪费,因为在ANSI中的符号都是一个字节来表示的,而使用了UNICODE编码就白白浪费了一个字节。也就代表着Unicode需要使用两倍的空间去存储相应的ANSI编码下的符号。虽然现在硬盘或者内存都很廉价,但是在网络传输中,这个问题就凸显出来了,你可以这样想想,本来1M的带宽在ANSI下可以代表1024*1024个字符,但是在Unicode下却只能代表1024*1024/2个字符。也就是1MB/s的带宽只能等价于512KB/s,这个很可怕啊。所以为了解决符号在网络中传输的浪费问题,就出现了UTF-8编码,Unicode transfer format -8 ,后面的8代表是以8位二进制为单位来传输符号的,但是这样又导致了一个问题,虽然UTF-8可以使用一个字节来表示ANSI下的符号,但是对于其它类似汉语的符号,得需要两个字节来表示,所以计算机不知道如何去截取一个符号,也就是一个符号对应的二进制的截取开始位置和截取结束位置。所以为了解决Unicode下的ANSI符号的空间浪费和网络传输下如何截取字符的问题,UTF规定:如果一个符号只占一个字节,那么这个8位字节的第一位就为0。如果为两个字节,那么规定第一个字节的前两位都为1,然后第一个字节的第三位为0,第二个字节的前两位为10,然后如果是三个字节的话,那么第一个字节的前三位为111,第四位为0,剩余的两个字节的前两位都为10。按照这样的算法去思考一个中文字符的UTF-8是怎么表示的:一个中文字符需要两个字节来表示,两个字节一共是16位,那么UTF-8下,两个字节是不够的,因为两个字节下,第一个字节已经占据了三位:110,然后剩余的一个字节占据了两位:10,现在就只剩下11位,与Unicode下的两个字节,16位去表示任意一个字符是相悖的。所以就使用三个字节去表示非ANSI字符:三个字节下,一共是24位,第一个字节头四位是:1110,后两个字节的前两位都是:10,那么24位-8位=16位,刚好两个字节去表示Unicode下的任意一个非ANSI字符。这也就是为什么UTF-8需要使用三个字节去表示一个非ANSI字符的原因了!
题外话:中国的汉字多达10多万,常用的汉字3500左右[08年统计],如果用3个字节来表示,一共只有2^16(65535)种可能,不足以表示10多万的汉字。所以中日韩的超大字符集是采用的4个字节来表示的,多达6万多个。但是平时使用超大字符集的概率0.01%都不到。所以我们一般认为日常的中文在UTF-8中占三个字节 即可!
多个字节提供的位数超过了所需要的,多余的位以0补全到编码前面
参考链接:https://www.cnblogs.com/web21/p/6092414.html
附录:unicode编码表对应的语言
| 编号 | 字符编码名称 | 编码起始十进制 | 编码范围十六进制 | 字符编码名称 |
| 1 | Latin-1 Supplement | 128 | U+0080 ... U+00FF | 拉丁语-1增补 |
| 2 | Latin Extended-A | 256 | U+0100 ... U+017F | 拉丁文扩展 |
| 3 | Latin Extended-B | 384 | U+0180 ... U+024F | 拉丁文扩展 |
| 4 | IPA Extensions | 592 | U+0250 ... U+02AF | 国际音标扩展 |
| 5 | Spacing Modifier Letters | 688 | U+02B0 ... U+02FF | 修饰字母 |
| 6 | Combining Diacritical Marks | 768 | U+0300 ... U+036F | 组合用附加符号 |
| 7 | Greek and Coptic | 880 | U+0370 ... U+03FF | 希腊文及科普特文 |
| 8 | Cyrillic | 1024 | U+0400 ... U+04FF | 西里尔文 |
| 9 | Cyrillic Supplement | 1280 | U+0500 ... U+052F | 西里尔字母补充 |
| 10 | Armenian | 1328 | U+0530 ... U+058F | 亚美尼亚语 |
| 11 | Hebrew | 1424 | U+0590 ... U+05FF | 希伯来语 |
| 12 | Arabic | 1536 | U+0600 ... U+06FF | 阿拉伯语的 |
| 13 | Syriac | 1792 | U+0700 ... U+074F | 叙利亚 |
| 14 | Arabic Supplement | 1872 | U+0750 ... U+077F | 阿拉伯文补充 |
| 15 | Thaana | 1920 | U+0780 ... U+07BF | 塔安那文 |
| 16 | NKo | 1984 | U+07C0 ... U+07FF | 恩科 |
| 17 | Samaritan | 2048 | U+0800 ... U+083F | 撒玛利亚人 |
| 18 | Mandaic | 2112 | U+0840 ... U+085F | 曼达克语 |
| 19 | Syriac Supplement | 2144 | U+0860 ... U+086F | 叙利亚文增补 |
| 20 | Arabic Extended-A | 2208 | U+08A0 ... U+08FF | 阿拉伯语扩充-A |
