目标检测研究综述+LocNet

阅读全文
正文共3531个字,39张图,预计阅读时间9分钟。
01
localization accuracy


更准确的bounding box,提高IOU
02
目标检测的发展
1、传统的目标检测(滑动窗口的框架)
(1).滑动窗口
(2).提取特征(SIFT,HOG,LBP)
(3).分类器(SVM)
2、基于深度学习的目标检测

d
具体发展
(1).R-CNN
Motivation:目标检测进展缓慢,CNN在图片分类中取得重大成功
Contribution:应用CNN将检测问题转化成分类问题
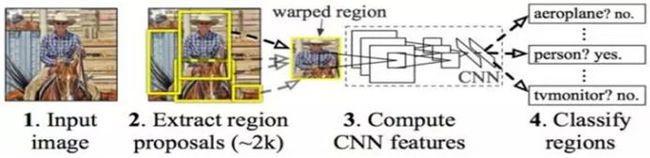
RCNN
(2).SPPNet
Motivation:CNN要求输入图片尺寸固定
Contribution:引入SPP层解除固定尺寸约束
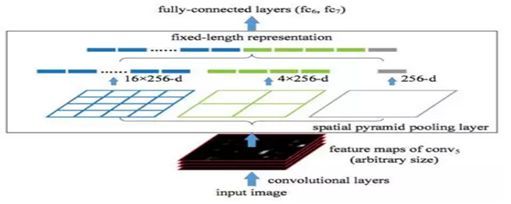
SPPNet
(3).Fast R-CNN
Motivation:候选框的重复计算问题
Contribution: 加入RoI池化层、将BB回归融入网络
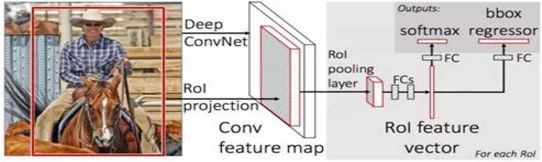
Fast R-CNN
(4).faster RCNN
Motivation: Selective Search作为一个独立的操作,速度依然不够快。
Contribution:抛弃了Selective Search,引入了RPN网络,使得区域提名、分类、回归一起共用卷积特征,从而得到了进一步的加速。
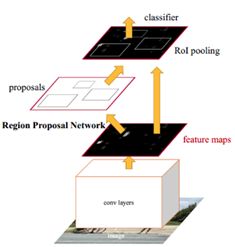
faster rcnn
(5).YOLO
Motivation:先前提出的算法都是将检测问题转化为分类解决
Contribution:将检测回归到回归方法,提高实时性能
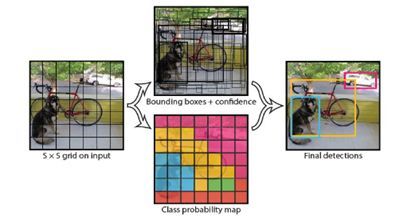
YOLO
(6).SSD
Motivation:yolo S×S的网格就是一个比较启发式的策略,难以检测小目标
Contribution:借鉴了Faster R-CNN中的Anchor机制,使用了多尺度特征金字塔
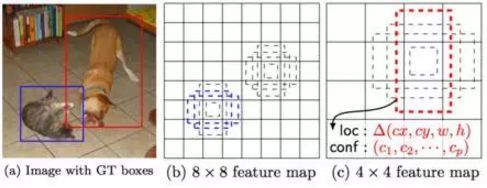
SSD
03
目标检测的几个名词
(1). MAP(mean average precision)

每一个类别都可以根据recall和precision绘制一条曲线,那么AP就是该曲线下的面积,而mAP是多个类别AP的平均值,这个值介于0到1之间,且越大越好。这个指标是目标检测算法最为重要的一个。
(2).IOU

