Haar+Adaboost 车辆检测 目标检测(视频车辆检测算法代码)
正样本:http://download.csdn.net/detail/zhuangxiaobin/7326197
负样本:http://download.csdn.net/detail/zhuangxiaobin/7326205
训练和检测工具:http://download.csdn.net/detail/zhuangxiaobin/7414793
分类器xml文件:http://download.csdn.net/detail/zhuangxiaobin/7553415
adaboost训练和测试源代码:http://download.csdn.net/detail/zhuangxiaobin/7590517
在开始阅读之前,建议先把这几个用到的资料先下载了,有不少网友想要训练的代码,我没有直接提供,所以也不必私信我提供代码了。如果非要弄懂整个过程的话,有两种途径。一种是通过cmake opencv查看源代码(事实上本工具也是通过这种途径得到的),另一种就是下载adaboost训练和测试的源代码然后自己可以选择自己想要的特征,这对于想做特征融合的网友是比较有帮助的,算法的介绍可以通过点击这里查看。
本文章的目的是让所有在数字图像处理零经验的同学可以快速实现运动目标跟踪。
opencv自带了一个人脸识别用到的分类器,我们直接使用就行了。但是很多人想到要跟踪其他东西,例如说,手,杯子,篮球,汽车,那怎么办?其实很简单,只要按照一下步骤一步一步做,很容易就可以做到了。运动目标识别,用上这个工具,貌似都不是什么难事。(好像在卖广告了。。)回到正题,本文用的是haar+adaboost的方法。
目标检测分为三个步骤:
1、 样本的创建
2、 训练分类器
3、 利用训练好的分类器进行目标检测。
一.样本的创建:
训练样本分为正例样本和反例样本。正例样本是指待检目标样本(例如可乐瓶,汽车,人脸等),反例样本指其它任意图片,所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。反例样本可以来自于任意的图片,但这些图片不能包含目标特征。
正样本:
1.先准备正样本图片。
进入路径tools\temp\positive\rawdata(我的路径是F:\tools\temp\positive\rawdata,你按照你自己的路径对应的改过来就行了),然后在里面放入含有正样本的图片。当然了,正样本数目要要足够大,一般要是1000以上吧。注意,图片要用BMP格式,如果你手头上的图片不是BMP格式的话,只需要用图片处理软件转一下就行了。如下图所示:

2.截图目标区域。
正样本图片有了,然后双击F:\tools\temp\positive下的objectmarker.exe,开始截图目标区域,有readme文件已经说明了,也就是说,每次截图完要按一次空格键保存区域,多目标的图片可以接着继续截图,按下回车键可以跳到写一张图片:
The following keys are used:
这个过程要持续下去不能中断,不然的话就无法产生相应的文件了,所以在样本太多的情况下,可以先分组,大约100张图片放进去rawdata中去,这样子如果有什么意外的话,损失也就100张图的时间而已。只需要最后把几个文件合成一个大文件,效果就一样了。最后可以在F:\tools\temp\positive下生成info.txt文件。
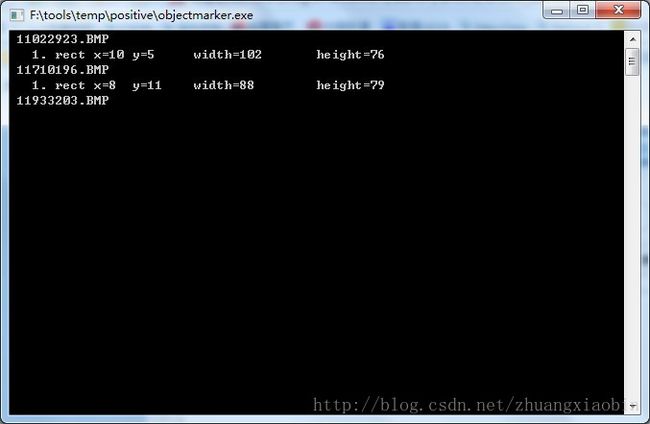

例子:
rawdata/11022923.BMP 1 11 5 100 78
这里,rawdata/11022923.BMP表示文件的相对路径;
1 表示有一个目标(如果图片中有两个目标的话,截两次图,这里就是2了,以此类推;
11 5 表示目标矩形框起点坐标;
100 78 表示目标矩形框的宽和高。
3.正样本描述文件vec文件的创建。
已经把目标的情况记录了放在txt文件里,接下来就编辑F:\tools下的samples_creation.bat文件,因为正样本数是8个(我这里是8个),所以改成createsamples.exe -info positive/info.txt -vec data/vector.vec -num 8 -w 24 -h 24这句话的-num 后面写个8就行了,后面的-w 和 -h 说的是图片resize成的大小,根据你的需要自己改。之后会在F:\tools\temp\data下面生成vector.vec文件,这个就是向量描述文件了。

