基于Tensorflow实现DeepFM
正文共1737张图,7张图,预计阅读时间11分钟。
github:https://github.com/sladesha/deep_learning
01
前言DeepFM,Ctr预估中的大杀器,哈工大与华为诺亚方舟实验室荣耀出品,算法工程师面试高频考题,有效的结合了神经网络与因子分解机在特征学习中的优点:同时提取到低阶组合特征与高阶组合特征,这样的称号我可以写几十条出来,这也说明了DeepFM确实是一个非常值得手动撸一边的算法。
当然,早就有一票人写了一车封装好的deepFM的模型,大家随便搜搜肯定也能搜到,既然这样,我就不再搞这些东西了,今天主要和大家过一遍,deepFM的代码是咋写的,手把手入门一下,说一些我觉得比较重要的地方,方便大家按需修改。(只列举了一部分,更多的解释参见GitHub代码中的注释)
本文的数据和部分代码构造参考了nzc大神的deepfm的Pytorch版本的写法,改成tensorflow的形式,需要看原版的自取。
02
网络结构
DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取,两部分权重共享。
DeepFM的预测结果可以写为:y = sigmoid(y(fm)+y(DNN))
03
FM部分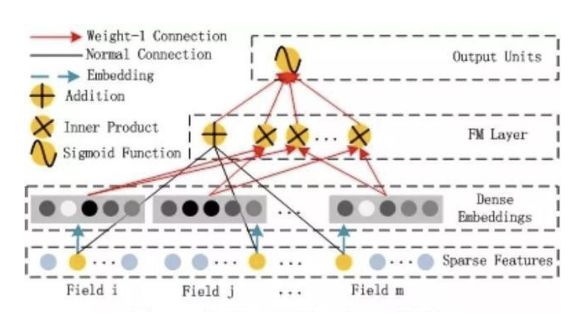
FM公式为: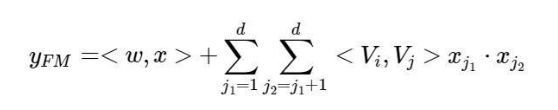
我很久之前一篇文章细节讲过,这边就不多扯了,更多详见FM理论解析及应用。
04
DNN部分
这边其实和我上篇文章说的MLPS差距不大,也就是简单的全链接,差就差在input的构造,这边采取了embedding的思想,将每个feature转化成了embedded vector作为input,同时此处的input也是上面计算FM中的V,更多的大家看代码就完全了解了。
05
代码部分我一共写了两个script,build_data.py和deepfm.py,也很好理解。build_data.py用来预处理数据,deepfm.py用来跑模型。
build_data.py
1for i in range(1, data.shape[1]):
2target = data.iloc[:, I]
3col = target.name
4l = len(set(target))
5if l > 10:
6 target = (target - target.mean()) / target.std()
7 co_feature = pd.concat([co_feature, target], axis=1)
8 feat_dict[col] = cnt
9 cnt += 1
10 co_col.append(col)
11else:
12 us = target.unique()
13 print(us)
14 feat_dict[col] = dict(zip(us, range(cnt, len(us) + cnt)))
15 ca_feature = pd.concat([ca_feature, target], axis=1)
16 cnt += len(us)
17 ca_col.append(col)
18feat_dim = cnt
19feature_value = pd.concat([co_feature, ca_feature], axis=1)
20feature_index = feature_value.copy()
21for i in feature_index.columns:
22if i in co_col:
23 feature_index[i] = feat_dict[I]
24else:
25 feature_index[i] = feature_index[i].map(feat_dict[I])
26 feature_value[i] = 1.