| 21 | Devanagari | 2304 | U+0900 ... U+097F | 天成文书(梵文) |
| 22 | Bengali | 2432 | U+0980 ... U+09FF | 孟加拉文 |
| 23 | Gurmukhi | 2560 | U+0A00 ... U+0A7F | 锡克教 |
| 24 | Gujarati | 2688 | U+0A80 ... U+0AFF | 古吉拉特语 |
| 25 | Oriya | 2816 | U+0B00 ... U+0B7F | 奥里亚 |
| 26 | Tamil | 2944 | U+0B80 ... U+0BFF | 泰米尔人 |
| 27 | Telugu | 3072 | U+0C00 ... U+0C7F | 泰卢古 |
| 28 | Kannada | 3200 | U+0C80 ... U+0CFF | 卡纳达语 |
| 29 | Malayalam | 3328 | U+0D00 ... U+0D7F | 马拉雅拉姆语 |
| 30 | Sinhala | 3456 | U+0D80 ... U+0DFF | 僧伽罗 |
| 31 | Thai | 3584 | U+0E00 ... U+0E7F | 泰国人 |
| 32 | Lao | 3712 | U+0E80 ... U+0EFF | 老 |
| 33 | Tibetan | 3840 | U+0F00 ... U+0FFF | 藏语 |
| 34 | Myanmar | 4096 | U+1000 ... U+109F | 缅甸 |
| 35 | Georgian | 4256 | U+10A0 ... U+10FF | 格鲁吉亚语 |
| 36 | Hangul Jamo | 4352 | U+1100 ... U+11FF | 谚文字母 |
| 37 | Ethiopic | 4608 | U+1200 ... U+137F | 埃塞俄比亚语 |
| 38 | Ethiopic Supplement | 4992 | U+1380 ... U+139F | 埃塞俄比亚语补充 |
| 39 | Cherokee | 5024 | U+13A0 ... U+13FF | 切罗基 |
| 40 | Unified Canadian Aboriginal Syllabics | 5120 | U+1400 ... U+167F | 统一加拿大土著语音节 |
| 41 | Ogham | 5760 | U+1680 ... U+169F | 奥格姆 |
| 42 | Runic | 5792 | U+16A0 ... U+16FF | 符尼克 |
| 43 | Tagalog | 5888 | U+1700 ... U+171F | 塔加洛 |
| 44 | Hanunoo | 5920 | U+1720 ... U+173F | 汉努诺奥人 |
| 45 | Buhid | 5952 | U+1740 ... U+175F | 布希德文 |
| 46 | Tagbanwa | 5984 | U+1760 ... U+177F | 塔格巴努亚文 |
| 47 | Khmer | 6016 | U+1780 ... U+17FF | 高棉 |
| 48 | Mongolian | 6144 | U+1800 ... U+18AF | 蒙古族 |
| 49 | Unified Canadian Aboriginal Syllabics Extended | 6320 | U+18B0 ... U+18FF | 统一加拿大土著印第安方言领音扩展 |
| 50 | Limbu | 6400 | U+1900 ... U+194F | 林布 |
| 51 | Tai Le | 6480 | U+1950 ... U+197F | 泰乐 |
| 52 | New Tai Lue | 6528 | U+1980 ... U+19DF | 新傣仂文 |
| 53 | Khmer Symbols | 6624 | U+19E0 ... U+19FF | 高棉符号 |
| 54 | Buginese | 6656 | U+1A00 ... U+1A1F | 布吉文 |
| 55 | Tai Tham | 6688 | U+1A20 ... U+1AAF | 大泰晤士河 |
| 56 | Combining Diacritical Marks Extended | 6832 | U+1AB0 ... U+1AFF | 组合用扩展音调标记 |
| 57 | Balinese | 6912 | U+1B00 ... U+1B7F | 巴厘语 |
| 58 | Sundanese | 7040 | U+1B80 ... U+1BBF | 圣代人 |
| 59 | Batak | 7104 | U+1BC0 ... U+1BFF | 巴塔克 |
| 60 | Lepcha | 7168 | U+1C00 ... U+1C4F | 莱布查 |
| 61 | Ol Chiki | 7248 | U+1C50 ... U+1C7F | 欧基 |
| 62 | Cyrillic Extended-C | 7296 | U+1C80 ... U+1C8F | 西里尔文扩展-C |
| 63 | Sundanese Supplement | 7360 | U+1CC0 ... U+1CCF | 圣代补充 |
