TensorFlow实现Attention机制
六月 北京 | 高性能计算之GPU CUDA培训
6月22-24日 三天密集式学习 快速带你入门
阅读全文
>
三天密集式学习 快速带你入门
阅读全文
>
正文共996个字,10张图,预计阅读时间15分钟。
原理介绍

图片1

图片2

图片3
更多资料:
https://distill.pub/2016/augmented-rnns/#attentional-interfaces
https://www.cnblogs.com/shixiangwan/p/7573589.html#top
Hierarchical Attention Networks for Document Classification(http://www.aclweb.org/anthology/N16-1174)
这篇文章主要讲述了基于Attention机制实现文本分类
Word Encoder:
①给定一个句子si,例如 The superstar is walking in the street,由下面表示[wi1,wi2,wi3,wi4,wi5,wi6,wi1,wi7],我们使用一个词嵌入矩阵W将单词编码为向量
![]()
②使用双向GRU编码整个句子关于单词wit的隐含向量:

那么最终隐含向量为前向隐含向量和后向隐含向量拼接在一起
![]()
Word Attention:
给定一句话,并不是这个句子中所有的单词对个句子语义起同等大小的“贡献”,比如上句话“The”,“is”等,这些词没有太大作用,因此我们需要使用attention机制来提炼那些比较重要的单词,通过赋予权重以提高他们的重要性。
①通过一个MLP获取hit的隐含表示:

②通过一个softmax函数获取归一化的权重:

