神经网络 和 NLP —— Cascaded, Multi-task and Semi-supervised Learning
当初入门 NLP 读的《Netural Network for Natural Language Processing》,收获颇丰。入门后,改成了读 paper 和 code,没有完整读完这本书,最近得空,把后几章补上,算是完整吧。
不少内容在读 paper 时,已经深入了解过,这里就简单带过了,感兴趣的建议精读原书和参考文献吧。
本文介绍串联学习、多任务学习、半监督学习。
1 Cascaded learning
在 NLP 中,有时需要顺序处理多个 task,即前一个 task 的预测作为下一个 task 的输入,当这两个 task 独立时,相当于 pipeline 系统,称之为 cascaded learning。
实际上,我们并不会直接把前一个任务的最终预测输入到后一个任务中,这样可能造成错误级联。通常,我们将前一个任务的富含本任务信息的带有不确定性的中间结果(如 softmax 前的隐层)输入到后一个任务中。
例如,pos 任务与 syntactic chunking or parsing 任务可以串联:

(1)在 pos 的 biRNN+MLP 网络后 pre-prediction state 将喂入后面 biRNN 的 sp 网络,虽然词 i 的 sp 信号来自于词 i,但经过 pos 网络后,这个信息可能变得衰弱,可以再 pos 网络后 sp 网络前,将词 i 的信息通过残差连接过来。
(2)为了避免深层 RNN 的梯度消失,也为了更好的训练数据,在将 pos 和 sp 两个网络联合到一起之前,可以先采用预训练。例如,首先,pos 网络在一个更大的通用的 pos 语料上进行精确地 pos 训练。然后,pos 网络接入 sp 网络,在相对少量的 sp 语料上训练,pos 网络可以 fine-tuning。如果这份数据同时提供了对 pos 的监督信息,可以训练时 pos 和 sp 都进行输出,形成两个 loss,加和后再 bp。
2 Multi-task learning
类似于 cascaded learning,当存在多个相关的 task 时(不一定是相互喂信息的级联关系),可以利用一些 task 的信息去提升另外一些 task 的表现,称之为 multi-task learning。
核心想法就是不同 task 设计不同网络结构,但存在部分网络或者参数在多 task 之间共享。这个共享的 core 模块将捕获多个 task 的信息,从而帮助提升其他 task 的表现。
实际上,可以看出也可以将 cascaded
learning 归入到 multi-task learning 框架内。
例如,syntactic chunking 任务和 pos tagging 任务是可以互相促进的,两者的预测都依赖于句子的句法表征。通常两者都可以通过 deep biRNN+MLP 实现预测,也可以将两个任务的 word embedding 和 deep biRNN 实现共享,各自使用不同的特定的 MLP 即可,如下图所示
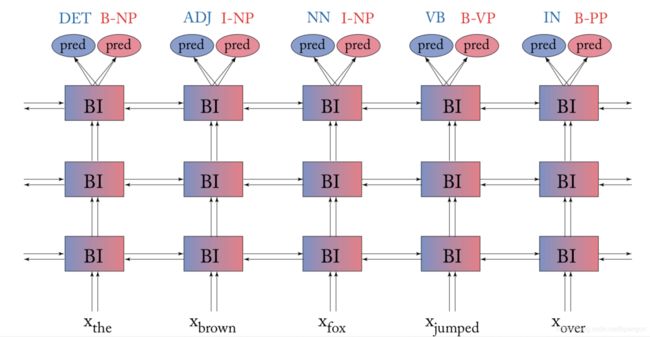
训练方式
对于多个 task 的对应语料,通常将其混在一起 shuffle 后依次 feed 进网络,根据该样本对应 task 计算 loss 更新参数。
有时,可能多个 task 中,存在所谓 main task 即更关注表现的那个 task,其他属于 support task 用来增强其表现的。此时,可以通过 loss 的权重进行反应,也可以将网络现在 support tasks 上进行预训练,最后在 main task 上进行继续训练。
共享部分的选择
回过头再看下 pos + chunking 任务,虽然两者共享信息,但 pos 任务需要的信息相对 chunking 任务来说更 low-level,而 chunking 任务需要的信息更 refined 些。此时,不必完全共享整个 deep biRNN,可以仅共享最底层的 biRNN,上层的 biRNN 们仅服务于 chunking 任务,如下图所示:

其实可以看出来这就很像前面提的 cascaded learning,实际上,也很难在 cascaded learning 和 multi-task learning 之间划下严格的界限。
词向量预训练
上面提到的 pos 任务、chunking 任务,以及很多其他任务,都和 LM 任务存在相互提升的关系。从这个角度看,预训练词向量作为特定任务的 embedding 层的初始化,也算是 multi-task learning 了(将 LM 作为 support task)。
conditioned generation
MTL 可以无缝融合到 conditioned generation framework 中。例如,S2S 结构中,共享的 encoder 连接到针对不同任务的decoder 中。如此将强制 encoder 捕获所有任务的相关的信息,这个信息也会被所有任务的 decoder 分享,扩展了所有样本的使用效率。如多语言 MT 中。
正则视角
多任务学习也可以看做一种正则化,通过强制共享的表征更通用,来自于 support task 的监督可以避免网络对 main task 的过拟合。
当然,如果把多任务的学习更面向这个目的,就不太应该在 MTL 中,先训练 support task 再训练 main task,而更应该所有任务一起并行开展。
泼点冷水
虽然 MTL 的理论很吸引人,但实际上很多时候 MTL 表现并不好。例如,当多个任务并不是紧密相关时,将很难获得 MTL 的增益。令人沮丧的是,事实上很多 NLP 的 task 确实不太相关。MTL 的相关任务选取与其说是科学不如说是一种艺术。
即使所有的任务都是相关的,但所设计的网络没有支撑所有任务的容量,这些任务的表现反而会下降。从正则化的视角来看,相当于正则作用强到了避免网络对所有任务的充分拟合。当然这可以通过增加网络规模解决。需要注意的是,如果发现针对 N 个任务需要将网络扩展为 K 倍才能支撑所有任务的话,那就说明这个网络并不存在多个任务之间的共享部分,那就完全可以摒弃使用 MTL 的想法了。
即使多个任务强相关,MTL 也可能不会带来多少增益。这主要出现在多个任务的监督语料是同一个时,例如一份语料同时提供了 pos 标注和 chunking 标注,此时 chunking 的学习并不需要 pos 中间表征的帮助。
真正能带来提升的是,多个相关的任务分别具有不相交的监督预料,或者子集关系的监督语料(support task 语料是 main task 语料的超集)时。
3 Semi-supervised learning
当我们对 main task 有少量监督数据,其他 task 上有些监督或无监督数据,如何利用后者来提升前者的表现,即 semi-supervised learning。看起来,和 cascaded learning 和 MTL 都有点关系。
非常常见,如在无监督语料上进行 word embedding 或 sentence embedding 的预训练,然后用来在 main task 进行部分网络的初始化或者 feed 进去。
讲到这也可以看出来,实际上没必要争论或者非要划清 cascaded learning、MTL、SPL 的界限,就把它们看做一个相互重叠的集合就好啦。