| 64 | Vedic Extensions | 7376 | U+1CD0 ... U+1CFF | 吠陀扩展 |
| 65 | Phonetic Extensions | 7424 | U+1D00 ... U+1D7F | 语音学扩展 |
| 66 | Phonetic Extensions Supplement | 7552 | U+1D80 ... U+1DBF | 语音学扩展补充 |
| 67 | Combining Diacritical Marks Supplement | 7616 | U+1DC0 ... U+1DFF | 组合用附加符号补集 |
| 68 | Latin Extended Additional | 7680 | U+1E00 ... U+1EFF | 拉丁语扩展附加词 |
| 69 | Greek Extended | 7936 | U+1F00 ... U+1FFF | 希腊语扩展 |
| 70 | General Punctuation | 8192 | U+2000 ... U+206F | 常用标点 |
| 71 | Superscripts and Subscripts | 8304 | U+2070 ... U+209F | 上标及下标 |
| 72 | Currency Symbols | 8352 | U+20A0 ... U+20CF | 货币符号 |
| 73 | Combining Diacritical Marks for Symbols | 8400 | U+20D0 ... U+20FF | 符号之组合用附加符号 |
| 74 | Letterlike Symbols | 8448 | U+2100 ... U+214F | 字母式符号 |
| 75 | Number Forms | 8528 | U+2150 ... U+218F | 数字形式 |
| 76 | Arrows | 8592 | U+2190 ... U+21FF | 箭头 |
| 77 | Mathematical Operators | 8704 | U+2200 ... U+22FF | 数学运算符 |
| 78 | Miscellaneous Technical | 8960 | U+2300 ... U+23FF | 杂项工业符号 |
| 79 | Control Pictures | 9216 | U+2400 ... U+243F | 控制图片 |
| 80 | Optical Character Recognition | 9280 | U+2440 ... U+245F | 光学字符识别 |
| 81 | Enclosed Alphanumerics | 9312 | U+2460 ... U+24FF | 封闭式字母数字 |
| 82 | Box Drawing | 9472 | U+2500 ... U+257F | 箱型图 |
| 83 | Block Elements | 9600 | U+2580 ... U+259F | 块元素 |
| 84 | Geometric Shapes | 9632 | U+25A0 ... U+25FF | 几何图形 |
| 85 | Miscellaneous Symbols | 9728 | U+2600 ... U+26FF | 杂项符号 |
| 86 | Dingbats | 9984 | U+2700 ... U+27BF | 丁巴特 |
| 87 | Miscellaneous Mathematical Symbols-A | 10176 | U+27C0 ... U+27EF | 其他数学符号-A |
| 88 | Supplemental Arrows-A | 10224 | U+27F0 ... U+27FF | 补充箭头-A |
| 89 | Braille Patterns | 10240 | U+2800 ... U+28FF | 盲文点字模型 |
| 90 | Supplemental Arrows-B | 10496 | U+2900 ... U+297F | 补充箭头-B |
| 91 | Miscellaneous Mathematical Symbols-B | 10624 | U+2980 ... U+29FF | 其他数学符号-B |
| 92 | Supplemental Mathematical Operators | 10752 | U+2A00 ... U+2AFF | 补充数学运算符 |
| 93 | Miscellaneous Symbols and Arrows | 11008 | U+2B00 ... U+2BFF | 杂项符号和箭头 |
| 94 | Glagolitic | 11264 | U+2C00 ... U+2C5F | 格拉哥里文 |
| 95 | Latin Extended-C | 11360 | U+2C60 ... U+2C7F | 拉丁语扩充-C |
| 96 | Coptic | 11392 | U+2C80 ... U+2CFF | 科普特语的 |
| 97 | Georgian Supplement | 11520 | U+2D00 ... U+2D2F | 格鲁吉亚语补充 |
| 98 | Tifinagh | 11568 | U+2D30 ... U+2D7F | 提非纳文 |
| 99 | Ethiopic Extended | 11648 | U+2D80 ... U+2DDF | 埃塞俄比亚语扩展 |
