A Deep Relevance Matching Model for Ad-hoc Retrieval阅读笔记
文章目录
- 前记
- 概述
- 论文贡献点
- 语义匹配和关联匹配比较
- 模型
- Matching Histogram Mapping
- 前馈匹配网络
- 词项门控网络(Term Gating Network)
- 模型训练
- 实验
- 数据集
- 评价指标
前记
最近忙着秋招(主要是懒),好像已经很久没写博客了。
最近在看一些检索相关的论文,顺便记录下吧。
概述
这篇论文将深度学习应用到Ad-hoc Retrieval领域。Ad-hoc Retrieval和之前介绍过的几篇文本匹配论文还是有区别的。之前几篇面向的主要是paraphrase identification,natural language inference,question answering等问题,这些问题主要考虑semantic matching,而Ad-hoc Retrieval主要考虑relevance matching。这两种匹配的区别下面会展开介绍。
论文主要使用了匹配直方图映射(matching histogram mapping),前馈匹配网络,词项门控网络(term gating network)三种结构。
论文贡献点
- 指出语义匹配(semantic matching)和关联匹配(relevance matching)的三个主要区别;
- 提出一种针对Ad-hoc retrieval领域的深度相关匹配模型DRMM;
- 对基准集合上最先进的检索模型进行了严格的比较,分析了现有深度匹配模型的不足和DRMM的优点。
语义匹配和关联匹配比较
-
语义匹配(semantic matching):
识别语义并推断两个文本片段的关系。
常见应用场景:paraphrase identification,question answering,automatic conversation特点:两个文本片段长度相似,一般都是一句话。
三个匹配要素:
1.相似匹配标志:捕捉两个文本中词,短语,句子的语义相似/相关关系。
2.组合语义:要考虑语法结构,而不是只当做词袋模型。
3.全局匹配需求:语义匹配任务文本长度通常比较有限,所以更多考虑全局匹配结果。 -
关联匹配(relevance matching):
在Ad-hoc retrieval领域,需要判断一篇文档与给定的一个查询时候相关。
可以看出,关联匹配时query通常很短,有时只有几个关键词。而要查询的文档通常比较长,包含多个句子。三个匹配要素:
1.精确匹配标志:query和doc中词项精确匹配。
2.查询词项重要性:用户的查询语句中不同词具有不同的重要性。
3.多样匹配需求(Diverse matching requirement:):因为在检索时文档通常很长,包含很多不同信息。query可能只与文档部分存在相关关系,我们不一定强调全局匹配。
模型
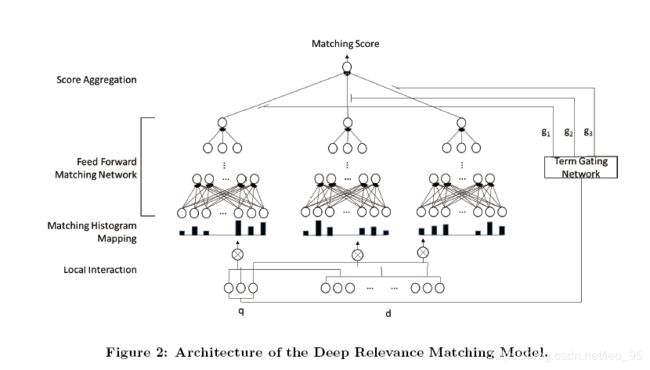
模型总体分为三部分:
- 对query和document每个词项建立局部交互关系(如余弦距离)。然后把变长的局部交互转变为定长的匹配直方图。
- 得到匹配直方图之后,利用前馈网络学习层次匹配模式,对query每个词项计算匹配分数。
- 最终,将query每个词项加权求和得到整体的匹配分数。其中,权重利用一个词项门控网络计算得到。
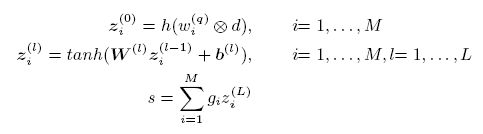
公式一利用局部交互信息生成匹配直方图,公式二为前面提到的多层前馈网络,公式三对匹配分数加权求和。
Matching Histogram Mapping
这部分算是整个论文重点之一。
在生成匹配直方图之前,对query和document每个词项对都建立了局部交互关系。这里存在一个重要问题,就是query和document都是变长的,要想办法转换成定长的。语义匹配任务通常利用匹配矩阵解决这个问题。但是因为ad-hoc retrieval关注Diverse matching requirement而不是全局匹配,所以匹配矩阵不太合适。
该论文的想法是把局部交互转变成匹配直方图。什么意思呢?论文中举了个例子:
假设我们的query是“car”,有篇document内容是“car,rent,truck,bump,injunction,runway”。
我们计算他们的余弦相似性作为局部交互关系,假设是(1,0.2,0.7,0.3,-0.1,0.1)。
因为余弦距离范围是[-1,1],我们可以把这个范围分割成多个不同“箱子”,比如分割成{[-1,-0.5),[-0.5,0),[0,0.5),[0.5,1),[1,1]}。那么我们就可以利用某些映射方法,把局部交互信息映射到不同的“箱子”中。比如最简单的计数映射,计算落到每个“箱子”的数量,就得到[0,1,3,1,1]这样一个匹配直方图。这样我们就可以将之前变长的局部交互关系转变为定长的表示。
映射方法:
论文提出三种映射方法。
- Count-based Histogram(CH)
就是前面例子提到的计数方法。 - Normalized Histogram(NH)
对第一种方法的计数进行标准化,从而更关注相对信息而不是绝对数量。 - LogCount-based Histogram(LCH)
对计数值取log。
前馈匹配网络
没啥好说的,就是多层全连接。
词项门控网络(Term Gating Network)
这部分用来衡量query各个词项的重要性,也就是生成前面第三个公式中的权重g。
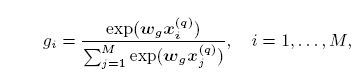
两种方法:
- Term Vector(TV)
通俗理解的话 x i x_i xi就是不同词项的词向量表示,w是一个同样维度的参数。 - Inverse Document Frequency(IDF)
x i x_i xi是每个词项的IDF值。
模型训练
利用类似triplet loss的损失函数进行训练。
![]()
对于query q, d + d^+ d+比 d − d^- d−排序更高,也就是相关性更强。
实验
数据集
选取Robust-04和ClueWeb-09-Cat-B两个数据集。
检索实验在Galago搜索引擎上展开。
评价指标
因为query数量较少,作者利用5折交叉验证减小过拟合。
作者使用了Mean average precision(MAP),normalized discounted cumulative gain at rank 20(nDCG@20),precision at rank 20(P@20)三个指标。
因为深度模型速度较慢,所以在评测时深度模型是对QL模型排序的前2000个文档进行重排序而不是对文档集全库检索,之后利用重排序的前1000篇文档作为结果进行评测。
具体的实验结果就不贴啦。