③计算句子向量:
通过每个单词获取的hit与对应权重αit乘积,然后获取获得句子向量
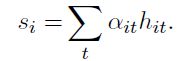
1attenton.py
2import tensorflow as tf
3def attention(inputs, attention_size, time_major=False, return_alphas=False):
4 if isinstance(inputs, tuple):
5# In case of Bi-RNN, concatenate the forward and the backward RNN outputs.
6inputs = tf.concat(inputs, 2)
7if time_major:
8# (T,B,D) => (B,T,D)
9inputs = tf.array_ops.transpose(inputs, [1, 0, 2])
10hidden_size = inputs.shape[2].value # D value - hidden size of the RNN layer
11# Trainable parameters
12w_omega = tf.Variable(tf.random_normal([hidden_size, attention_size], stddev=0.1))
13b_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
14u_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
15with tf.name_scope('v'):
16# Applying fully connected layer with non-linear activation to each of the B*T timestamps;
17# the shape of `v` is (B,T,D)*(D,A)=(B,T,A), where A=attention_size
18v = tf.tanh(tf.tensordot(inputs, w_omega, axes=1) + b_omega)
19# For each of the timestamps its vector of size A from `v` is reduced with `u` vector
20vu = tf.tensordot(v, u_omega, axes=1, name='vu') # (B,T) shape
21alphas = tf.nn.softmax(vu, name='alphas') # (B,T) shape
22# Output of (Bi-)RNN is reduced with attention vector; the result has (B,D) shape
23output = tf.reduce_sum(inputs * tf.expand_dims(alphas, -1), 1)
24if not return_alphas:
25return output
26else:
27return output, alphas
28train.py
29from __future__ import print_function, division
30import numpy as np
31import tensorflow as tf
32from keras.datasets import imdb
33from tensorflow.contrib.rnn import GRUCell
34from tensorflow.python.ops.rnn import bidirectional_dynamic_rnn as bi_rnn
35from tqdm import tqdm
36from attention import attention
37from utils import get_vocabulary_size, fit_in_vocabulary, zero_pad, batch_generator
38NUM_WORDS = 10000
39INDEX_FROM = 3
40SEQUENCE_LENGTH = 250
41EMBEDDING_DIM = 100
42HIDDEN_SIZE = 150
43ATTENTION_SIZE = 50
44KEEP_PROB = 0.8
45BATCH_SIZE = 256
46NUM_EPOCHS = 3 # Model easily overfits without pre-trained words embeddings, that's why train for a few epochs
47 DELTA = 0.5
48 MODEL_PATH = './model'
49# Load the data set
50(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=NUM_WORDS, index_from=INDEX_FROM)
51# Sequences pre-processing
52vocabulary_size = get_vocabulary_size(X_train)
53X_test = fit_in_vocabulary(X_test, vocabulary_size)
54X_train = zero_pad(X_train, SEQUENCE_LENGTH)
55X_test = zero_pad(X_test, SEQUENCE_LENGTH)
56# Different placeholders
57with tf.name_scope('Inputs'):
58batch_ph = tf.placeholder(tf.int32, [None, SEQUENCE_LENGTH], name='batch_ph')
59target_ph = tf.placeholder(tf.float32, [None], name='target_ph')
60seq_len_ph = tf.placeholder(tf.int32, [None], name='seq_len_ph')
61 keep_prob_ph = tf.placeholder(tf.float32, name='keep_prob_ph')
62 # Embedding layer
63 with tf.name_scope('Embedding_layer'):
64 embeddings_var = tf.Variable(tf.random_uniform([vocabulary_size, EMBEDDING_DIM], -1.0, 1.0), trainable=True)
65 tf.summary.histogram('embeddings_var', embeddings_var)
66 batch_embedded = tf.nn.embedding_lookup(embeddings_var, batch_ph)
67 # (Bi-)RNN layer(-s)
68 rnn_outputs, _ = bi_rnn(GRUCell(HIDDEN_SIZE), GRUCell(HIDDEN_SIZE),
69 inputs=batch_embedded, sequence_length=seq_len_ph, dtype=tf.float32)
70 tf.summary.histogram('RNN_outputs', rnn_outputs)
71 # Attention layer
72 with tf.name_scope('Attention_layer'):
73 attention_output, alphas = attention(rnn_outputs, ATTENTION_SIZE, return_alphas=True)
74 tf.summary.histogram('alphas', alphas)
75 # Dropout
76 drop = tf.nn.dropout(attention_output, keep_prob_ph)
77 # Fully connected layer
78 with tf.name_scope('Fully_connected_layer'):
79 W = tf.Variable(tf.truncated_normal([HIDDEN_SIZE * 2, 1], stddev=0.1)) # Hidden size is multiplied by 2 for Bi-RNN
80 b = tf.Variable(tf.constant(0., shape=[1]))
81 y_hat = tf.nn.xw_plus_b(drop, W, b)
82 y_hat = tf.squeeze(y_hat)
83 tf.summary.histogram('W', W)
84 with tf.name_scope('Metrics'):
85 # Cross-entropy loss and optimizer initialization
86 loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y_hat, labels=target_ph))
87 tf.summary.scalar('loss', loss)
88 optimizer = tf.train.AdamOptimizer(learning_rate=1e-3).minimize(loss)
89 # Accuracy metric
90 accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.round(tf.sigmoid(y_hat)), target_ph), tf.float32))
91 tf.summary.scalar('accuracy', accuracy)
92 merged = tf.summary.merge_all()
93 # Batch generators
94 train_batch_generator = batch_generator(X_train, y_train, BATCH_SIZE)
95 test_batch_generator = batch_generator(X_test, y_test, BATCH_SIZE)
96 train_writer = tf.summary.FileWriter('./logdir/train', accuracy.graph)
97 test_writer = tf.summary.FileWriter('./logdir/test', accuracy.graph)
98 session_conf = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))
99 saver = tf.train.Saver()
100 if __name__ == "__main__":
101 with tf.Session(config=session_conf) as sess:
102 sess.run(tf.global_variables_initializer())
103 print("Start learning...")
104 for epoch in range(NUM_EPOCHS):
105 loss_train = 0
106 loss_test = 0
107 accuracy_train = 0
108 accuracy_test = 0
109 print("epoch: {}\t".format(epoch), end="")
110 # Training
111 num_batches = X_train.shape[0] // BATCH_SIZE
112 for b in tqdm(range(num_batches)):
113 x_batch, y_batch = next(train_batch_generator)
114 seq_len = np.array([list(x).index(0) + 1 for x in x_batch]) # actual lengths of sequences
115 loss_tr, acc, _, summary = sess.run([loss, accuracy, optimizer, merged],
116 feed_dict={batch_ph: x_batch, target_ph: y_batch, seq_len_ph: seq_len, keep_prob_ph: KEEP_PROB})
117accuracy_train += acc
118loss_train = loss_tr * DELTA + loss_train * (1 - DELTA)
119train_writer.add_summary(summary, b + num_batches * epoch)
120accuracy_train /= num_batches
121 # Testing
122 num_batches = X_test.shape[0] // BATCH_SIZE
123 for b in tqdm(range(num_batches)):
124 x_batch, y_batch = next(test_batch_generator)
125 seq_len = np.array([list(x).index(0) + 1 for x in x_batch]) # actual lengths of sequences
126 loss_test_batch, acc, summary = sess.run([loss, accuracy, merged], feed_dict={batch_ph: x_batch, target_ph: y_batch, seq_len_ph: seq_len, keep_prob_ph: 1.0})
127 accuracy_test += acc
128 loss_test += loss_test_batch
129 test_writer.add_summary(summary, b + num_batches * epoch)
130 accuracy_test /= num_batches
131 loss_test /= num_batches
132 print("loss: {:.3f}, val_loss: {:.3f}, acc: {:.3f}, val_acc: {:.3f}".format(
133 loss_train, loss_test, accuracy_train, accuracy_test
134 ))
135train_writer.close()
136test_writer.close()
137saver.save(sess, MODEL_PATH)
138print("Run 'tensorboard --logdir=./logdir' to checkout tensorboard logs.")
139utils.py
140from __future__ import print_function
141import numpy as np
142def zero_pad(X, seq_len):
143return np.array([x[:seq_len - 1] + [0] * max(seq_len - len(x), 1) for x in X])
144 def get_vocabulary_size(X):
145 return max([max(x) for x in X]) + 1 # plus the 0th word
146 def fit_in_vocabulary(X, voc_size):
147 return [[w for w in x if w < voc_size] for x in X]
148 def batch_generator(X, y, batch_size):
149 """Primitive batch generator
150 """
151 size = X.shape[0]
152 X_copy = X.copy()
153 y_copy = y.copy()
154 indices = np.arange(size)
155 np.random.shuffle(indices)
156 X_copy = X_copy[indices]
157 y_copy = y_copy[indices]
158 i = 0
159 while True:
160if i + batch_size <= size:
161 yield X_copy[i:i + batch_size], y_copy[i:i + batch_size]
162 i += batch_size
163else:
164 i = 0
165 indices = np.arange(size)
166 np.random.shuffle(indices)
167 X_copy = X_copy[indices]
168 y_copy = y_copy[indices]
169 continue
170if __name__ == "__main__":
171# Test batch generator
172gen = batch_generator(np.array(['a', 'b', 'c', 'd']), np.array([1, 2, 3, 4]), 2)
173for _ in range(8):
174xx, yy = next(gen)
175print(xx, yy)
代码地址:https://github.com/ilivans/tf-rnn-attention

在训练集上准确率达到96%,测试集达到86%,效果还是很强大。
原文链接:https://www.jianshu.com/p/cc6407444a8c
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础