spark 10分钟计算一次mongodb当天日志数据,日志为字符串格式,按订单号去重,取时间最近的订单,优化方案
spark 10分钟计算一次mongodb当天日志数据,日志为字符串格式,按订单号去重,取时间最近的订单,优化方案
问题:解析字符串,构建spark dataframe结果集,全量去重,数据量过多,解析复杂,导致从早上1分钟到晚上30分钟才能跑完一次任务。
spark streaming的接收源一般是推来的,不像kafka会推过来,然后再根据偏移量来记录刻度,
优化方案:按小时去清理数据,把解析好的数据存起来,再进行全量去重和相关统计运算。相当于是把小时当作读mongo当天的刻度=kafka偏移量
例: 2:10->拉上一小时(1点)的数据,2:20->拉2点+的数据, 2:30->拉2点+的数据
优化完后,大约是在1-3分钟跑完一次任务,很OK了,后面改直接接入kafka推的方式,这样有个问题就是全量去重的问题,就要做个有状态的数据存储集,这个可能要暂很大内存,看数据量多少了。
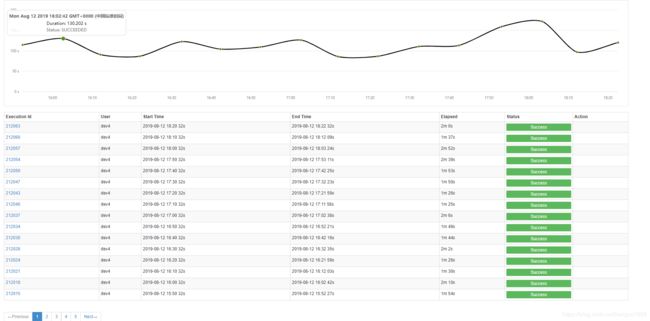
优化 后跑的时间调度:
解析日志:
package biReportJob.zt
import java.text.SimpleDateFormat
import java.util.{Calendar, Locale}
import common.{StreamingLog, getEnv}
import org.apache.commons.lang3.StringUtils
import org.apache.log4j.{Level, Logger}
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{SaveMode, SparkSession}
import scripts.mongoEtls_zt.ZtLxjETLDailyPushOrder.dataExtractRegexStr
import scala.util.parsing.json.JSON
/**
* Created by Roy on 2019/7/20
* 准时实统计订单相关数据
*
* pushOrder
* *
* 1、统计用orderId做去重治理
* *
* 2、如果extId为空,则用orderNo补上(即extid=orderNo)
* 订单日期:orderDate
* 金额: price
*
* pos
* 订单日期:createTime
* 金额:merchantPrice
*
* 会员信息
* candao.member.postMemberInformation
* registerTime
*/
object SolidTimeStatJobReadData extends Logging {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// val dataExtractRegexStr = "(http?://[^\"]*=\\{)"
def main(args: Array[String]): Unit = {
val Array(day_hh) = (args ++ Array(null)).slice(0, 1)
val remoteMongoUri = common.RemoteMongoSettings()
StreamingLog.setStreamingLogLevels()
logWarning("日志调试:" + remoteMongoUri.getProperty("ztUri"))
val dateFormate: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd", Locale.US)
val logtable: SimpleDateFormat = new SimpleDateFormat("yyyyMMdd", Locale.US)
val cal = Calendar.getInstance
val max_time: Long = cal.getTime.getTime / 1000
val sparkBuilder = SparkSession.builder()
if ("local".equals(getEnv("env"))) { //FIXME:调式用
sparkBuilder.master("local[*]").config("hive.metastore.uris", "thrift://hdp02:9083")
cal.set(Calendar.YEAR, 2019)
cal.set(Calendar.MONTH, 0)
cal.set(Calendar.DATE, 18)
// cal.set(Calendar.HOUR_OF_DAY, 0)
}
val spark = sparkBuilder.appName("SolidTimeStatJob")
.config("spark.mongodb.input.uri", remoteMongoUri.getProperty("ztUri"))
.config("spark.mongodb.input.database", remoteMongoUri.getProperty("ztDatabase"))
.config("spark.mongodb.input.collection", "c").enableHiveSupport()
.getOrCreate()
val dt_day = dateFormate.format(cal.getTime)
val table1 = logtable.format(cal.getTime)
var c_hour = new SimpleDateFormat("HH", Locale.US).format(cal.getTime)
// var c_min = new SimpleDateFormat("mm", Locale.US).format(cal.getTime) //分
val c_minute = cal.get(Calendar.MINUTE)
println("c_hour " + c_hour)
var c_date = dateFormate.format(cal.getTime)
var c_date_hhmmss = c_date + " " + c_hour + ":00:00"
var c_date_end = dateFormate.format(cal.getTime) + " 23:59:59"
if (StringUtils.isNotBlank(day_hh) && "99".equals(day_hh)) {
c_hour = "00"
} else if (!c_hour.equals("00") && c_minute < 10) {
// cal.add(Calendar.MINUTE, -30)
//如果不是0点,并且分钟小于10,就算上一小时的数据
cal.add(Calendar.HOUR_OF_DAY, -1)
c_hour = new SimpleDateFormat("HH", Locale.US).format(cal.getTime)
c_date_end = dateFormate.format(cal.getTime) + " " + c_hour + ":59:59"
//
c_date_hhmmss = c_date + " " + c_hour + ":00:00"
}
var mongodbQueryTime = "'createTime':{'$gte':'" + c_date_hhmmss + "','$lte':'" + c_date_end + "'}"
println("env=" + getEnv("env") + "dt_day=" + dt_day + " mongodbQueryTime=" + mongodbQueryTime + " query_start_hour=" + c_hour + " tables=" + table1)