| 100 | Cyrillic Extended-A | 11744 | U+2DE0 ... U+2DFF | 西里尔文扩充-A |
| 101 | Supplemental Punctuation | 11776 | U+2E00 ... U+2E7F | 追加标点 |
| 102 | CJK Radicals Supplement | 11904 | U+2E80 ... U+2EFF | 中日韩部首补充 |
| 103 | Kangxi Radicals | 12032 | U+2F00 ... U+2FDF | 康熙部首 |
| 104 | Ideographic Description Characters | 12272 | U+2FF0 ... U+2FFF | 表意文字描述符 |
| 105 | CJK Symbols and Punctuation | 12288 | U+3000 ... U+303F | 中日韩符号和标点 |
| 106 | Hiragana | 12352 | U+3040 ... U+309F | 平假名 |
| 107 | Katakana | 12448 | U+30A0 ... U+30FF | 片假名 |
| 108 | Bopomofo | 12544 | U+3100 ... U+312F | 注音符号 |
| 109 | Hangul Compatibility Jamo | 12592 | U+3130 ... U+318F | 朝鲜文兼容字母 |
| 110 | Kanbun | 12688 | U+3190 ... U+319F | 寛文 |
| 111 | Bopomofo Extended | 12704 | U+31A0 ... U+31BF | 注音字母扩展 |
| 112 | CJK Strokes | 12736 | U+31C0 ... U+31EF | CJK笔画 |
| 113 | Katakana Phonetic Extensions | 12784 | U+31F0 ... U+31FF | 日文片假名语音扩展 |
| 114 | Enclosed CJK Letters and Months | 12800 | U+3200 ... U+32FF | 带括号的CJK字母和月份 |
| 115 | CJK Compatibility | 13056 | U+3300 ... U+33FF | CJK兼容 |
| 116 | CJK Unified Ideographs Extension A | 13312 | U+3400 ... U+4DBF | CJK统一汉字扩展A |
| 117 | Yijing Hexagram Symbols | 19904 | U+4DC0 ... U+4DFF | 易经六卦符号 |
| 118 | CJK Unified Ideographs | 19968 | U+4E00 ... U+9FFF | 中日韩统一表意文字 |
| 119 | Yi Syllables | 40960 | U+A000 ... U+A48F | 彝文音节 |
| 120 | Yi Radicals | 42128 | U+A490 ... U+A4CF | 彝文字根 |
| 121 | Lisu | 42192 | U+A4D0 ... U+A4FF | 傈僳族 |
| 122 | Vai | 42240 | U+A500 ... U+A63F | VAI |
| 123 | Cyrillic Extended-B | 42560 | U+A640 ... U+A69F | 西里尔文扩充-B |
| 124 | Bamum | 42656 | U+A6A0 ... U+A6FF | 巴姆 |
| 125 | Modifier Tone Letters | 42752 | U+A700 ... U+A71F | 声调修饰字母 |
| 126 | Latin Extended-D | 42784 | U+A720 ... U+A7FF | 拉丁语扩充D |
| 127 | Syloti Nagri | 43008 | U+A800 ... U+A82F | 塞洛提纳格瑞 |
| 128 | Common Indic Number Forms | 43056 | U+A830 ... U+A83F | 常用的指数形式 |
| 129 | Phags-pa | 43072 | U+A840 ... U+A87F | 八思巴字母 |
| 130 | Saurashtra | 43136 | U+A880 ... U+A8DF | 索拉什特拉 |
| 131 | Devanagari Extended | 43232 | U+A8E0 ... U+A8FF | 天成文书(梵文)扩展 |
| 132 | Kayah Li | 43264 | U+A900 ... U+A92F | 克耶字母 |
| 133 | Rejang | 43312 | U+A930 ... U+A95F | 拉让 |
| 134 | Hangul Jamo Extended-A | 43360 | U+A960 ... U+A97F | 朝鲜文Jamo扩展-A |
| 135 | Javanese | 43392 | U+A980 ... U+A9DF | 爪哇人 |
| 136 | Myanmar Extended-B | 43488 | U+A9E0 ... U+A9FF | 缅甸延伸-B |