到此,正样本的操作已经完成了,不用打开vec文件,因为这个要专门的软件才可以打开的。
负样本:
1.准备负样本图片。
到F:\tools\temp\negative下,把负样本图片放进去。一般来说,负样本要比正样本数目多很多。为什么呢?因为负样本表示的是随机情况,只要有大量随机样本的情况下,才可以充分表示与正样本相反的情况,大约2-5倍吧,也不能太多,不然的话花费的时间太长,分类效果可能反而不好,因为比例偏移太严重了

2.负样本描述文件的生成。
打开F:\tools\temp\negative下的create_list.bat文件,可以自动生成描述文件。如果没有找到这个create_list.bat批出处理文件,就自己在这个目录下新建一个,内容就一句话:dir /b *.BMP >infofile.txt,然后保存。
infofile.txt文件内容如下为例(注意负样本也是bmp文件):
172328267.BMP
172328277.BMP
172328457.BMP
172328467.BMP
172328747.BMP
172328957.BMP
172328967.BMP
172329137.BMP
172329147.BMP
172329347.BMP
172329517.BMP
.............

到此,负样本的操作结束。
二.进入训练阶段:
打开F:\tools下的haarTraining.bat,开始训练了(注意:下载到的训练和测试工具里haarTraining.bat文件内容不一定适合你的实际情况,注意按照下面的参数说明修改参数,特别是 -npos 20 -nneg 40 -nstages 5!!)。该文件参数说明如下:
-data data/cascade -vec data/vector.vec -bg negative/infofile.txt -npos 20 -nneg 40 -nstages 5 -mem 1000 -mode ALL -w 24 -h 24 -nonsym
-data
存放训练好的分类器的路径名。
-vec
正样本文件名(由trainingssamples 程序或者由其他的方法创建的)
-bg
背景描述文件。
-npos
-nneg
用来训练每一个分类器阶段的正/负样本。合理的值是:nPos = 7000;nNeg = 3000
-nstages
训练的阶段数。
-nsplits
决定用于阶段分类器的弱分类器。如果1,则一个简单的stump classifier 被使用。如果是2 或者更多,则带有number_of_splits 个内部节点的CART 分类器被使用。
-mem
预先计算的以MB 为单位的可用内存。内存越大则训练的速度越快。
-sym(default)
-nonsym
指定训练的目标对象是否垂直对称。垂直对称提高目标的训练速度。例如,正面部是垂直对称的。
-minhitrate《min_hit_rate》
每个阶段分类器需要的最小的命中率。总的命中率为min_hit_rate 的number_of_stages 次方。
-maxfalsealarm
没有阶段分类器的最大错误报警率。总的错误警告率为max_false_alarm_rate 的number_of_stages 次方。

训练过程会在F:\tools\temp\data\cascade中产生相应阶段的文件。训练时间和电脑配置和训练数据的多少有关。如果在这个过程中中断了也没关系,再次启动训练可以接着训练下去的。(ctrl+c可以退出)。我的配置是CPU:i5-480M,内存2G,正样本2500,负样本4500,大概从下午4点到第二天早上7点吧,生成18级。速度比其他博客上写的要快很多,有的网友竟然有用了6天的,我就搞不懂了。。。可能数据是在太大了吧。如果发现训练着程序不再动了,那么不到18级也可以停止了。生成18级的阶段性分类器文件之后,把\temp\data\cascade下的n(这里n=18)个弱分类器文件夹拷贝到cascade2xml\data下,用F:\tools\cascade2xml下的convert.bat就可以生成xml分类器文件了。默认在同级目录下生成output.xml,当然了,你也可以改~~
三、检测
生成分类器之后,就可以启用F:\tools\test_recognition下的facedetect.exe文件了,至于文件路径什么的,自己结合实际修改一下,就是要把这个output.xml作为分类器文件输入就是了。
例如:start.bat中
facedetect.exe --cascade="dane.xml" 0
就是使用F:\tools\test_recognition下的dane.xml文件,媒体文件来源是摄像头,你要用视频,就改为类似于xxx.avi或者其他路径就行了。

