【MOOC】Python网络爬虫与信息提取-北京理工大学-part 1
【第〇周】网络爬虫之前奏
课程推荐阅读文章:关于反爬虫,看这一篇就够了
网络爬虫”课程内容导学
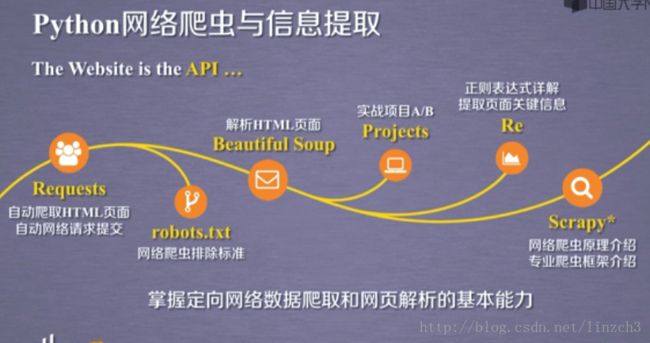

【第一周】网络爬虫之规则
1.Requests库入门
Requests库英文文档:Requests: HTTP for Humans
Requests库中文文档:Requests: 让 HTTP 服务人类
注意:中文文档的内容要稍微比英文文档的更新得慢一些,参考时需要关注两种文档对应的Requests库版本。(对于比较简单的使用方法,我们看中文的就行了)
Requests库的7个主要方法:

注:这7的方法的后面6个都是由requests.request()函数封装的。
get方法的使用
对于代码r=requests.get(url),r为函数返回的Response 对象,该对象包含爬虫返回的内容。
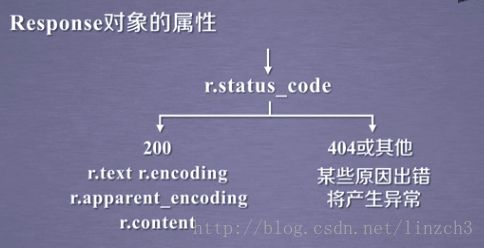
Response 对象的属性:

这5个属性的使用流程:
例子:
>>> import requests
>>> r=requests.get('http://www.baidu.com')
>>> r.status_code
200
>>> r.text
'\r\n ç\x99¾åº¦ä¸\x80ä¸\x8bï¼\x8cä½\xa0å°±ç\x9f¥é\x81\x93 å\x85³äº\x8eç\x99¾åº¦ About Baidu
©2017 Baidu 使ç\x94¨ç\x99¾åº¦å\x89\x8då¿\x85读 æ\x84\x8fè§\x81å\x8f\x8dé¦\x88 京ICPè¯\x81030173å\x8f· 
\r\n'
可以看到,r.text里面的东西都是乱码。查看编码方式:
>>> r.encoding
'ISO-8859-1'
>>> r.apparent_encoding
'utf-8'可以这样理解编码:网络上的资源都有编码,没有适当的编码,我们就看不懂里面的内容。
将编码方式改为:utf-8,可以发现,r.text已经显示为我们可读的内容了。
>>> r.encoding='utf-8'
>>> r.text
'\r\n 百度一下,你就知道 \r\n'
关于r.encoding和r.apparent_encoding的区别:

如何理解“如果header中不存在charset”:通常我们得到的网页都是由某个角落的一个服务器“发出”的,而有些服务器对网页的编码有要求,其所用的编码就会保存在网页header中的charset,而如果没有charset,那么Respond对象的编码就默认为ISO-8859-1。
从上面的那张图片也可以看到,r.apparent_encoding是根据网页内容“实实在在”地分析出来的编码方式,因此其比r.encoding显得更为靠谱。
爬取网页的通用代码框架
在使用get方法获得网页的时候,由于网络连接可能不稳定,所以在使用该方法时需要编写“异常处理”的代码。
requests库常用的异常:

requests库中的raise_for_status函数可以帮助我们处理常用的异常:

通用代码框架:

测试:

HTTP协议和requests库方法
重新看到Requests库的7个主要方法,后面6个一一对应HTTP的相关方法。
下面接介绍HTTP协议:

注:
1.“请求与响应”:用户端发出请求,服务器做出响应。
2.“无状态”:用户端这次发出的请求和下一次发出的没有联系
3.“应用层协议”:该协议工作在HTTP协议之上
常用URL格式:

HTTP协议对资源的操作:

可以把网络上的数据的所在位置是:云端,我们可通过get、head操作从云端获取数据(可以理解为文件的读操作),可通过put、post、patch、delete操作对数据进行修改(可以理解为文件的写操作)
举例:



requests库主要方法解析
这里将对requests库的几个主要方法的使用方法进行介绍。
对于request函数:


kwargs的13个参数如下:





注:模拟浏览器或者手机访问网页的方法就是通过headers参数实现的


注:使用file参数可以向服务器提交文件

注:当服务器的响应时间大于timeout值时,request函数会返回超时异常。
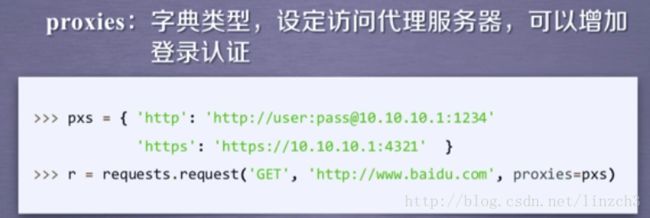
注:使用这个参数可以有效地隐藏我们真正的IP地址,可有效地防止爬虫的逆追踪

对于get函数

这里的kwargs和上面的request函数的是一样的。
前面提高,get、head、post、patch、delete、put这几个函数都是由request函数定义的,对于进行需要用到的参数,为了方便使用,这些新定义的函数就将这些参数“显式化”了。
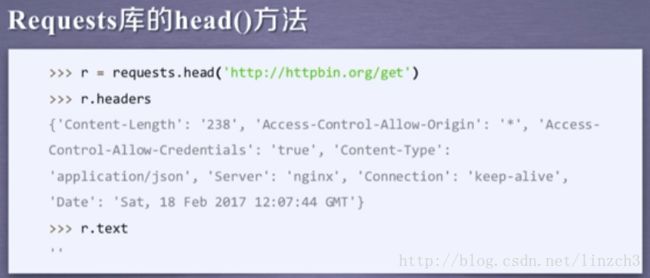
对于head函数

对于post函数

对于patch函数

对于delete函数

单元小结
看了这么多的使用方法,实际上get方法就是最常用的。对于某些比较复杂的工程,head方法的使用仅次于get,因此重点掌握这两个方法即可。
讨论
尽管Requests库功能很友好、开发简单(其实除了import外只需一行主要代码),但其性能与专业爬虫相比还是有一定差距的。请编写一个小程序,“任意”找个url,测试一下成功爬取100次网页的时间。(某些网站对于连续爬取页面将采取屏蔽IP的策略,所以,要避开这类网站。)
请回复代码,并给出url及在自己机器上的运行时间。
代码:
import requests
import time
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print("Failed")
if __name__ == "__main__":
url = "https://www.baidu.com"
startTime = time.time()
for i in range(100):
getHTMLText(url)
endTime = time.time()
print("the total time is %fs" %(endTime-startTime))输出结果:
the total time is 14.201600s2.网络爬虫的“盗亦有道”
网络爬虫引发的问题
首先看网络爬虫的尺寸分类:




robot协议

例子:

其他例子:

注:若一个网站没有robots协议,那么可认为该网站可被爬虫无限制地爬取。
robot协议的遵守方式


而若我们的爬虫程序获取网站信息的频率和人类的相似的话,比如一小时获取一次,这个时候可以不遵守该协议,毕竟对服务器没有造成过度的压力。
单元小结
pass
requests库网络爬虫实战(5个实例)
1.京东商品信息的爬取:

2.亚马逊商品页面的爬取:
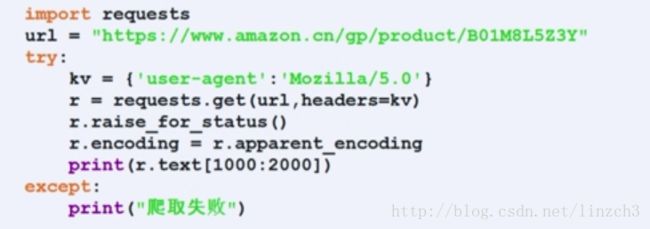
与上一个例子不同的是:这里需要修改headers以让程序模拟浏览器获取数据。
注意:这里的调试方法可以参考,可输出r.request.headers查看headers
3.百度/360搜索关键词提交
搜索引擎关键词提交接口如下,可以发现只要替换了keyword这个关键词就可以实现关键词的提交了。