| 137 | Cham | 43520 | U+AA00 ... U+AA5F | 查姆 |
| 138 | Myanmar Extended-A | 43616 | U+AA60 ... U+AA7F | 缅甸延伸-A |
| 139 | Tai Viet | 43648 | U+AA80 ... U+AADF | 泰乐 |
| 140 | Meetei Mayek Extensions | 43744 | U+AAE0 ... U+AAFF | Meetei Mayek扩展 |
| 141 | Ethiopic Extended-A | 43776 | U+AB00 ... U+AB2F | 埃塞俄比亚文扩充-A |
| 142 | Latin Extended-E | 43824 | U+AB30 ... U+AB6F | 拉丁语扩充-E |
| 143 | Cherokee Supplement | 43888 | U+AB70 ... U+ABBF | 切罗基补充剂 |
| 144 | Meetei Mayek | 43968 | U+ABC0 ... U+ABFF | 梅耶克会议 |
| 145 | Hangul Syllables | 44032 | U+AC00 ... U+D7AF | 朝鲜文音节 |
| 146 | Hangul Jamo Extended-B | 55216 | U+D7B0 ... U+D7FF | 朝鲜文Jamo扩展-B |
| 147 | High Surrogates | 55296 | U+D800 ... U+DB7F | 高位替代 |
| 148 | High Private Use Surrogates | 56192 | U+DB80 ... U+DBFF | 高位专用替代 |
| 149 | Low Surrogates | 56320 | U+DC00 ... U+DFFF | 低位替代 |
| 150 | Private Use Area | 57344 | U+E000 ... U+F8FF | 私人使用区 |
| 151 | CJK Compatibility Ideographs | 63744 | U+F900 ... U+FAFF | 中日韓相容表意文字 |
| 152 | Alphabetic Presentation Forms | 64256 | U+FB00 ... U+FB4F | 字母表示形式 |
| 153 | Arabic Presentation Forms-A | 64336 | U+FB50 ... U+FDFF | 阿拉伯语变形显现形式-A |
| 154 | Variation Selectors | 65024 | U+FE00 ... U+FE0F | 字型变换选取器 |
| 155 | Vertical Forms | 65040 | U+FE10 ... U+FE1F | 垂直形状 |
| 156 | Combining Half Marks | 65056 | U+FE20 ... U+FE2F | 组合用半标记 |
| 157 | CJK Compatibility Forms | 65072 | U+FE30 ... U+FE4F | 中日韓相容形式 |
| 158 | Small Form Variants | 65104 | U+FE50 ... U+FE6F | 小型变体形式 |
| 159 | Arabic Presentation Forms-B | 65136 | U+FE70 ... U+FEFF | 阿拉伯语变形显现形式-B |
| 160 | Halfwidth and Fullwidth Forms | 65280 | U+FF00 ... U+FFEF | 半角及全角字符 |
| 161 | Specials | 65520 | U+FFF0 ... U+FFFF | 特色菜 |
| 162 | Linear B Syllabary | 65536 | U+10000 ... U+1007F | 线性B音节 |
| 163 | Linear B Ideograms | 65664 | U+10080 ... U+100FF | 线形文字B表意文字 |
| 164 | Aegean Numbers | 65792 | U+10100 ... U+1013F | 爱琴数字 |
| 165 | Ancient Greek Numbers | 65856 | U+10140 ... U+1018F | 古希腊数字 |
| 166 | Ancient Symbols | 65936 | U+10190 ... U+101CF | 古代符号 |
| 167 | Phaistos Disc | 66000 | U+101D0 ... U+101FF | Phaistos盘 |
| 168 | Lycian | 66176 | U+10280 ... U+1029F | 利西亚 |
| 169 | Carian | 66208 | U+102A0 ... U+102DF | 卡里安 |
| 170 | Coptic Epact Numbers | 66272 | U+102E0 ... U+102FF | coptic epact编号 |
| 171 | Old Italic | 66304 | U+10300 ... U+1032F | 古意大利文 |