绿色框是人工标注的groundtruth,红色框是目标检测算法最终给出的结果,显然绿色框对于飞机这个物体检测的更加准确(机翼机尾都全部包含在绿色框中),IOU正是表达这种bounding box和groundtruth的差异的指标。算法产生的bbox VS 人工标注的数据。
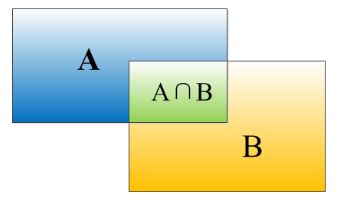
IOU定义了两个bounding box的重叠度,可以说,当算法给出的框和人工标注的框差异很小时,或者说重叠度很大时,可以说算法产生的boundingbox就很准确。
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
(3). NMS(非极大值抑制)

目标检测算法一般会给出目标很多的粗略结果,对一个目标成百上千的粗略结果都进行调整肯定是不可行的。那么我们就需要对这些粗略结果先进行一个大体的挑选。挑选出其中最具代表性的结果。再对这些挑选后的结果进行调整,这样可以加快算法效率。
消除多余的框,找到最佳的bbox
根据这些框的分类器类别分类概率做排序: A
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框
(4) 边界框回归(Bounding-box regression )

由前面介绍的IOU指标可知,这里算法给出的红色框可以认为是检测失败的,因为它和绿色的groundtruth的 IOU值小于了0.5,也就是说重叠度不够。那么我们就需要对这个红色框进行微调。使得经过微调后的窗口跟Ground Truth 更接近 。
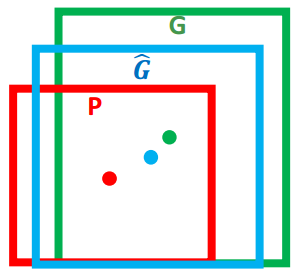
红色的框 P 代表原始的Proposal
**绿色的框 G **代表目标的 Ground Truth
目标是:寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口 G~G~≈G

04
从CVPR2016看目标检测的发展趋势
(a)检测精度
如何提高检测精度的指标mAP?
代表性的工作是ResNet、ION和HyperNet
(b)识别效率
如何提高检测速度?
YOLO:这个工作在识别效率方面的优势很明显,可以做到每秒钟45帧图像,处理视频是完全没有问题的
(c)定位精度
如何产生更准确的bounding box? 如何逐步提高评价参数IOU?(Pascal VOC中,这个值为0.5)
LocNet:抛弃boundingbox回归,利用概率模型(本文)
从单纯的一律追求检测精度,到想方法加快检测结果,到最后追求更加准确的结果。侧面反映了目标检测研究的不断进步*。
05
LocNet:Improving localization accuracy for object detection
1. background
localization accuracy 少人问津
PASCAL VOC IOU=0.5 (object has been successfully detected)
Real life higher localization accuracy (e.g. IoU> 0.7) is normally required
COCO detection challenge 把IOU值也作为了最终的评价指标(MAP+IOU)
提高目标检测的IOU(而不仅是MAP)将会成为未来目标检测的主要挑战。
传统的bbox回归:尝试直接通过回归的方式直接得到bbox的坐标,很难得到很准确的bbox。
2. Contributions
可以很方便的和现在最先进的目标检测系统结合
提出了两种基于行列的概率模型解决定位准确率,而不是回归的方式,并与回归方式进行了
对比对传统方法和最先进的方法不同iou下的map都有所提高
未来可以完全取代bbox回归的方法
3.两种概率模型
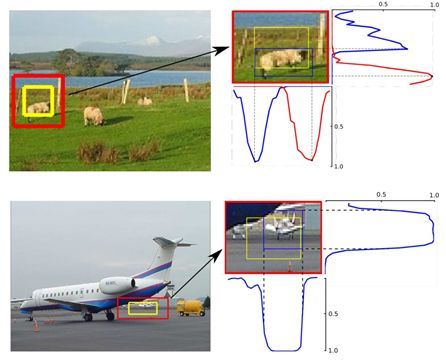
黄色框是检测系统给出的,红色框是由黄色框扩大常数倍得到的search region,LOCNet会在这个搜索区域建立概率模型得到最终的定位区域蓝色框
边界概率:
计算该行或该列是目标边界的概率(所以,行列两个概率图各选两个极大值,即可得到目标边界)in-out概率:
计算目标在该行或该列的概率(所以,行列两个概率图分别选择最高并且最平滑的区域,即可得到目标的区域)
4. detection pipeline

