离群点检验方法
离群点
离群点(outlier)是一个数据对象,它显著不同于其他数据对象,好像它是被不同的机制产生一样。离群点检验就是找出其行为很不同于预期对象的过程。
应用:信用卡欺诈
离群点类型
离群点类型:
- 全局离群点
给定数据集中,如果它显著偏离数据集中的其余对象,则成为全局离群点。
- 情景离群点
在给定数据集中,如果关于对象的特定情境,它显著偏离其他对象,则称为情景离群点。
- 集体离群点
在给定数据集中,如果这些对象作为整体显著偏离整个数据集,则数据集的这个子集为集体离群点。
dat1 <- data.frame(x=rnorm(500,0,0.5),y=rnorm(500,0,0.5))
dat2 <- data.frame(x=rnorm(80,3,0.5),y=rnorm(80,3,0.5))
s <- rbind(dat1,dat2)
plot(s,col=ifelse(s$x>1.8,"red","black"),main="集体离群点")
离群点检测方法
(一)统计方法
参数方法
- 基于正态分布的离群点检测
正态分布: 12π√σexp{−(x−μ)22σ2}
例:假设某城市过去10年中7月份气温按递增排序为24,28.9,28.9,29,29.1,29.1,29.2,29.2,29.3,29.4。气温服从正态分布,参数为 μ,σ .
用极大似然估计求 μ,σ
最后算得 μ=28.61 , σ=1.51
正态分布下,区域 μ±3σ 包含99.7%的数据。最大 偏离值24,偏离估计均值4.61,由于 4.611.51=3.04>3 ,因此它被视为离群值。
可视化方法(箱线图)
*最小非离群点值
*上四分位数(Q1)
*中位数
*下四分位数(Q3)
*最大离群点值
*四分位极差(IQR):Q3-Q1
比Q1小 1.5∗IQR 或比Q3大 1.5∗IQR 都作为离群点。
b <- c(24,28.9,28.9,29,29.1,29.1,29.2,29.2,29.3,29.4)
boxplot(b,col ="blue")
非参数方法
直方图
核密度图
使用核密度估计数据概率密度,使用核函数对数据建模。
核函数K()是一个非负可积函数,满足两个条件:
(1) ∫∞−∞K(u)du=1
(2) 对于所有的u值,K(−u)=K(u)
常用的核函数为均值为0,方差为1的高斯核函数:
K(x−xih)=12π√exp{−(x−xi)22h2}
其中,K()是核函数,h为带宽,充当平滑参数。
还使用上面的气温数据:
hist(b,col="blue",breaks=10,freq=F)
lines(density(b),col="red")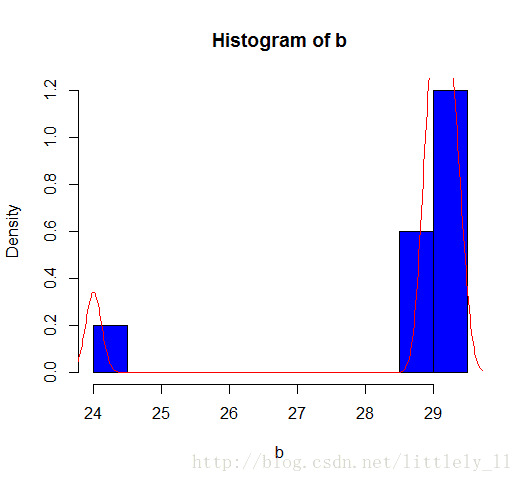
(二)基于距离的检测方法
基于距离的离群点检测方法考虑对象给定半径的邻域,如果它的邻域没有足够多的其他点,则认为它为离群点。
嵌套循环方法
对于给定的数据集D,用户指定一个距离阈值r来定义合理的邻域,对每个对象o,考察o的r-邻域内其他对象的个数,如果D中大多数对象都远离o,则o被视为离群点。
其中,r为距离阈值, π 为分数阈值,对象o为一个DB(r, π )离群点,dist(.,.)为距离度量.