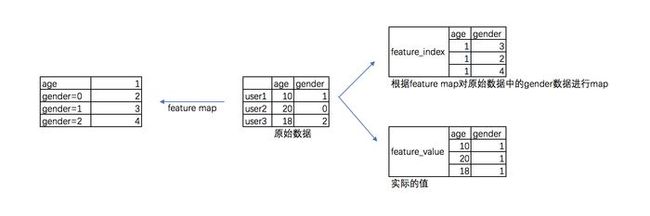
核心部分如上,重要的是做了两件事情,生成了feature_index和feature_value。
feature_index是把所有特征进行了标序,feature1,feature2......featurem,分别对应0,1,2,3,...m,但是,请注意分类变量需要拆分!就是说如果有性别:男|女|未知,三个选项。需要构造feature男,feature女,feature未知三个变量,而连续变量就不需要这样。
feature_value就是特征的值,连续变量按真实值填写,分类变量全部填写1。
更加形象的如下:
deepfm.py
特征向量化
1# 特征向量化,类似原论文中的v
2self.weight['feature_weight'] = tf.Variable(
3 tf.random_normal([self.feature_sizes, self.embedding_size], 0.0, 0.01),
4 name='feature_weight')
5
6# 一次项中的w系数,类似原论文中的w
7self.weight['feature_first'] = tf.Variable(
8 tf.random_normal([self.feature_sizes, 1], 0.0, 1.0),
9 name='feature_first')
可以对照下面的公式看,更有感觉。
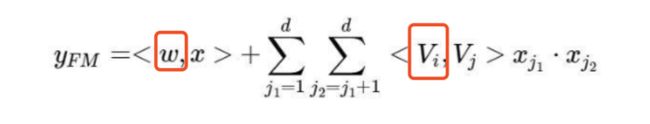
deep网络部分的weight
1# deep网络初始input:把向量化后的特征进行拼接后带入模型,n个特征*embedding的长度
2input_size = self.field_size * self.embedding_size
3init_method = np.sqrt(2.0 / (input_size + self.deep_layers[0]))
4self.weight['layer_0'] = tf.Variable(
5 np.random.normal(loc=0, scale=init_method, size=(input_size, self.deep_layers[0])), dtype=np.float32
6)
7self.weight['bias_0'] = tf.Variable(
8 np.random.normal(loc=0, scale=init_method, size=(1, self.deep_layers[0])), dtype=np.float32
9)
10# 生成deep network里面每层的weight 和 bias
11if num_layer != 1:
12 for i in range(1, num_layer):
13 init_method = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[I]))
14 self.weight['layer_' + str(i)] = tf.Variable(
15 np.random.normal(loc=0, scale=init_method, size=(self.deep_layers[i - 1], self.deep_layers[i])),
16 dtype=np.float32)
17 self.weight['bias_' + str(i)] = tf.Variable(
18 np.random.normal(loc=0, scale=init_method, size=(1, self.deep_layers[i])),
19 dtype=np.float32)
20
21# deep部分output_size + 一次项output_size + 二次项output_size
22last_layer_size = self.deep_layers[-1] + self.field_size + self.embedding_size
23init_method = np.sqrt(np.sqrt(2.0 / (last_layer_size + 1)))
24# 生成最后一层的结果
25self.weight['last_layer'] = tf.Variable(
26 np.random.normal(loc=0, scale=init_method, size=(last_layer_size, 1)), dtype=np.float32)
27self.weight['last_bias'] = tf.Variable(tf.constant(0.01), dtype=np.float32)
input的地方需要注意一下,这边用了个技巧,直接把把向量化后的特征进行拉伸拼接后带入模型,原来的v是batch*n个特征*embedding的长度,直接改成了batch*(n个特征*embedding的长度),这样的好处就是全值共享,又快又有效。
06
网络传递部分都是一些正常的操作,稍微要注意一下的是交互项的计算:
1# second_order
2self.sum_second_order = tf.reduce_sum(self.embedding_part, 1)
3self.sum_second_order_square = tf.square(self.sum_second_order)
4print('sum_square_second_order:', self.sum_second_order_square)
5# sum_square_second_order: Tensor("Square:0", shape=(?, 256), dtype=float32)
6
7self.square_second_order = tf.square(self.embedding_part)
8self.square_second_order_sum = tf.reduce_sum(self.square_second_order, 1)
9print('square_sum_second_order:', self.square_second_order_sum)
10# square_sum_second_order: Tensor("Sum_2:0", shape=(?, 256), dtype=float32)
11
12# 1/2*((a+b)^2 - a^2 - b^2)=ab
13self.second_order = 0.5 * tf.subtract(self.sum_second_order_square, self.square_second_order_sum)
14
15self.fm_part = tf.concat([self.first_order, self.second_order], axis=1)
16print('fm_part:', self.fm_part)直接实现了下面的计算逻辑:
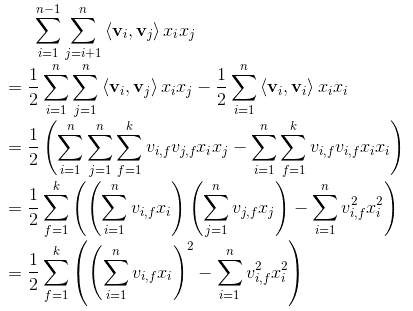
07
Loss部分我个人重写了一下我认为需要正则的地方,和一些loss的计算方式:
