NLP系列学习:前向算法和后向算法
NVIDIA DLI 深度学习入门培训 | 特设三场!!
4月28日/5月19日/5月26日 一天密集式学习 快速带你入门 阅读全文
>
一天密集式学习 快速带你入门 阅读全文
>
正文共2444个字,12张图,预计阅读时间8分钟。

在这一篇文章里,我们可以看到HMM经过发展之后是CRF产生的条件,因此我们需要学好隐马尔科夫模型.
在这一部分,我比较推荐阅读宗成庆老师的<自然语言处理>这本书,这一部分宗老师写的很不错,相关的资源在我之前的文章中已经上传,有兴趣的小伙伴可以阅读下.
回到正题,说起HMM,我们知道他是一个产生型模型.这样我们可以把它看作为一个序列化判别器,比方说我们说一句话:
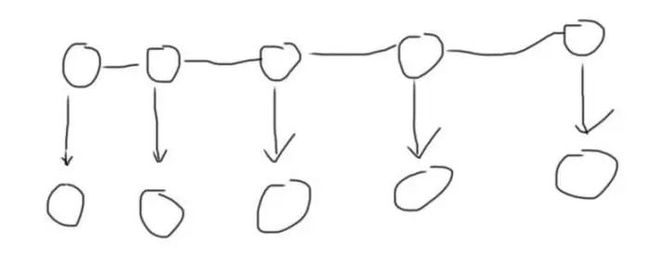
上边是我们说的话,我们说一句话,其实就可以看作为一个状态序列,而下边对应的,我们其实就可以看作为一个判别器,假如我们把上边的说的话和下边的状态序列加上一个符号,如下图所示
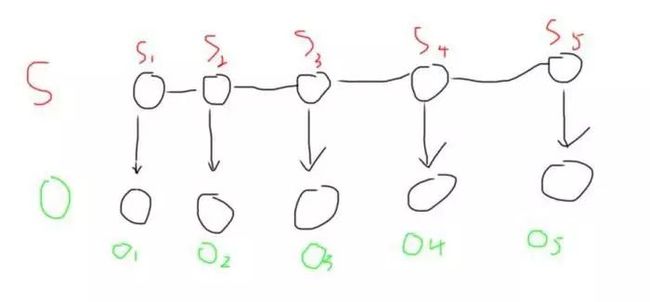
再去求Si->Oj的概率,这样我们写成:

这样我们就可以引申出隐马尔克夫模型的三大问题:
①:估计问题
②:序列问题
③:训练问题或参数估计问题
为了更加容易理解这三个问题,我发现之前有一个博客的掷骰子的例子很生动,便特地引用过来,方便自己理解:
假设手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6), 6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称 这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面 (称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
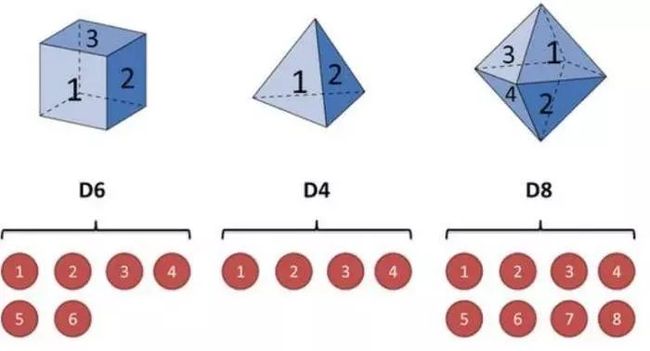
现在我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。 然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4 .
那这时候我们就把这投掷出来的这些数字成为可见状态链,但是在隐马尔可夫模型中,我们丌仅仅有这么一串可见状 态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列.比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
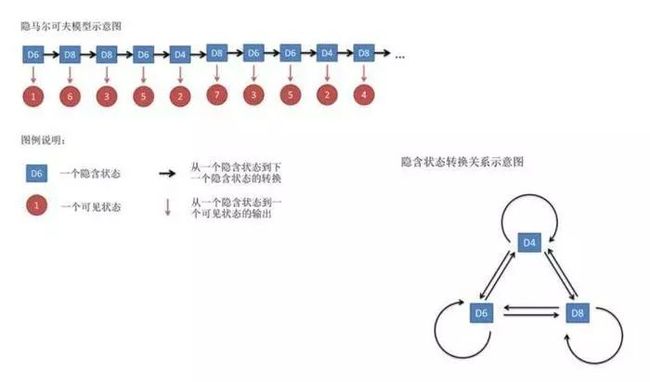
但是一般来说,我们用的马尔科夫链都是隐含状态链, 因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是 D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都 一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概 率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是 D8的概率是0.1。
这样就是一个新的HMM。 同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是 1/2,掷出来是2,3,4,5,6的概率是1/10。 这时候我们再结合这个例子去理解并解决HMM中的三大问题就会容易许多了:
第一个问题:
我们知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
第二个问题:
还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率.
第三个问题:
知道骰子有几种(隐含状态数量),但是并不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
1:估计问题:
在我们知道我们有几种筛子的时候,并且知道筛子是什么,并且已知结果,这时候我们再去推测是哪一种筛子就会容易很多,是可以通过穷举法进行解决的,说白话就是推测所有的隐含状态序列,并且再去计算所以的可能观测序列的概率,但是这样的方法也有问题,如果你的可能,就跟上边的三个筛子一样,还比较OK,因为你的概率还是很大,比较容易猜得对,但是你有100个长度的话,不说多了,每个长度上对应的隐含状态为2,这样你的时间复杂度就是O(2的100方),这个复杂度是很高的,尽管很简单,但是还是不实用的.就跟我们查找中的直接查找一样,尽管简单,但是实则更困难.这样的话,我们就采用了前向算法和后向算法来去计算这个问题.
那下边我们就去推一下这个公式:
首先,我们要假设一个变量at(i),这个变量的意义是说我们在t时刻(1
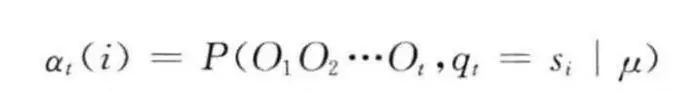
而我们接下来要做的是计算这个at(i),然后就可以根据at(i)来去计算在T时刻的概率,最后也就计算出P(O|u),这时候O是0-T时刻的概率,我们自然就可以计算出所有时刻的概率.
在这里,我们要用归纳思想去计算在t+1时刻的at+1(i):

这时候我们通过一张图去直观的表示从i到j的状态转移过程:
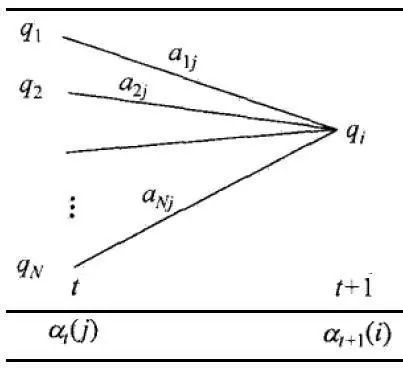
最终的计算得到的概率为:

那后向算法其实就跟前向算法类似,过程图如下:

那么由上述所知,前向和后向算法的时间复杂度均是O(N2T),这个相比起之前,已经优化了太多,其中N是隐藏状态的长度,T是序列的长度.
下一篇文章,我们将去学习HMM中的第二个问题:估计序列问题
参考文章:
1:http://www.cnblogs.com/skyme/p/4651331.html
2:HMM经典论文《A tutorial on Hidden Markov Models and selected applications in speech recognition》
原文链接:https://www.jianshu.com/p/7e537cd96c6f
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础