其实这个facedetect.exe 是有源代码的,你可以自己去opencv 自带的代码里面找,我这里也贴出来了。
本博客涉及到的资源:
正样本:http://download.csdn.net/detail/zhuangxiaobin/7326197
负样本:http://download.csdn.net/detail/zhuangxiaobin/7326205
训练和检测工具:http://download.csdn.net/detail/zhuangxiaobin/7414793
分类器xml文件:http://download.csdn.net/detail/zhuangxiaobin/7553415
我在正样本和训练工具设置了下载积分是1,一方面是正样本的制作是在太耗我时间了,另一方面实在是因为我穷苦太久,对积分十分渴望。ps:请原谅我的庸俗,呵呵~
我把检测视频也共享出来了,http://pan.baidu.com/s/1pJ6s0rx
如果觉得可以的话,请在下面顶一下吧~~
除了本文提供的资源之外,不再提供任何其他相关资源,自己去找,不必私信我索要。
-
#include "cv.h"
-
#include "highgui.h"
-
#include
-
#include
-
#include
-
#include
-
#include
-
#include
-
#include
-
#include
-
#include
-
static CvMemStorage* storage = 0;
-
static CvHaarClassifierCascade* cascade = 0;
-
void detect_and_draw( IplImage* image );
-
const char* cascade_name =
-
"haarcascade_frontalface_alt.xml";
-
int main( int argc, char** argv )
-
{
-
CvCapture* capture = 0;
-
IplImage *frame, *frame_copy = 0;
-
int optlen = strlen("--cascade=");
-
const char* input_name;
-
if( argc > 1 && strncmp( argv[1], "--cascade=", optlen ) == 0 )
-
{
-
cascade_name = argv[1] + optlen;
-
input_name = argc > 2 ? argv[2] : 0;
-
}
-
else
-
{
-
fprintf( stderr,
-
"Usage: facedetect --cascade=\"
\" [filename|camera_index]\n" ); -
return -1;
-
-
}
-
cascade = (CvHaarClassifierCascade*)cvLoad( cascade_name, 0, 0, 0 );
-
if( !cascade )
-
{
-
fprintf( stderr, "ERROR: Could not load classifier cascade\n" );
-
return -1;
-
}
-
storage = cvCreateMemStorage(0);
-
if( !input_name || (isdigit(input_name[0]) && input_name[1] == '\0') )
-
capture = cvCaptureFromCAM( !input_name ? 0 : input_name[0] - '0' );
-
else
-
capture = cvCaptureFromAVI( input_name );
-
cvNamedWindow( "result", 1 );
-
if( capture )
-
{
-
for(;;)
-
{
-
if( !cvGrabFrame( capture ))
-
break;
-
frame = cvRetrieveFrame( capture );
-
if( !frame )
-
break;
-
if( !frame_copy )
-
frame_copy = cvCreateImage( cvSize(frame->width,frame->height),
-
IPL_DEPTH_8U, frame->nChannels );
-
if( frame->origin == IPL_ORIGIN_TL )
-
cvCopy( frame, frame_copy, 0 );
-
else
-
cvFlip( frame, frame_copy, 0 );
-
detect_and_draw( frame_copy );
-
if( cvWaitKey( 10 ) >= 0 )
-
break;
-
}
-
cvReleaseImage( &frame_copy );
-
cvReleaseCapture( &capture );
-
}
-
else
-
{
-
const char* filename = input_name ? input_name : (char*)"lena.jpg";
-
IplImage* image = cvLoadImage( filename, 1 );
-
if( image )
-
{
-
detect_and_draw( image );
-
cvWaitKey(0);
-
cvReleaseImage( &image );
-
}
-
else
-
{
-
-
FILE* f = fopen( filename, "rt" );
-
if( f )
-
{
-
char buf[1000+1];
-
while( fgets( buf, 1000, f ) )
-
{
-
int len = (int)strlen(buf);
-
while( len > 0 && isspace(buf[len-1]) )
-
len--;
-
buf[len] = '\0';
-
image = cvLoadImage( buf, 1 );
-
if( image )
-
{
-
detect_and_draw( image );
-
cvWaitKey(0);
-
cvReleaseImage( &image );
-
}
-
}
-
fclose(f);
-
}
-
}
-
}
-
cvDestroyWindow("result");
-
return 0;
-
}
-
void detect_and_draw( IplImage* img )
-
{
-
int scale = 1.3;
-
IplImage* temp = cvCreateImage( cvSize(img->width/scale,img->height/scale), 8, 3 );
-
CvPoint pt1, pt2;
-
int i;
-
-
cvClearMemStorage( storage );
-
if( cascade )
-
{
-
CvSeq* faces = cvHaarDetectObjects( img, cascade, storage,
-
1.1, 3, CV_HAAR_DO_CANNY_PRUNING,
-
cvSize(20, 20) );
-
for( i = 0; i < (faces ? faces->total : 0); i++ )
-
{
-
CvRect* r = (CvRect*)cvGetSeqElem( faces, i );
-
pt1.x = r->x*scale;
-
pt2.x = (r->x+r->width)*scale;
-
pt1.y = r->y*scale;
-
pt2.y = (r->y+r->height)*scale;
-
cvRectangle( img, pt1, pt2, CV_RGB(255,0,0), 3, 8, 0 );
-
}
-
}
-
cvShowImage( "result", img );
-
cvReleaseImage( &temp );
转载:http://blog.csdn.net/zhuangxiaobin/article/details/25476833