val m_sql = "[{$match:{'actionName':{$in: ['candao.order.postOrder', 'candao.order.pushOrder']},'flag':1,"+mongodbQueryTime+"}},{'$project':{msg:1}}]"
val tableRdd1 = spark.read.format("com.mongodb.spark.sql.DefaultSource").option("pipeline", m_sql).option("collection", s"log$table1").load()
val jsonMsg = tableRdd1.rdd.map(row => {
// val screateTime = row.getAs[String]("createTime")
// println("screateTime===" + screateTime)
val msg = row.getAs[String]("msg")
if (StringUtils.isNotBlank(msg)) {
val jsonMsg = "{" + msg.replaceFirst(dataExtractRegexStr, "")
val jsonMap = JSON.parseFull(jsonMsg).get.asInstanceOf[Map[String, Any]]
val msgData = jsonMap.get("data").get.asInstanceOf[Map[String, Any]]
val actionName = jsonMap.getOrElse("actionName", "")
var orderMoney = 0.0
var orderNo = ""
var otype = -1
var orderId = ""
var orderDate = "20180102"
if (actionName.equals("candao.order.postOrder")) {
orderMoney = msgData.getOrElse("merchantPrice", 0.0).asInstanceOf[Double]
otype = 1
//extid,补上orderId,做统一去重用
orderId = "1" + msgData.getOrElse("extId", "").toString
// orderDate = msgData.getOrElse("orderDate", "20180101").toString
orderDate = msgData.getOrElse("createTime", "20180101").toString.substring(0, 8)
} else if (actionName.equals("candao.order.pushOrder")) {
orderMoney = msgData.getOrElse("price", 0.0).asInstanceOf[Double] //price
orderNo = msgData.getOrElse("orderNo", "").toString //price
orderId = "2" + msgData.getOrElse("orderId", "").asInstanceOf[Double].toInt.toString
orderDate = msgData.getOrElse("orderDate", "20180101").toString.substring(0, 10).replace("-", "")
otype = 2
}
val extId = msgData.getOrElse("extId", "").toString
val extOrderId = msgData.getOrElse("extOrderId", "").toString
val extStoreId = msgData.getOrElse("extStoreId", "").toString
val stype = msgData.getOrElse("type", -899.0).asInstanceOf[Double].toInt
val payType = msgData.getOrElse("payType", -899.0).asInstanceOf[Double].toInt
val orderStatus = msgData.getOrElse("orderStatus", -899.0).asInstanceOf[Double].toInt
val createTime = msgData.getOrElse("createTime", 899).toString.toLong
// val createTime =screateTime
val postEntity = new PosStoreEntity2(extId, extOrderId, extStoreId, stype, payType, orderMoney, orderStatus, orderDate, createTime, otype, orderNo, orderId, max_time, c_hour)
postEntity
} else {
null
}
}).filter(row => {
row != null
})
import spark.implicits._
// jsonMsg.cache()
// if (jsonMsg.take(1).length <= 0) {
// println("无postPustData数据 exit")
// System.exit(-1)
// }
val jsonMsgDF = jsonMsg.toDF()
if ("99".equals(day_hh) || c_hour.equals("00")) {
println("all table overwrite")
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
jsonMsgDF.write.mode(SaveMode.Overwrite).partitionBy("parth").saveAsTable("zt.solid_time_order_data")
} else {
spark.conf.set(
"spark.sql.sources.partitionOverwriteMode", "dynamic"
)
jsonMsgDF.write.mode(SaveMode.Overwrite).insertInto("zt.solid_time_order_data")
}
spark.stop()
}
}
case class PosStoreEntity2(extId: String, extOrderId: String, extStoreId: String, stype: Int, payType: Int, orderMoney: Double, orderStatus: Int, orderDate: String, createTime: Long, otype: Int, orderNo: String, orderId: String, jobTime: Long, parth: String)
计算解析好的数据
package biReportJob.zt
import java.sql.DriverManager
import java.text.SimpleDateFormat
import java.util.{Calendar, Locale}
import common.getEnv
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