算法:基于距离的离群点检验
输入:对象集 D={o1,o2,...,on} ,阈值r, π(0<π≤1)
输出: D中的DB(r, π )离群点
方法:
for i=1 to n do
count <- 0
for j=1 to n do
if i != j and dist(oi,oj)<= r then
count <- count + 1
if count >= pi*n then
exit
end if
end if
end for
print oi
end for;代码实现:
## the definition of testing outlier function
outlier.test <- function(data = data, r = 5, p = 0.1){
out <- data.frame(x=numeric(0),y=numeric(0))
for(i in 1:nrow(data)){
count <- 0
for(j in 1:nrow(data)){
distance <- sqrt(sum((data[i,] - data[j,])^2))
if((i != j) & (distance <= r)){
count <- count + 1
if(count >= p * nrow(data)){
break
}
}
}
if(count < p*nrow(data)){
out <- rbind(out,dat[i,])
}
}
return(out)
}set.seed(123)
dat2 <- data.frame(x=rnorm(3,4,2),y=rnorm(3,4,2))
dat <- rbind(dat1,dat2)
plot(dat)
m <- outlier.test(dat,r=4)
m x y
501 2.879049 4.141017
502 3.539645 4.258575
503 7.117417 7.430130
library(ggplot2)
ggplot() + geom_point(data = dat,aes(x,y)) + geom_point(data=m,aes(x,y),color="red")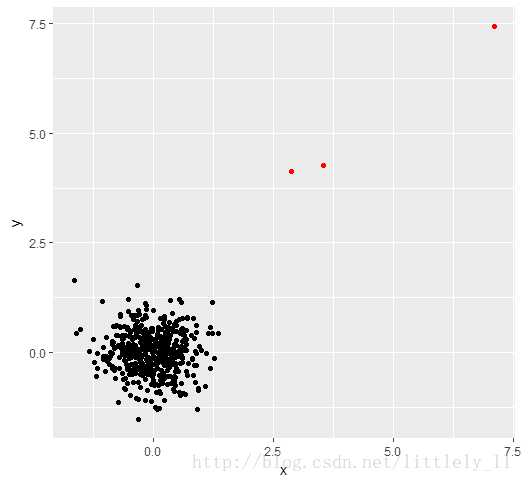
基于密度的离群点检验
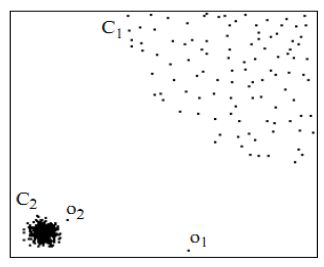
从下图看,有两个簇,C1和C2,C1是稀疏的,C2是稠密的, o1 可被检测为基于距离的离群点,它远离数据的大多数。现在考虑 o2 这一点, o2 到C2的距离要小于到C1的距离,如果把 o2 分类为基于 DB(r,π) 的离群点,则C1也必须分类为 DB(r,π) 的离群点,所以 o2 不是基于距离的离群点。
而当局部考虑簇C2时, o2 可视为离群点,因为它显著偏离C2中的对象。所以,对于这种问题,可以考虑基于密度的离群点检测方法。
局部离群点因子(Local Outlier Factor,LOF)算法:
局部离群点定义:把对象周围的密度与对象邻域周围的密度进行比较,非离群点周围的密度与其邻域周围的密度相似,而离群点周围的密度显著不同于其邻域周围的密度。
(1) 对象o和 p∈D 之间的距离记为dist(o,p).