| 172 | Gothic | 66352 | U+10330 ... U+1034F | 哥特式的 |
| 173 | Old Permic | 66384 | U+10350 ... U+1037F | 旧二叠纪 |
| 174 | Ugaritic | 66432 | U+10380 ... U+1039F | 乌加里特语 |
| 175 | Old Persian | 66464 | U+103A0 ... U+103DF | 古波斯人 |
| 176 | Deseret | 66560 | U+10400 ... U+1044F | 德塞莱特 |
| 177 | Shavian | 66640 | U+10450 ... U+1047F | 沙威语 |
| 178 | Osmanya | 66688 | U+10480 ... U+104AF | 奥斯曼尼亚 |
| 179 | Osage | 66736 | U+104B0 ... U+104FF | 奥萨奇 |
| 180 | Elbasan | 66816 | U+10500 ... U+1052F | 埃尔巴桑 |
| 181 | Caucasian Albanian | 66864 | U+10530 ... U+1056F | 高加索阿尔巴尼亚语 |
| 182 | Linear A | 67072 | U+10600 ... U+1077F | 线性A |
| 183 | Cypriot Syllabary | 67584 | U+10800 ... U+1083F | 塞浦路斯音节文字 |
| 184 | Imperial Aramaic | 67648 | U+10840 ... U+1085F | 皇家亚拉姆语 |
| 185 | Palmyrene | 67680 | U+10860 ... U+1087F | 帕尔迈拉文 |
| 186 | Nabataean | 67712 | U+10880 ... U+108AF | 纳巴塔语 |
| 187 | Hatran | 67808 | U+108E0 ... U+108FF | 哈特兰 |
| 188 | Phoenician | 67840 | U+10900 ... U+1091F | 腓尼基人 |
| 189 | Lydian | 67872 | U+10920 ... U+1093F | 吕底亚人 |
| 190 | Meroitic Hieroglyphs | 67968 | U+10980 ... U+1099F | 快乐象形文字 |
| 191 | Meroitic Cursive | 68000 | U+109A0 ... U+109FF | 快乐草书 |
| 192 | Kharoshthi | 68096 | U+10A00 ... U+10A5F | 卡罗什提 |
| 193 | Old South Arabian | 68192 | U+10A60 ... U+10A7F | 旧的南阿拉伯 |
| 194 | Old North Arabian | 68224 | U+10A80 ... U+10A9F | 旧的北阿拉伯 |
| 195 | Manichaean | 68288 | U+10AC0 ... U+10AFF | 摩尼教徒 |
| 196 | Avestan | 68352 | U+10B00 ... U+10B3F | 阿维斯坦 |
| 197 | Inscriptional Parthian | 68416 | U+10B40 ... U+10B5F | 帕提亚铭文 |
| 198 | Inscriptional Pahlavi | 68448 | U+10B60 ... U+10B7F | 巴拉维铭文 |
| 199 | Psalter Pahlavi | 68480 | U+10B80 ... U+10BAF | 帕拉维诗篇 |
| 200 | Old Turkic | 68608 | U+10C00 ... U+10C4F | 古突厥语 |
| 201 | Old Hungarian | 68736 | U+10C80 ... U+10CFF | 古匈牙利语 |
| 202 | Rumi Numeral Symbols | 69216 | U+10E60 ... U+10E7F | 鲁米数字符号 |
| 203 | Brahmi | 69632 | U+11000 ... U+1107F | 布拉米 |
| 204 | Kaithi | 69760 | U+11080 ... U+110CF | 凯提文 |
| 205 | Sora Sompeng | 69840 | U+110D0 ... U+110FF | 索拉·索姆彭 |
| 206 | Chakma | 69888 | U+11100 ... U+1114F | 恰克玛 |
| 207 | Mahajani | 69968 | U+11150 ... U+1117F | 马哈贾尼 |
| 208 | Sharada | 70016 | U+11180 ... U+111DF | 莎拉达 |
| 209 | Sinhala Archaic Numbers | 70112 | U+111E0 ... U+111FF | 僧伽罗古数字 |
| 210 | Khojki | 70144 | U+11200 ... U+1124F | 霍基 |
| 211 | Multani | 70272 | U+11280 ... U+112AF | 穆尔塔尼 |