输入的候选bounding box(使用selective search或者sliding windows获得),通过迭代的方法,获得更精确的box
两个过程:
1、Recognition model:
![]()
输入候选box
![]()
为每个box产生一个置信度
2、Localization model:
![]()
输入候选box
![]()
调整box的边界生成新的候选box
为降低算法复杂度,会参与一个后处理NMS操作。
5. Model predictions
输入的box,把它扩大一个因子的倍数,获取一个更大的区域R,区域R划分成M*M的格子
In-Out probabilities
![]()
![]()
产生两个概率,分别代表区域R的每一行或者列包含在bounding box中的概率
ground truth box而言,对于边界内的行或列概率为1,否则为0
**Border probabilities **
![]()
![]()
![]()
![]()
产生4个概率,left (l), right (r), top (t) and bottom (b)
ground truth box
6. Network Architecture

(1)对于输入的box,把它扩大一个因子的倍数,获取一个更大的区域R,把R投影到feature map中
(2)经过一个类似于ROI pooling的层,输出固定大小的map
(3)经过几个卷积层和ReLU激活之后,出现两个分支,分别对应两个向量。然后经过max pooling得到
row、column对应的向量
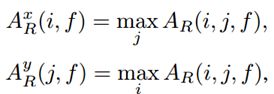
(4)经过FC层之后,使用sigmoid函数输出In –Out概率或者边界概率
7.Loss function
每行或列有两种可能(是或者不是),伯努利分布的模型,log对数损失函数假设样本服从伯努。
利分布(0-1分布)

logistic 回归常用的损失函数交叉熵
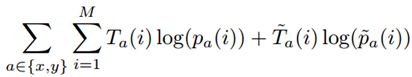
In-Out
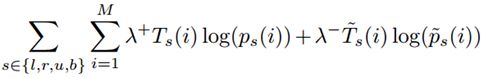
Borders
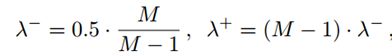
平衡因子,因为作为边界的行或列较少,所以增大他们的权重。
8.results
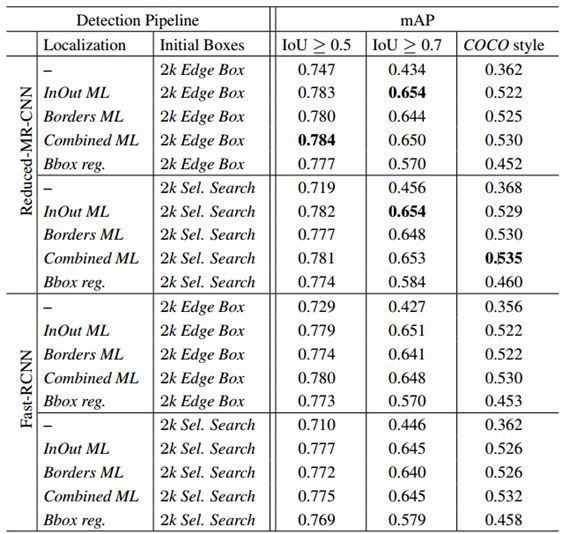
结果表明,与不同的检测系统结合,基于边界概率的模型在不同的IOU下都提高了mAP值,并且效果优于bbox回归。

不同IOU下的MAP
原文链接:https://www.jianshu.com/p/78f614799cf2
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
![]()