HBase的WAL机制
简述
WAL(Write-Ahead-Log)预写日志是Hbase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。在每次Put、Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文件的过程。 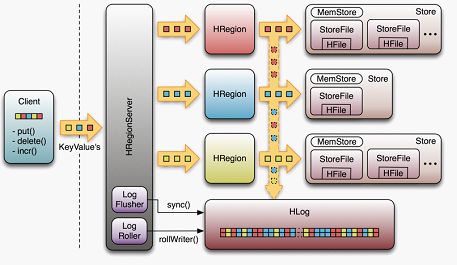
客户端往RegionServer端提交数据的时候,会先写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败,换句话说这其实是一个数据落地的过程。
在一个RegionServer上的所有的Region都共享一个HLog,一次数据的提交是先写WAL,写入成功后,再写memstore。当memstore值到达一定是,就会形成一个个StoreFile(理解为HFile格式的封装,本质上还是以HFile的形式存储的)。
相关类
HLog类
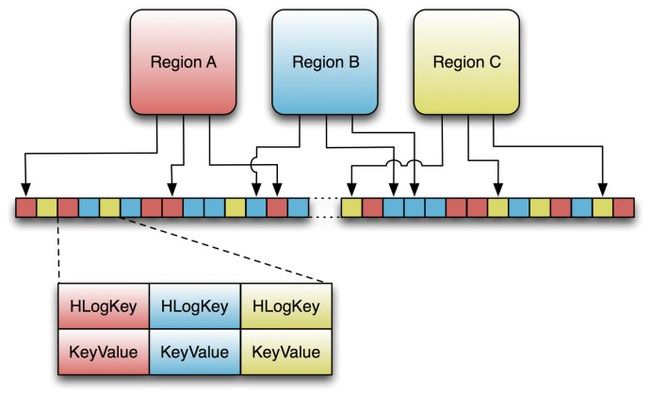
RegionServer内WAL文件与Region的关系图
WAL的实现类是HLog,当一个Region被初始化的时候,一个HLog的实例会作为构造函数的参数传进去。
当Region在处理Put、Delete等更新操作时,可以直接使用该共享的HLog的append方法来落地数据。
Put、Delete在客户端上可以通过setWriteToWAL(false)方法来关闭该操作的日志,这么做虽然可以提升入库速度,但最好别这么做,因为有数据丢失的风险存在。
package org.apache.hadoop.hbase.regionserver.wal;
public interface HLog {
interface Reader {
/**
* @param fs File system.
* @param path Path.
* @param c Configuration.
* @param s Input stream that may have been pre-opened by the caller; may be null.
*/
void init(FileSystem fs, Path path, Configuration c, FSDataInputStream s) throws IOException;
void close() throws IOException;
Entry next() throws IOException;
Entry next(Entry reuse) throws IOException;
void seek(long pos) throws IOException;
long getPosition() throws IOException;
void reset() throws IOException;
/**
* @return the WALTrailer of the current HLog. It may be null in case of legacy or corrupt WAL
* files.
*/
// TODO: What we need a trailer on WAL for?
WALTrailer getWALTrailer();
}
interface Writer {
void init(FileSystem fs, Path path, Configuration c, boolean overwritable) throws IOException;
void close() throws IOException;
void sync() throws IOException;
void append(Entry entry) throws IOException;
long getLength() throws IOException;
/**
* Sets HLog's WALTrailer. This trailer is appended at the end of WAL on closing.
* @param walTrailer trailer to append to WAL.
*/
void setWALTrailer(WALTrailer walTrailer);
}
/**
* Utility class that lets us keep track of the edit with it's key.
* Only used when splitting logs.
*/
// TODO: Remove this Writable.
class Entry implements Writable {
}
}HLogKey类
1、当前的WAL使用的是Hadoop的SequenceFile格式,其key是HLogKey实例。HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括sequence number和timestamp。
timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中Sequence number。
2、HLog Sequence File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
package org.apache.hadoop.hbase.regionserver.wal;
/**
* A Key for an entry in the change log.