| 212 | Khudawadi | 70320 | U+112B0 ... U+112FF | 库达瓦迪 |
| 213 | Grantha | 70400 | U+11300 ... U+1137F | 格兰萨 |
| 214 | Newa | 70656 | U+11400 ... U+1147F | 纽瓦 |
| 215 | Tirhuta | 70784 | U+11480 ... U+114DF | 蒂尔胡塔 |
| 216 | Siddham | 71040 | U+11580 ... U+115FF | 悉昙 |
| 217 | Modi | 71168 | U+11600 ... U+1165F | 莫迪 |
| 218 | Mongolian Supplement | 71264 | U+11660 ... U+1167F | 蒙古语增补 |
| 219 | Takri | 71296 | U+11680 ... U+116CF | 塔克里 |
| 220 | Ahom | 71424 | U+11700 ... U+1173F | 阿霍姆 |
| 221 | Warang Citi | 71840 | U+118A0 ... U+118FF | 华阳花旗 |
| 222 | Zanabazar Square | 72192 | U+11A00 ... U+11A4F | 扎纳巴扎广场 |
| 223 | Soyombo | 72272 | U+11A50 ... U+11AAF | 索永布 |
| 224 | Pau Cin Hau | 72384 | U+11AC0 ... U+11AFF | 保罗·辛哈 |
| 225 | Bhaiksuki | 72704 | U+11C00 ... U+11C6F | 比丘基 |
| 226 | Marchen | 72816 | U+11C70 ... U+11CBF | 马尔肯 |
| 227 | Masaram Gondi | 72960 | U+11D00 ... U+11D5F | 玛莎兰·冈迪 |
| 228 | Cuneiform | 73728 | U+12000 ... U+123FF | 楔形文字 |
| 229 | Cuneiform Numbers and Punctuation | 74752 | U+12400 ... U+1247F | 楔形文字数字和标点符号 |
| 230 | Early Dynastic Cuneiform | 74880 | U+12480 ... U+1254F | 早期的楔形文字 |
| 231 | Egyptian Hieroglyphs | 77824 | U+13000 ... U+1342F | 埃及象形文字 |
| 232 | Anatolian Hieroglyphs | 82944 | U+14400 ... U+1467F | 安纳托利亚象形文字 |
| 233 | Bamum Supplement | 92160 | U+16800 ... U+16A3F | 巴马补充剂 |
| 234 | Mro | 92736 | U+16A40 ... U+16A6F | 磁共振成像 |
| 235 | Bassa Vah | 92880 | U+16AD0 ... U+16AFF | 巴萨瓦赫 |
| 236 | Pahawh Hmong | 92928 | U+16B00 ... U+16B8F | 帕霍姆 |
| 237 | Miao | 93952 | U+16F00 ... U+16F9F | 苗 |
| 238 | Ideographic Symbols and Punctuation | 94176 | U+16FE0 ... U+16FFF | 表意符号和标点 |
| 239 | Tangut | 94208 | U+17000 ... U+187FF | 小精灵 |
| 240 | Tangut Components | 100352 | U+18800 ... U+18AFF | 探戈组件 |
| 241 | Kana Supplement | 110592 | U+1B000 ... U+1B0FF | 假名增补 |
| 242 | Kana Extended-A | 110848 | U+1B100 ... U+1B12F | 假名扩展-A |
| 243 | Nushu | 110960 | U+1B170 ... U+1B2FF | 女书 |
| 244 | Duployan | 113664 | U+1BC00 ... U+1BC9F | 杜宝莲 |
| 245 | Shorthand Format Controls | 113824 | U+1BCA0 ... U+1BCAF | 速记格式控件 |
| 246 | Byzantine Musical Symbols | 118784 | U+1D000 ... U+1D0FF | 东正教音乐符号 |
| 247 | Musical Symbols | 119040 | U+1D100 ... U+1D1FF | 音乐符号 |
| 248 | Ancient Greek Musical Notation | 119296 | U+1D200 ... U+1D24F | 古希腊音乐符号 |
| 249 | Tai Xuan Jing Symbols | 119552 | U+1D300 ... U+1D35F | 太玄经符号 |
