Java 爬虫项目实战之获取知乎图片【updating】
Java 爬虫项目实战之获取知乎图片【updating】
1. 背景
使用爬取知乎图片作为我的实战项目,是因为我考虑到这个项目会使用到很多Java编程知识,比如I/O,多线程,Collection框架,设计模式,HttpClient,HTTP等。大概在经历了约两个周末的时间,从0到1 搞出了一点儿东西出来。
2. 项目需求
获取知乎某个问题下所有答主的图片。
因为时间原因,代码写的并不完整,包括很多问题都没有解决,但是已经提供了基本功能,后期会慢慢更新,且代码会同步至我的github上。
3.项目架构
- java
- intellij
- Multiple Thread【暂未使用】
- 队列【暂未使用】
- 高匿代理【暂未使用】
- log4j【暂未使用】
- git
4. 主要坑
- problem 1 :知乎网站是动态加载的,比如进入到一个知乎页面,需要获取某个问题的全部图片,但是你拉到页面之后可能是如下的样子:

这里有一个查看全部685个回答,因为代码里不能使用点击的方式,那该怎么办呢?其实是有办法的,那就是通过知乎中使用的 offset + limit 进行获取。
- problem 2
第二个问题就是,我们通过链接https://www.zhihu.com/question/48804993获取内容时,只能获取到前几条内容。这个问题其实本质上同第一个问题。但是实际在程序中,我们并不使用这个链接作为爬取目标。而是另外的一个链接。这个链接可以通过F12键获取,如下:

实际的样子是:
include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics
limit=5
offset=5
sort_by=default
再仔细一点儿就是如下这张图中的显示:

获取到的链接是:https://www.zhihu.com/api/v4/questions/48804993/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=3&offset=3&sort_by=default 这个就是我们实际需要使用的Get 请求url。而其中的limit=3&offset=3 只不过是一个可以设置的变量而已。
5. 主要代码
经过上面的分析,则很好办啦。代码主要如下:
HttpClientUtils
这个类的主要作用是实现GET请求; 然后将获取到的图片地址,写入磁盘。
package crawler.httpClient;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import utils.CustomedMethod;
import utils.json.JsonUtils;
import java.io.*;
import java.text.SimpleDateFormat;
import java.util.*;
public class HttpClientUtils {
private String dirPath = "E:\\intellij_Project\\zhihu_picture\\";
//the url we get picture's url
private static String topicUrl = "https://www.zhihu.com/api/v4/questions/23776164/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&offset=0&limit=4&sort_by=created";
private static Set<String> pictureUrls = new HashSet<String>();
//01.CloseableHttpClient is a abstract class => in order to use in all method
private CloseableHttpClient httpClient = HttpClients.createDefault();
private static JsonUtils jsonUtils = new JsonUtils();
public static void main(String[] args) {
HttpClientUtils httpClientUtils = new HttpClientUtils();
Set<String> tempPictureUrls = null;
String tempUrl;
//01.通过url获取entity
boolean flag = false;
while(!flag) {
CustomedMethod.printDelimiter(topicUrl);
String jsonString = httpClientUtils.getEntityContent(topicUrl);
tempPictureUrls = httpClientUtils.getImageUrlByJson(jsonString);
flag = jsonUtils.isEnd(jsonString);
Iterator<String> iterator = tempPictureUrls.iterator();
while (iterator.hasNext()) {
pictureUrls.add(iterator.next()); // add the total set -> pictureUrl
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
topicUrl = jsonUtils.getNext(jsonString);
//print the next url
CustomedMethod.printDelimiter(topicUrl);
//print the pictureUrl's size
System.out.println(pictureUrls.size());
}
//pictureUrl is a list,so you must use get() rather than index to fetch a value
for(String imageUrl : pictureUrls) {
System.out.println(imageUrl);
Iterator<String> iterator = tempPictureUrls.iterator();
while (iterator.hasNext()) {
httpClientUtils.getPicture(iterator.next());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public Set<String> getImageUrlByJson(String jsonString) {
Set<String> pictureUrl ;
jsonUtils.getImageUrl(jsonString);
//01. get pictureUrl
pictureUrl = jsonUtils.getPictureUrls();
//02. output the
jsonUtils.outputUrl(pictureUrl);
return pictureUrl;
}
//get picture from specific url
public void getPicture(String url) {
HttpClientUtils httpClientUtils = new HttpClientUtils();
HttpEntity entity = httpClientUtils.getEntity(url);
httpClientUtils.writeImageInDisk(entity);
}
//get html entity from specific url
public HttpEntity getEntity(String url) {
//use get
HttpGet httpGet = new HttpGet(url);
// HttpHost proxy = new HttpHost("115.153.146.73", 8060);
RequestConfig config = RequestConfig
.custom()
.setConnectTimeout(10000)//连接超时
.setSocketTimeout(10000)//读取超时
.build();
httpGet.setConfig(config);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0");
//get the request's response
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
HttpEntity entity = response.getEntity();
return entity;
}
public String getEntityContent(String url) {
String jsonContent = null;
//use get
HttpGet httpGet = new HttpGet(url);
RequestConfig config = RequestConfig
.custom()
.setConnectTimeout(10000)//连接超时
.setSocketTimeout(10000)//读取超时
.build();
httpGet.setConfig(config);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0");
//get the request's response
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
HttpEntity entity = response.getEntity();
try {
jsonContent = EntityUtils.toString(entity, "utf-8");
} catch (IOException e) {
e.printStackTrace();
}
return jsonContent;
}
//this part,use a customed method,rather than a specific path to store new file
public String getImageName() {
String imageName;
Date date = new Date();
//DateFormat dateFormat = DateFormat.getDateInstance();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd_HHmmss");
//System.out.println(simpleDateFormat.format(date));
imageName = dirPath + simpleDateFormat.format(date) + ".jpg";
return imageName;
}
public void writeImageInDisk(HttpEntity entity) {
InputStream inputStream = null;
try {
inputStream = entity.getContent();
} catch (IOException e) {
e.printStackTrace();
}
String fileAddress = getImageName();
File newFile = new File(fileAddress);
//使用字节存储图片,但是这里的大小只有1024B = 1kB,是否会导致数组溢出?
byte[] image = new byte[1024];
int length;
FileOutputStream fileOutputStream = null;
try {
if (inputStream != null) {
fileOutputStream = new FileOutputStream(newFile);
while ((length = inputStream.read(image)) != -1) {
fileOutputStream.write(image, 0, length);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
JsonUtils类
这个类的主要作用是对GET请求得到的json对象进行内容提取。 主要是获取图像的url和是否到达问题末尾标志?
package utils.json;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import utils.CustomedMethod;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class JsonUtils {
private static Set<String> pictureUrls = new HashSet<String>();// set of pictures
public Set<String> getPictureUrls() {
return pictureUrls;
}
public void outputUrl(Set<String> pictureUrls){
Iterator<String> iterator = pictureUrls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
public String getNext(String jsonString) {
JSONObject jsonObject = JSONObject.parseObject(jsonString);//将该字符串解析成jsonObject
String nextUrl = jsonObject.getJSONObject("paging").getString("next");//提取该对象中的data域,
return nextUrl;
}
public void getImageUrl(String jsonString) {
JSONObject jsonObject = JSONObject.parseObject(jsonString);//将该字符串解析成jsonObject
JSONArray array = jsonObject.getJSONArray("data");
CustomedMethod.printDelimiter(Integer.toString(array.size()));
for(int i = 0;i < array.size();i++) {
System.out.println(array.get(i));
//get all content
String content = array.getJSONObject(i).getString("content");
Document document = Jsoup.parse(content);
//04.根据已知的document,获取目标Elements 元素
Elements imgElements = document.select("img[src$=.jpg]");//查找扩展名以.jpg 结尾的dom节点
//05.获取Element节点中的指定属性值。在我这里我就需要获取src的值
for (Element e : imgElements) {
String tempUrl = e.attr("src");
pictureUrls.add(tempUrl);
// System.out.println("src:"+pictureUrl);
}
}
}
//judge the answer is in end?
public boolean isEnd(String jsonString){
JSONObject jsonObject1 = JSONObject.parseObject(jsonString);//将该字符串解析成jsonObject
JSONObject jsonObject2 = jsonObject1.getJSONObject("paging");
//get flag
String flag = jsonObject2.getString("is_end");
if (flag.equals("true")) {
return true;
}
return false;
}
}
6. 爬取结果
- 文件夹

- 全部的图片
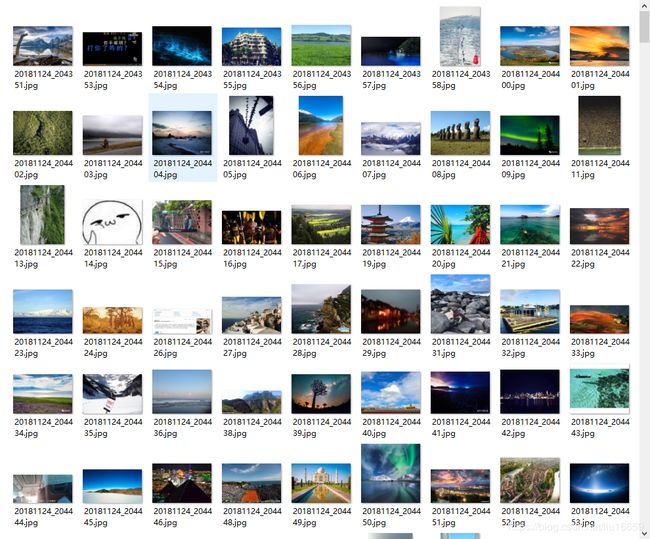
其中也不乏一些很好看的照片

当然,更好看的照片还有很多,有兴趣的大家可以自己修改代码继续爬取。