object SolidTimeStatJobReduceData {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val sparkBuilder = SparkSession.builder()
val dateFormate: SimpleDateFormat = new SimpleDateFormat("yyyyMMdd", Locale.US)
val cal = Calendar.getInstance
// val max_time: Long = cal.getTime.getTime / 1000
if ("local".equals(getEnv("env"))) { //FIXME:调式用
sparkBuilder.master("local[*]").config("hive.metastore.uris", "thrift://hdp02:9083")
cal.set(Calendar.YEAR, 2019)
cal.set(Calendar.MONTH, 6)
cal.set(Calendar.DATE, 18)
}
val stat_day = dateFormate.format(cal.getTime)
println("stat_day===" + stat_day)
val spark = sparkBuilder.appName("SolidTimeStatJobReduceData")
// .config("spark.cleaner.referenceTracking.cleanCheckpoints", "true")
.enableHiveSupport().getOrCreate()
spark.sparkContext.setCheckpointDir("user/spark/scheckpoints/")
spark.conf.set("spark.cleaner.referenceTracking.cleanCheckpoints","true")
val DF1 = spark.sql(
s"""
|select t1.* from (
|select *, row_number() over(partition by orderId ORDER BY createTime desc) rn
|from zt.solid_time_order_data where orderDate='$stat_day'
|) t1 where t1.rn=1
""".stripMargin)
// DF1.show()
DF1.createOrReplaceTempView("table_tmp_1")
val sql2 =
s"""
|select orderDate,extStoreId,otype,max(jobtime) jobtime,count(1) orderNum,round(sum(orderMoney),4) orderMoney from table_tmp_1
|group by orderDate,extStoreId,otype
""".stripMargin
val DF2 = spark.sql(sql2)
DF2.createOrReplaceTempView("result_left_city_tmp")
spark.sqlContext.setConf("spark.sql.crossJoin.enabled", "true")
val resultCityDF = spark.sql(
"""
|select t1.*,t2.provinceid,t2.provincename,t2.cityid,t2.cityname,t2.storename from result_left_city_tmp t1
|left join zt.lxj_store t2
|on t1.extStoreId=t2.extstoreid
""".stripMargin)
resultCityDF.cache()
resultCityDF.checkpoint()
println("resultCityDF shwo==========")
// resultCityDF.show()
if (!resultCityDF.take(1).isEmpty) {
savedb(resultCityDF)
}
spark.stop()
}
def savedb(dataDF: DataFrame): Unit = {
val (user, passwd, url) = common.LocalMysqlSettings("finereport.user", "finereport.passwd", "finereport.url", "finereportmysql.properties")
println("mysql url==" + url)
val insertSql =
"""
|INSERT INTO lxj_order_theday_board (`provinceid`, `provincename`, `cityid`, `cityname`,`orderDate`, extStoreId,`orderNum`, `orderMoney`, `dt_time`,otype,storename)
| VALUES (?,?,?,?,?,?,?,?,?,?,?)
""".stripMargin
val conn = DriverManager.getConnection(url, user, passwd)
conn.setAutoCommit(false)
try {
val truncatesql = conn.prepareStatement("delete from lxj_order_theday_board")
// val truncatesql = conn.prepareStatement("TRUNCATE lxj_order_theday_board")
truncatesql.execute()
val dataps = conn.prepareStatement(insertSql)
val list = dataDF.rdd.collect().toList
// println("list prin=" + list)
list.foreach(unit => {
dataps.setInt(1, unit.getAs[Int]("provinceid"))
dataps.setString(2, unit.getAs[String]("provincename"))
dataps.setInt(3, unit.getAs[Int]("cityid"))
dataps.setString(4, unit.getAs[String]("cityname"))
dataps.setString(5, unit.getAs[String]("orderDate"))
dataps.setString(6, unit.getAs[String]("extStoreId"))
dataps.setLong(7, unit.getAs[Long]("orderNum"))
dataps.setDouble(8, unit.getAs[Double]("orderMoney"))
dataps.setInt(9, unit.getAs[Long]("jobtime").toInt)
dataps.setInt(10, unit.getAs[Int]("otype"))
dataps.setString(11, unit.getAs[String]("storename"))
dataps.addBatch()
})
dataps.executeBatch()
conn.commit()
} catch {
case e: Exception => {
e.printStackTrace()
println(e)
conn.rollback()
throw new Exception("mysql error =" + e.getMessage)
}
} finally {
conn.close()
}
}
}