MapReduce代码常见报错
MapReduce代码常见报错【updating…】
1.报错一Exception in thread "main" java.lang.UnsupportedClassVersionError
- 执行
hadoop jar …命令时,出现Exception in thread "main" java.lang.UnsupportedClassVersionError错误,原因是:jdk版本类型不同【物理机上的jdk与虚拟机上的版本不同】。只要新建一个项目,调整一下jdk版本重现生成一个jar文件再执行一遍就好了。
2. 报错二 Type mismatch
- 执行
MapReduce代码时,报错如下:
java.lang.Exception: java.io.IOException: Type mismatch in key from map: expected data_algorithm.DateTemperaturePair, received org.apache.hadoop.io.LongWritable
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
java.io.IOException: Type mismatch in key from map: expected data_algorithm.DateTemperaturePair, received org.apache.hadoop.io.LongWritable
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1069) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:712) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
这里面的错误就是:Mapper 输出的键值对 和 Reducer的键值对类型不同,导致出现这个问题。
3. 报错三 输出key为空
- 在Reducer中写出键值对时,看不到数据,但是任务却能够正常运行。
比如,我在运行一个MapReduce任务时,出现的问题是:
在输出的文件中: key是空,但是value不为空。具体展示如下:
[root@server4 hadoop]# hdfs dfs -cat /output/temperature/part-r-00000
35,-40,30,-20,-20,60,20,10,
这是因为如果需要写一个非Hadoop定义的类型对象时,需要实现Writable接口,并实现其中的write() 和 readFields() 方法。见我博客对Writable接口的详解。
4.报错四
- 报错信息
java.lang.Exception: java.io.IOException: Illegal partition for data_algorithm.chapter_5.PairOfWord@14c86 (17025)
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
java.io.IOException: Illegal partition for data_algorithm.chapter_5.PairOfWord@14c86 (17025)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1079) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:712) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.write(WrappedMapper.java:112) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at data_algorithm.chapter_5.OrderInversionMapper.emit(OrderInversionMapper.java:44) ~[classes/:na]
at data_algorithm.chapter_5.OrderInversionMapper.map(OrderInversionMapper.java:30) ~[classes/:na]
at data_algorithm.chapter_5.OrderInversionMapper.map(OrderInversionMapper.java:10) ~[classes/:na]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[na:1.8.0_77]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[na:1.8.0_77]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) ~[na:1.8.0_77]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) ~[na:1.8.0_77]
at java.lang.Thread.run(Thread.java:745) ~[na:1.8.0_77]
上面的错误说明是分区算法有问题。
- 报错原因
如下图所示,本应该使用%,但是我使用的是/,导致报错。
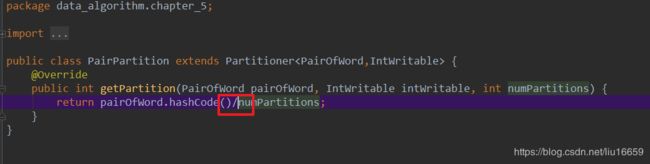
但是有时候却也不是因为Partition的算法有问题,而是因为,某些其它的原因:
java.lang.Exception: java.io.IOException: Illegal partition for <language,*> (-2)
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) ~[hadoop-mapreduce-client-common-2.6.5.jar:na]
java.io.IOException: Illegal partition for <language,*> (-2)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1079) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:712) ~[hadoop-mapreduce-client-core-2.6.4.jar:na]
···
可以看到这里仍然报这个错,那还有什么原因呢?再看我的getPartition()方法,这个方法里如下所示:
@Override
public int getPartition(PairOfWord pairOfWord, IntWritable intWritable, int numPartitions) {
return pairOfWord.hashCode() % numPartitions;
}
而pairOfWord这个对象的hashCode()如下所示:
@Override
public int hashCode() {
int result = leftStr != null ? leftStr.hashCode() : 0;
System.out.println("result= "+result);
return result;
}
接着我就想看看language这个字符串的hashcode,得到了如下的结果:
public static void main(String[] args) {
System.out.println("language:"+"language".hashCode());
System.out.println("great:"+"great".hashCode());
}
得到的结果如下:
language:-1613589672
great:98619021
可以看到字符串language的hashcode是-1613589672 ! 正是因为这个原因导致最后在getPartition()中得到了一个负数的分区。然而这是不对的!所以修改getPartition方法代码如下:
@Override
public int getPartition(PairOfWord pairOfWord, IntWritable intWritable, int numPartitions) {
return Math.abs(pairOfWord.hashCode() % numPartitions);
}
即可不再报错
5. 输出文件乱码
- 输出内容
[root@server4 hadoop]# hdfs dfs -cat /output/orderInversion/part-r-00004
data_algorithm.chapter_5.PairOfWord@14ce3 0.0
data_algorithm.chapter_5.PairOfWord@14ce3 0.25
data_algorithm.chapter_5.PairOfWord@14ce3 0.0
data_algorithm.chapter_5.PairOfWord@14ce3 0.0
- 原因:
针对上面的输出可以看到其输出了一个对象的哈希信息。【针对包名+类名+地址信息 很快就应该猜测出来】
再看reducer的输出类型是:PairOfWord,这就会导致直接写出PairOfWord对象,我们都知道,如果要输出一个对象,那么程序就会自动调用toString()方法。因为默认的toString()方法是一个哈希字符串,导致不适合阅读。
默认的toString()方法如下:

接着只需要使用重写toString()方法,修改如下即可:
@Override
public String toString() {
return "<" + leftStr + ","+ rightStr + '>';
}
最后得到的执行结果如下:
[root@server4 hadoop]# hdfs dfs -cat /output/orderInversion/part-r-00002
<W2,*> 0.0
<W2,W1> 0.0
<W2,W4> 0.0
<W2,W5> 0.0