4.网络图片的爬取和存储

例子:
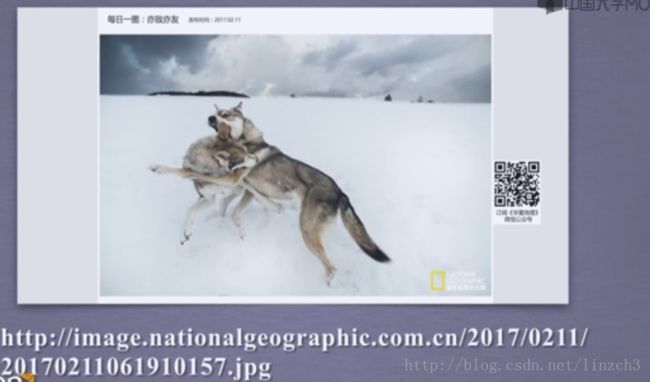
简单版本:
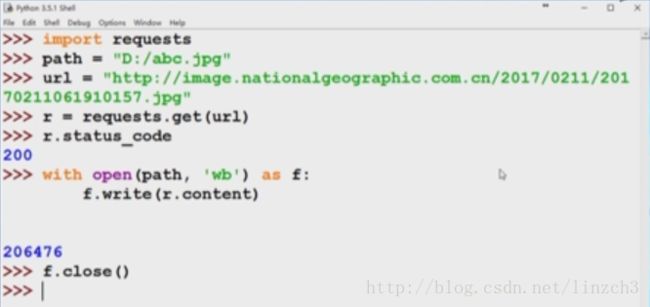
详细版本(相比上面的代码,这份代码显得更加稳定):

注:这份代码的with…as….语句中的f.close()可以不用加上,该语句会进行相关的文件关闭的处理的。
5.IP地址归属地查询
首先,寻找可查询IP地址的接口,发现在www.ip138.com上有这个接口。通过测试,可发现ip地址查询的接口(下图下方的链接):类似于上一个例子,只要替换ipaddress这个关键词就可以实现ip地址的查询了。

下面是测试交互界面和对应代码:
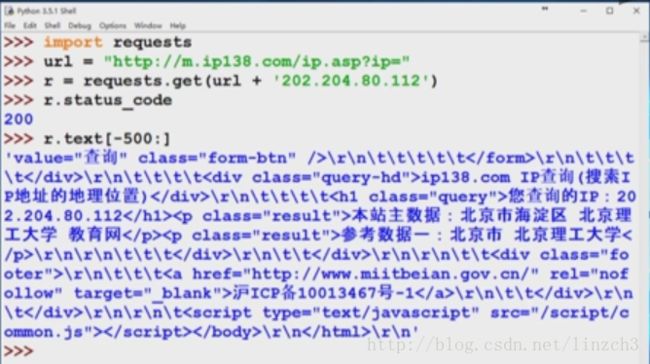

注:这里输出respond对象的内容的时候,都是取r.text的一部分的内容的,而若直接输出r.text的所有内容,可能会引起对应IDE的失效(或者 输出负担过大)。
而通过这个例子,也可以发现,对于一些可通过用户输入的信息来进行相应的相应的响应的网站,都可以找到其对应的API,从而可用爬虫程序进行自动的信息填入和自动地根据信息来进行相应的处理。比如,对于这一个例子,其API就是:
![]()
而这也是“以爬虫视角看待网络内容”的表现方式之一。
代码:
# -*- coding:utf-8 -*-
import requests
def getHTMLText(url):
try:
kv = {'ip': '120.236.174.140'}
r = requests.get(url,params=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.url)
return r.text
except:
print("Failed!")
url = "http://www.ip138.com/ips138.asp"
print(getHTMLText(url))单元小结
pass