1# loss
2self.out = tf.nn.sigmoid(self.out)
3
4# loss = tf.losses.log_loss(label,out) 也行,看大家想不想自己了解一下loss的计算过程
5self.loss = -tf.reduce_mean(
6 self.label * tf.log(self.out + 1e-24) + (1 - self.label) * tf.log(1 - self.out + 1e-24))
7
8# 正则:sum(w^2)/2*l2_reg_rate
9# 这边只加了weight,有需要的可以加上bias部分
10self.loss += tf.contrib.layers.l2_regularizer(self.l2_reg_rate)(self.weight["last_layer"])
11for i in range(len(self.deep_layers)):
12 self.loss += tf.contrib.layers.l2_regularizer(self.l2_reg_rate)(self.weight["layer_%d" % I])
大家也可以直接按照我注释掉的部分简单操作,看个人的理解了。
08
梯度正则1self.global_step = tf.Variable(0, trainable=False)
2opt = tf.train.GradientDescentOptimizer(self.learning_rate)
3trainable_params = tf.trainable_variables()
4print(trainable_params)
5gradients = tf.gradients(self.loss, trainable_params)
6clip_gradients, _ = tf.clip_by_global_norm(gradients, 5)
7self.train_op = opt.apply_gradients(
8 zip(clip_gradients, trainable_params), global_step=self.global_step)
很多网上的代码跑着跑着就NAN了,建议加一下梯度的正则,反正也没多复杂。
09
执行结果 1/Users/slade/anaconda3/bin/python/Users/slade/Documents/Personalcode/machine-learning/Python/deepfm/deepfm.py
2[2 1 0 3 4 6 5 7]
3[0 1 2]
4[6 0 8 2 4 1 7 3 5 9]
5[2 3 1 0]
6W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
7W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
8W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
9W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
10W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
11embedding_part: Tensor("Mul:0", shape=(?, 39, 256), dtype=float32)
12first_order: Tensor("Sum:0", shape=(?, 39), dtype=float32)
13sum_square_second_order: Tensor("Square:0", shape=(?, 256), dtype=float32)
14square_sum_second_order: Tensor("Sum_2:0", shape=(?, 256), dtype=float32)
15fm_part: Tensor("concat:0", shape=(?, 295), dtype=float32)
16deep_embedding: Tensor("Reshape_2:0", shape=(?, 9984), dtype=float32)
17output: Tensor("Add_3:0", shape=(?, 1), dtype=float32)
18[object at 0x10e2a9ba8>, object at 0x112885ef0>, object at 0x1129b3c18>, object at 0x1129b3da0>, object at 0x1129b3f28>, object at 0x1129b3c50>, object at 0x112a03dd8>, object at 0x112a03b38>, object at 0x16eae5c88>, object at 0x112b937b8>]
19 time all:7156
20 epoch 0:
21the times of training is 0, and the loss is 8.54514
22the times of training is 100, and the loss is 1.60875
23the times of training is 200, and the loss is 0.681524
24the times of training is 300, and the loss is 0.617403
25the times of training is 400, and the loss is 0.431383
26the times of training is 500, and the loss is 0.531491
27the times of training is 600, and the loss is 0.558392
28the times of training is 800, and the loss is 0.51909
29... 看了下没啥大问题。
还有一些要说的
build_data.py中我为了省事,只做了标准化,没有进行其他数据预处理的步骤,这个是错误的,大家在实际使用中请按照我在公众号里面给大家进行的数据预处理步骤进行,这个非常重要!
learing_rate是我随便设置的,在实际大家跑模型的时候,请务必按照1.0,1e-3,1e-6,三个节点进行二分调优。
如果你直接搬上面代码,妥妥过拟合,请在真实使用过程中,务必根据数据量调整batch的大小,epoch的大小,建议在每次传递完成后加上tf.nn.dropout进行dropout。
如果数据量连10万量级都不到,我还是建议用机器学习的方法,xgboost+lr,mixed logistics regression等等都是不错的方法。
好了,最后附上全量代码的地址Github,希望对大家有所帮助。
原文链接:https://www.jianshu.com/p/71d819005fed
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础