(2) 对象o的k-距离 distk(o) ,即为对象o到第k远p的距离,使得:
- 至少有k个对象 o′∈D−{o} ,使得 dist(o,o′)≤dist(o,p)
- 至少有k-1个对象 o′′∈D−{o} ,使得 dist(o,o′′)<dist(o,p)
(3) 对象o的k-距离邻域包含其到o的距离不大于 distk(o) 的所有对象,记为
Nk(o) 中的对象可能超过k个,因为可能会有多个对象到o的距离相等。
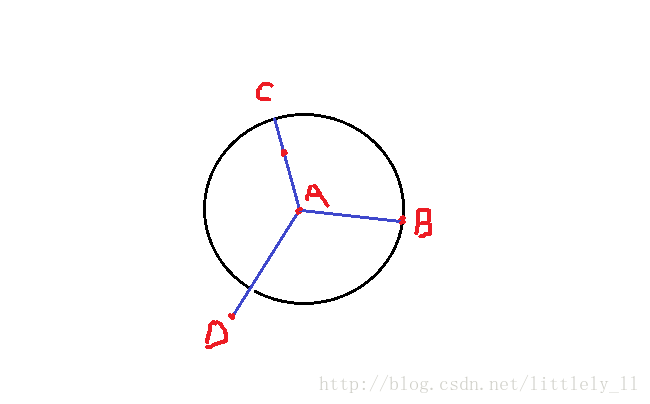
从上图看出,B和C点为A的邻域内额点,而D不是。
(4) 可达距离: 对于两个对象o和 o′ ,如果 dist(o,o′)>distk(o′) ,则从 o′ 到o的可达距离为 dist(o,o′) ,否则为 distk(o) .即
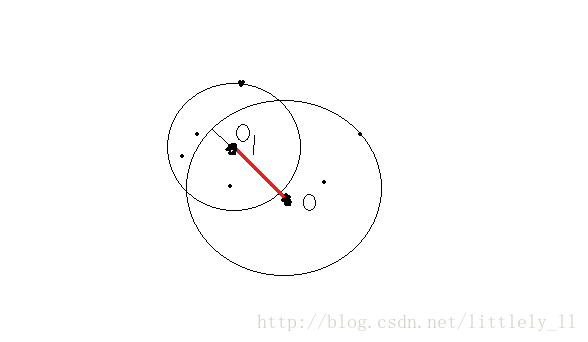
注意,从 o′ 到o的可达距离是以 o′ 为核心点进行距离测算,从上图可以看出, o′ 到o的可达距离为 dist(o′,o) ,即为红色线段的距离。而o到 o′ 的可达距离为 distk(o) (也就是上图中红色线段加上黑色线段的距离),这一点要搞清楚。其实这很像密度聚类中的密度可达。
(5) 局部可达密度
表示点o的第k邻域内点到点o的平均可达距离的倒数。
由公式看出,此时是以 o′ 为核心点, reachdistk(o←o′) 是 o′ 到o的距离。且 o′ 是在o的k距离邻域内的点。
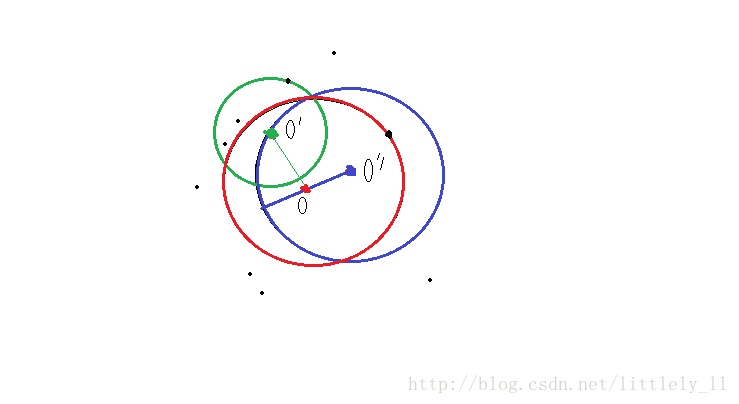
从上面这张图解释局部可达密度。 o′和o′′ 都为o的k距离邻域中的点,其中, o′ 到o的距离为绿色那条线段, o′′ 到o的可达距离为蓝色那一条线段,然后把o的k邻域内的所有点到o的可达距离加总就得到了 Σo′∈Nk(o)reachdistk(o←o′) 。而 ∥Nk(o)∥ 表示o的k距离邻域内的点数。
(6) 局部离群点因子(LOF)
表示o邻域的局部可达密度与o的局部可达密度之比的平均值。当比值接近1时,表示o和o邻域的密度相仿,当比值小于1时,表示o的局部可达密度高于其邻域的可达密度,这两种情况都不是离群点,当比值大于1时,说明o邻域的可达密度大于o的可达密度,说明o是离群点。
算法实现:
python算法:
https://github.com/damjankuznar/pylof
参考:
【1】wiki-Local outlier factor
【2】异常点/离群点检测算法——LOF
【3】数据挖掘:概念与技术
【4】LOF: Identifying Density-Based Local Outliers