一、Visual Tracking领域
最近因为团队业务需要,涉及实时视频流中Object Tracking技术,所以读了一些Paper和前人写的一些综述性质的文章。
VOT领域目前要有三大技术分支:
1、图像特征+分类器的传统方法:如HOG+SVM等
2、CF(Correlation Filter):如DCF、KCF、SRDCF等
3、基于DL的End2End模型:如MDNet、TCNN等
MileStone:
1、~2013:传统特征+分类
2、2013~2015:CF类模型出现
3、2015~:CNN 的end2end模型出现
目前DL类模型在效果上显著超过CF类,但性能到目前为止还是落后于CF类“几个世纪”。因此,目前效果和性能兼具的实用性Tracking模型还是CF类,如SRDCF。传统方法无论在效果or性能上在VOT竞赛中已经被远远落下。
二、MDNet
MDNet是在2015年VOT竞赛的冠军,这篇文章其实2015年底就出来了。MDNet是Korea的POSTECH这个团队做的,与TCNN和CNN-SVM同一出处。
2015年底的时候,Visual Tracking领域继Object Detection之后,陆续将CNN引入,但是大部分算法只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,结果证明确实用了CNN深度特征对跟踪结果是有较大的改进的。那么其实自己设计一个网络来做跟踪是大家都能够想到的思路,Korea的POSTECH这个团队就做了MDNet。
为什么直到2015年CNN才在目前跟踪Tracking领域看到呢?
1、很难收集海量的训练数据;
2、CF类的模型在效果和性能上,都取得了不错的效果
3、在ImageNet上预训练的深度特征方法,效果有提升但不明显
三、MDNet Motivation
1、Prerain问题。在大规模数据上预训练CNN做深度特征提取,显然不如直接在视频跟踪数据上直接训练跟踪模型的CNN更合理。对于跟踪目标,它们的类型虽然可能不同,但应该存在某些共性包括边缘梯度等,是需要网络去学习的。
2、Multi-Domain问题。直接用跟踪数据来训练CNN是比较困难的,统一个Object,在一个视频帧序列中是目标,在另外一个序列中可能就是北京。另外,每个序列中目标的差异很大,还有一些额外的挑战如background clutter、occlusions、illumination variations等。
3、网络大小问题。在Detection、Classification、Segmentation中的CNN网络都很大,因为Label的规模都很大。然而在Tracking中,Label只有两类:目标 or 背景。模型太大会导致在数据在空间上太稀疏,也会导致计算耗时。
四、Multi-Domain NetWork(MDNet)
1、Network Architecture

输入层:RGB3通道107✖️107大小的Bounding Box(目标框/候选框)
卷积层:VGG-M模型改造了Filter大小,保证conv-3输出3✖️3的feature map
全连接层:fc4/fc5是两个512的FC层分别含有Relu和Dropout
Domain-specific Layers:fc6是最终的二分类层,一共K个,对应K个Domain(其实就是K个标注的视频),每次训练的时候只有对应该视频的fc6被使用,前面的层都是共享的。
2、Learning Algorithm
CNN采用SGD优化,为了学到不同视频中目标的共性,采用Domain-specific的训练方式:假设用K个视频来做训练,一共做N次循环,在第k个迭代,只用来自kmodK的视频帧序列的正负样本进行训练,同时fc6中只有对应该视频的branch才会被使用。
整个过程重复,直到网络收敛或者预设的总迭代数达到。通过这个Offline的学习过程,domain-independent 信息在前面几个共享层中将被有效的学习和建模。
五、Online Tracking And Learning using MDNet
将Offline 学习到的multi-domain模型,用于Tracking时,fc6层的K个分支,会用一个新的唯一的全连接层fc6替换掉。之后online fine-tune fc4~6 三个全连接层。
1、Tracking Control 和 Network Online Update
Tracking 策略比较简单,主要两个环节:选择候选目标框集合+判断每个目标框是目标的概率。最终最大概率的候选框即为预测的目标框。
Network Online update是相对略复杂的,分为Long-term 和 Short-term 更新,主要是为了从robustness 和 adaptiveness两个角度权衡。
2、Bounding Box Regresssion
因为CNN深度特征的高度抽象性,以及模型筛选Positive样本框中使用了Data augmentation 策略,导致最终预测最大概率的目标框不能准确的包含target。为了提升accuracy,借鉴在detection中的bbox regression 分支,将conv3的feature基础上,通过linear regression对候选框做一个微调。做regression的基础是候选框的打分>0.5。
Bbox regression仅在第一帧做一次训练,一个原因是太耗时,另外一个是过度的调整也存在风险。
3、Tracking 和 Update的过程描述

核心环节包含:
1)训练 Bbox regression model
按照高斯分布采样10000个回归样本框,计算样本框和ground truth的IoU,仅保留IoU>0.6的样本,并从中随机1000个作为最终样本。计算样本对应的conv3 特征,将512个3*3 feature map拉伸和拼接成一个向量,训练线性回归模型。
2)生成Positive 和Negative 样本框
【Offline multi-domain模型的样本】
每一帧生成50正样本,200负样本,要求正样本IoU>=0.7,负样本IoU<=0.5。
从全部序列包含的帧集合中随机8帧,构成一个mini-batch,其中包含400(850)个正样本,然后从中随机32个作为mini-batch中最终的正样本;将包含的1024(应该是8200?)个负样本,送到CNN中并选择打分最高的96个(Hard Negative Mining策略)作为mini-batch最终的负样本。
【Online Learning模型的样本】
每一帧生成50正样本,200负样本,要求正样本IoU>=0.7,负样本IoU<=0.3。正样本最大集合500,负样本最大集合5000。其他Hard Negative Mining 策略同Offine模型。
3)生成候选框
为每一帧生成候选目标框,按照Gaussian分布采样出256个候选框。候选框用(x,y,s)表示。高斯分布mean是前一帧目标框的位置,covariance是diagonal matrix diag(0.09r^2, 0.09r^2, 0.25),其中r是前一帧目标框宽和高的均值。初始目标的scale乘以1.05^s作为每个候选框的scale(不是通过采样得到?)
4)其他训练细节
A)multi-domain 用K个序列训练,迭代100K次,conv层的lr=0.0001,fc层lr=0.001。
B)Online Learning的第一帧,fc层迭代30次,fc4-5的lr=0.0001,fc6的lr=0.001。在后续的帧中,每次update模型时训练迭代10次,lr是第一帧的3倍。
C)Momentum 和 weight decay分别是0.9和0.0005
六、实验结论
1、OTB50和OTB100

2、VOT2014
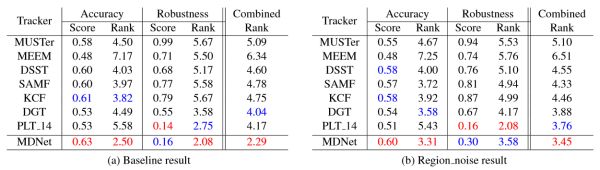
3、结论
总结一下MDNet效果好的原因:
用了CNN特征,并且是专门为了tracking设计的网络,用tracking的数据集做了训练
有做在线的微调fine-tune,这一点虽然使得速度慢,但是对结果很重要
Candidates的采样同时也考虑到了尺度,使得对尺度变化的视频也相对鲁棒
Hard negative mining和bounding box regression这两个策略的使用,使得结果更加精确