Deep Relevance Ranking Using Enhanced Document-Query Interactions阅读笔记
文章目录
- 概述
- 主要贡献
- 模型
- DRMM
- PACRR
- 论文提出的模型
- PACRR-DRMM
- Context-sensitive Term Encodings
- ABEL-DRMM(Attention-Based ELement-wise DRMM)
- POSIT-DRMM (Pooled Similarity DRMM)
- Multiple Views of Terms (+MV)
- 实验
- 评价指标
- 实验结果
- 参考链接
概述
这篇论文对DRMM模型做了一些改进,提高了模型的效果。
论文参考PACRR模型利用卷积网络提取n-gram匹配信息的做法,融合n-grams和不同方式编码的上下文信息。另外又加了一些新的策略提高模型效果。
实验证明,本文提出的模型优于BM25-baseline,DRMM和PACRR。
主要贡献
因为原始DRMM模型中直方图的构建方式并不是可微的,所以DRMM不支持端到端的训练方式。作者总共提出了以下几种基于DRMM模型的拓展方法:
- PACRR-DRMM:基于n-grams卷积的DRMM模型上下文相关的编码方式
- ABEL-DRMM:基于注意力机制的DRMM模型
- POSIT-DRMM:基于池化的DRMM模型
- 多种编码信息叠加:context sensitive, insensitive, exact matches
作者在BIOASQ生物医药QA问答集 (Tsatsaronis et al., 2015) and TREC ROBUST 2004 (Voorhees, 2005)做测试,结果表明改进后的模型比效果优于BM25-based baselines (Robertson and Zaragoza, 2009), DRMM, and PACRR。
模型
DRMM
这个模型是对DRMM模型进行改进,DRMM的结构如下图所示。
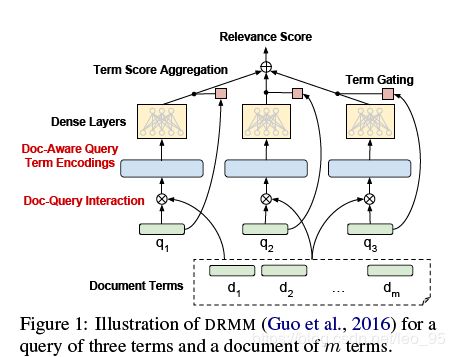
这里简单介绍下DRMM网络,详细点的介绍可以看之前写过的博客。
针对于query和document中的每个词,DRMM 使用预训练的词向量。首先对query中的每个词与doc所有词计算相似度(论文中使用了余弦距离),此处没有使用位置信息,而是将一个query对应的所有相似度进行分级(即文中说的直方图,称之为document-aware q-term encoding)。
得到document-aware q-term encoding之后,将其输入到一个全连接网络中,得到一个query词针对于一个doc的相关性分数。然后使用Term Gating Network得到权重分布(不同的词重要程度不同),在原始论文中,作者直接使用了softmax计算权重: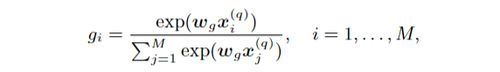
原始DRMM模型的缺点在于完全忽略了每个词的上下文信息以及词序信息,而一些新的position-aware模型例如 PACRR (Hui et al., 2017) 和基于循环神经网络的模型(Palangi et al., 2016)则考虑到这点。因此,基于DRMM模型,作者做了很多改进方法。
PACRR
论文对于DRMM的改进主要参考了PACRR的一些做法,下面简单介绍下PACRR模型。

PACRR首先根据query term embedding和doc term embedding计算词项之间的余弦距离,得到一个相似矩阵。对于不同长度的query和doc采用不同的padding策略:
- 对于不同长度的query:直接选取query集最大长度,短的query进行zero-padding
- 对于不同长度的document:原论文有两种策略,这篇论文只使用了第一种策略PACRR-firstk,即选择一个固定的k值,截长补短。
利用上述padding策略就可以得到固定维度的相似矩阵,之后利用不同大小的卷积核提取n-grams相似特征。对于每一类卷积核,输出通道为 n f n_f nf。
之后再接两个pooling层,将pooling之后的输出拼接在一起,得到一个矩阵,再加入softmax归一化后的query IDF列向量,最终得到 document-aware q-term encoding矩阵。最后直接将document-aware q-term encoding矩阵拼接成一个向量,然后再输入到全连接网络中,最终得到query与doc的相关性得分。
与DRMM模型相比,PACRR模型最大的优点在于通过n-grams的卷积对上下文建模,尽管获取的上下文信息不够直接(作者认为直接对terms embedding进行卷积比对相似度得分矩阵能够得到更强的上下文信息),而且PACRR模型是端到端可训练的。
论文提出的模型
基于DRMM,作者提出了5个新的模型对DRMM进行改进。
PACRR-DRMM
该模型借鉴PACRR的思路对DRMM进行改进,模型结构见上面Figure 2。
与PACRR模型不同的是,第四步并没有将(document-aware) q-term encodings矩阵拼接成一个向量,而是使用相同的MLP网络独立地计算每一个q-term encoding(矩阵的每一行)的分数,再通过一个线性层得到query与doc的相关性得分 。
与DRMM相比,PACRR-DRMM没有采用其gating mechanism,而是直接将IDFs的值拼接到term encoding,再通过MLP计算q-term的分数,这相当于是另一种加权的方式(作者认为这是一种shortcut passing on information,类似于残差连接)。
实验证明,PACRR-DRMM效果优于PACRR,作者认为可能是因为前者的MLP网络具有更少的参数(MLP层数相同的情况下),更不容易过拟合。
Context-sensitive Term Encodings
DRMM和PACRR模型都使用的是预训练的词向量作为term encoding,这种方式没有考虑到query term的上下文。
在接下来介绍的模型中,都是通过编码器对q-term和d-term进行上下文编码,使用的是BILSTM网络,然后在每个位置上拼接前向和后向的LSTM的隐层状态。同时,将原始的term embedding与隐层状态结合,相当于残差结构。
最终的context-sensitive term encoding表示为:

与PACRR模型相比,最大的区别在于Context-sensitive Term Encodings直接对term encoding进行上下文建模,计算的相似度分数已经包含上下文信息,而PACRR模型对相关性分数矩阵(直接由词向量得到)做n-grams卷积得到上下文信息。
ABEL-DRMM(Attention-Based ELement-wise DRMM)
网络结构如下图所示。
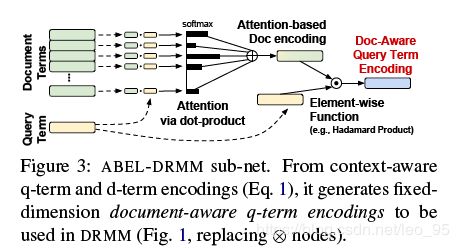
这个网络是在DRMM模型的基础上将原始DRMM模型中的直方图计算变为注意力机制,使得从term输入到最后计算query-document相关性得分整个过程可微,可以进行端到端的训练。
对于一个包含m个词项的document,首先利用向量点乘计算query每个词项和document每个词项的相似度。
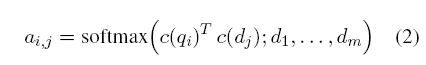
然后把词项相似度作为注意力权重和词项的context-sensitive encoding相乘加起来。
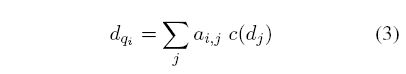
接着使用 L2正则化后的 d q i d_{q_i} dqi与L2正则化的q-term encoding进行Hadamard运算(element-wise multiplication),得到document-aware q-term encoding,代替DRMM模型中的直方图:
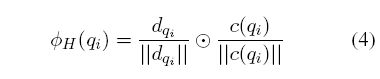
和DRMM模型一样,ABEL-DRMM模型与文档长度无关,但是可以端到端训练。
POSIT-DRMM (Pooled Similarity DRMM)
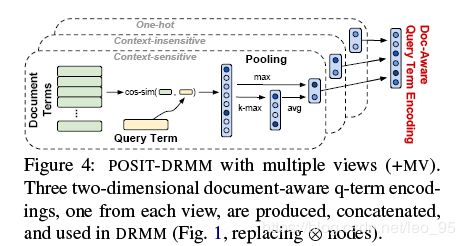
与ABEL-DRMM不同,POSIT-DRMM使用余弦相似度计算每个q-term相对于所有d-terms的注意力分数:

然后并没有像在ABEL-DRMM模型那样使用加权求和,而是直接将所有的 a i , j a_{i,j} ai,j直接拼接在一起:

之后通过两个pooling层,max-pooling返回的是 [公式] 与doc最相关匹配的信息,而avg-pooling返回的是 q i q_i qi与doc前top-k最相关匹配的平均信息:
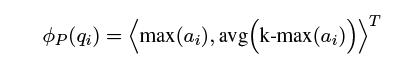
POSIT-DRMM模型比其他模型的参数更少,因为全连接网络的输入维度只是一个长度为2的向量,而ABEL-DRMM与term embedding的长度相同。因此,POSIT-DRMM模型的全连接网络只需要一层。
Multiple Views of Terms (+MV)
这个模型使用多种term encoding对ABEL-DRMM和POSIT-DRMM进行改进。
上节介绍的最基础的POSIT-DRMM模型对于query每个词项利用context-sensitive encoding最终生成一个2维的向量。作者另外又补充了两种term encoding:
- 不用lstm编码,直接使用预训练词向量。
- 使用one-hot向量
这样每种encoding生成一个2维向量,拼接成6维的document-aware q-term encodings向量。
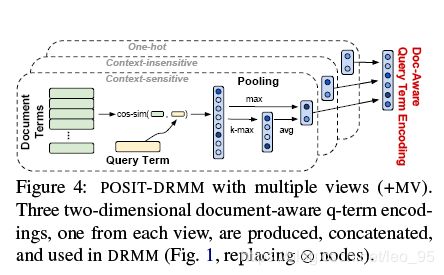
对于ABEL-DRMM也采用类似的multiple views策略进行改进。
实验
为了避免待匹配的文档数过多,先使用Galago检索系统利用BM25分数对文档进行初步检索,之后使用深度模型对前N篇文档进行重排序。
评价指标
- Mean average precision(MAP)
- Precision@20
- nDCG@20
实验结果

参考链接
Enhanced DRMM检索模型阅读笔记