| 250 | Counting Rod Numerals | 119648 | U+1D360 ... U+1D37F | 算筹记数式 |
| 251 | Mathematical Alphanumeric Symbols | 119808 | U+1D400 ... U+1D7FF | 数学字母数字符号 |
| 252 | Sutton SignWriting | 120832 | U+1D800 ... U+1DAAF | 萨顿书写 |
| 253 | Glagolitic Supplement | 122880 | U+1E000 ... U+1E02F | 格拉哥里文增补剂 |
| 254 | Mende Kikakui | 124928 | U+1E800 ... U+1E8DF | 孟德基卡库 |
| 255 | Adlam | 125184 | U+1E900 ... U+1E95F | 阿德拉姆 |
| 256 | Arabic Mathematical Alphabetic Symbols | 126464 | U+1EE00 ... U+1EEFF | 阿拉伯数学字母符号 |
| 257 | Mahjong Tiles | 126976 | U+1F000 ... U+1F02F | 麻将牌 |
| 258 | Domino Tiles | 127024 | U+1F030 ... U+1F09F | 多米诺牌 |
| 259 | Playing Cards | 127136 | U+1F0A0 ... U+1F0FF | 扑克牌 |
| 260 | Enclosed Alphanumeric Supplement | 127232 | U+1F100 ... U+1F1FF | 随附字母数字补遗 |
| 261 | Enclosed Ideographic Supplement | 127488 | U+1F200 ... U+1F2FF | 封闭表意文字增补 |
| 262 | Miscellaneous Symbols and Pictographs | 127744 | U+1F300 ... U+1F5FF | 其他符号和象形文字 |
| 263 | Emoticons | 128512 | U+1F600 ... U+1F64F | 表情符号 |
| 264 | Ornamental Dingbats | 128592 | U+1F650 ... U+1F67F | 装饰性蝙蝠 |
| 265 | Transport and Map Symbols | 128640 | U+1F680 ... U+1F6FF | 运输和地图符号 |
| 266 | Alchemical Symbols | 128768 | U+1F700 ... U+1F77F | 炼金术符号 |
| 267 | Geometric Shapes Extended | 128896 | U+1F780 ... U+1F7FF | 几何图形扩展 |
| 268 | Supplemental Arrows-C | 129024 | U+1F800 ... U+1F8FF | 补充箭头-C |
| 269 | Supplemental Symbols and Pictographs | 129280 | U+1F900 ... U+1F9FF | 补充符号和象形文字 |
| 270 | CJK Unified Ideographs Extension B | 131072 | U+20000 ... U+2A6DF | CJK统一汉字扩展B |
| 271 | CJK Unified Ideographs Extension C | 173824 | U+2A700 ... U+2B73F | CJK统一汉字扩展C |
| 272 | CJK Unified Ideographs Extension D | 177984 | U+2B740 ... U+2B81F | CJK统一汉字扩展D |
| 273 | CJK Unified Ideographs Extension E | 178208 | U+2B820 ... U+2CEAF | CJK统一汉字扩展E |
| 274 | CJK Unified Ideographs Extension F | 183984 | U+2CEB0 ... U+2EBEF | CJK统一汉字扩展F |
| 275 | CJK Compatibility Ideographs Supplement | 194560 | U+2F800 ... U+2FA1F | 中日韩兼容表意文字增补 |
| 276 | Tags | 917504 | U+E0000 ... U+E007F | 标签 |
| 277 | Variation Selectors Supplement | 917760 | U+E0100 ... U+E01EF | 字型变换选取器补充 |
| 278 | Supplementary Private Use Area-A | 983040 | U+F0000 ... U+FFFFF | 辅助私人使用区-A |
| 279 | Supplementary Private Use Area-B | 1048576 | U+100000 ... U+10FFFF | 辅助私人使用区-B |
参考链接:https://www.utf8-chartable.de/unicode-utf8-table.pl