*
* The log intermingles edits to many tables and rows, so each log entry
* identifies the appropriate table and row. Within a table and row, they're
* also sorted.
*
* Some Transactional edits (START, COMMIT, ABORT) will not have an
* associated row.
*/
// TODO: Key and WALEdit are never used separately, or in one-to-many relation, for practical
// purposes. They need to be merged into HLogEntry.
public class HLogKey implements WritableComparable {
}
WALEdit类
客户端发送的每个修改都会封装成WALEdit类操作,一个WALEdit类包含了多个更新操作,可以说一个WALEdit就是一个原子操作
包含了若干个操作的集合。
package org.apache.hadoop.hbase.regionserver.wal;
/**
* WALEdit: Used in HBase's transaction log (WAL) to represent
* the collection of edits (KeyValue objects) corresponding to a
* single transaction. The class implements "Writable" interface
* for serializing/deserializing a set of KeyValue items.
*
* Previously, if a transaction contains 3 edits to c1, c2, c3 for a row R,
* the HLog would have three log entries as follows:
*
* :
* :
* :
*
* This presents problems because row level atomicity of transactions
* was not guaranteed. If we crash after few of the above appends make
* it, then recovery will restore a partial transaction.
*
* In the new world, all the edits for a given transaction are written
* out as a single record, for example:
*
* :
*
* where, the WALEdit is serialized as:
* <-1, # of edits, , , ... >
* For example:
* <-1, 3, , , >
*
* The -1 marker is just a special way of being backward compatible with
* an old HLog which would have contained a single .
*
* The deserializer for WALEdit backward compatibly detects if the record
* is an old style KeyValue or the new style WALEdit.
*/
public class WALEdit implements Writable, HeapSize {
private final ArrayList kvs = new ArrayList(1);
} LogSyncer类
Table在创建的时候,有一个参数可以设置,是否每次写Log日志都需要往集群里的其他机器同步一次,默认是每次都同步,同步的开销是比较大的,但不及时同步又可能因为机器宕而丢日志。
同步的操作现在是通过Pipeline的方式来实现的,Pipeline是指datanode接收数据后,再传给另外一台datanode,是一种串行的方式;
n-Way Writes是指多datanode同时接收数据,最慢的一台结束就是整个结束。
差别在于一个延迟大,一个并发高,hdfs现在正在开发中,以便可以选择是按Pipeline还是n-Way Writes来实现写操作。
Table如果设置每次不同步,则写操作会被RegionServe缓存,并启动一个LogSyncer线程来定时同步日志,定时时间默认是1秒,也可由hbase.regionserver.optionallogflushinterval设置。
LogRoller类
日志写入的大小是有限制的。LogRoller类会作为一个后台线程运行,在特定的时间间隔内滚动日志。通过hbase.regionserver.logroll.period属性控制,默认1小时。
HBase容错处理
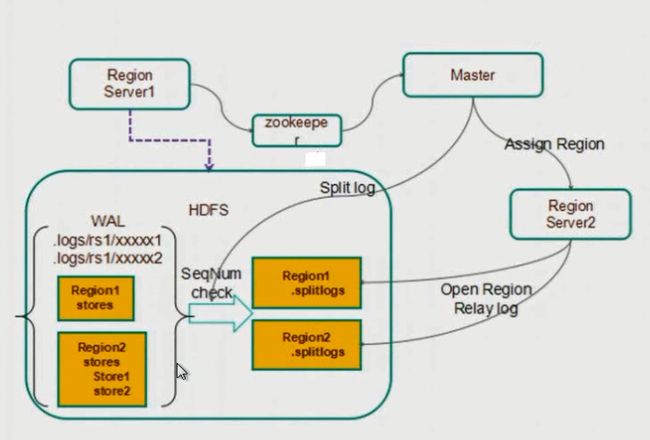
数据量比较大的时候,启动会比较耗时,大部分都是在做split log操作。
WAL记载了每一个RegionServer所对应的HLog。
RegionServer1或者RegionServer1上的某一个region挂掉了,都会迁移到其他机器上去处理。重新操作,进行恢复。