python3爬虫(1)爬取链家二手房
思来自己从写第一个程序到现在已有八年之久,熟练的编程语言也仅有C++,期间也学习过其他编程语言,蓦然回首发现已全然不记得,如狗熊掰棒子,最后怀里只剩下最后一个,自认为还算一个优秀程序员只会一种编程语言有点拿不出手,很是惭愧。静下心来想学python,其实自己的第一个程序也就是他了,这次学一定要搜索积淀,不能学完了也就忘完了,最好的方式是以实战为中心,亦即做一点实战项目,python名气最大的应该是爬虫,那就以爬虫为学习切入点记录一下自己学习路程,本篇为第一篇以后不做类似无关话的乱BB。爬虫系列文章主要是转载别人写的文章,里面会附带原文链接,和原文详细内容(怕原文章文章丢失),会有自己的理解和更新之后的代码(很多情况源代码已失效,需要稍作更改),主要是记录下自己学习足迹。爬虫系列文章主要记录爬虫实战,对python语法和技术不会做详细记录。
原文链接:https://www.cnblogs.com/Tsukasa/p/6799968.html
前言
作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始。
一、分析观察爬取网站结构
这里以广州链家二手房为例:http://gz.lianjia.com/ershoufang/
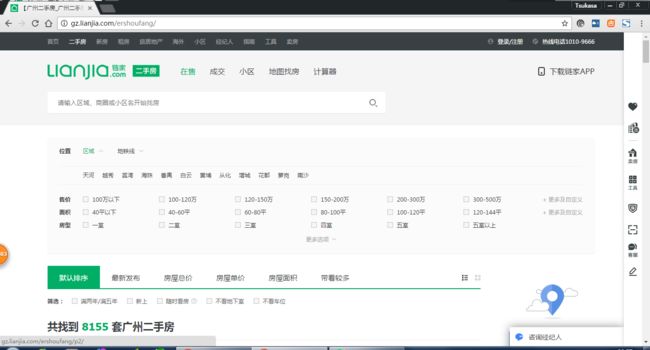
这是第一页,我们看看第二页的url会有什么变化 发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。
发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。
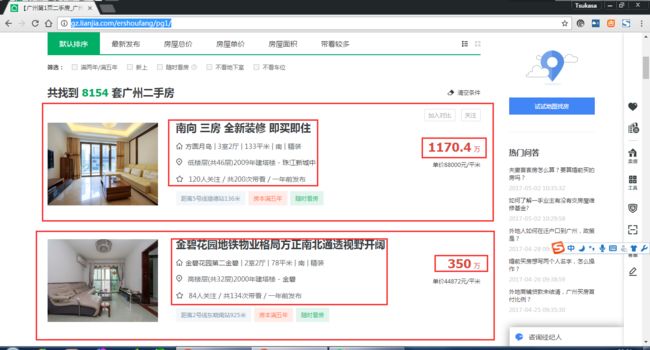
这些就是我们想得到的二手房资讯,但是这个是有链接可以点进去的,我们看看:
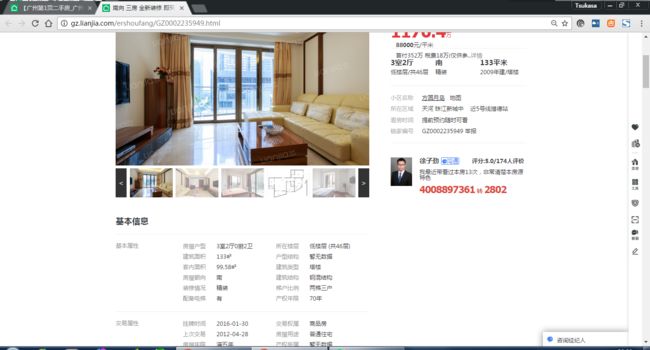
里面的二手房资讯更加全面,那我是想得到这个网页里面的资讯了。
二、编写爬虫
1.得到url
我们先可以得到全部详细的链接,这里有100页,那么我们可以http://gz.lianjia.com/ershoufang/pg1/.../pg2.../pg3.../pg100 先生成全部url,再从这些url得到每一页里面详细的url,再从详细的url分析html得到我想要的资讯。

2.分析 htmlhttp://gz.lianjia.com/ershoufang/pg1/
先打开chrom自带的开发者工具分析里面的network ,把preserve log
,把preserve log![]() 勾上,清空
勾上,清空 ,然后我们刷新一下网页。
,然后我们刷新一下网页。
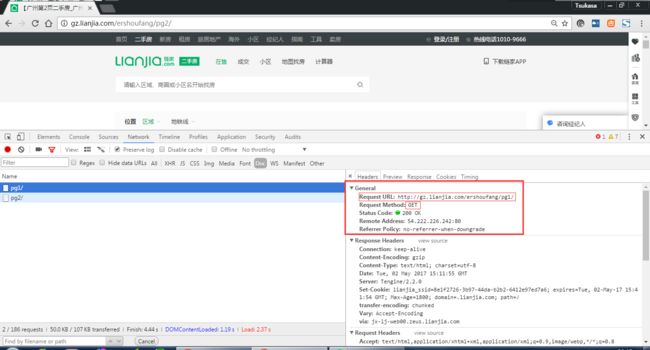
发现get:http://gz.lianjia.com/ershoufang/pg1/请求到的html
那么我们就可以开始生成全部url先了:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
运行结果:
这样我们就生成了100页的url
然后我们就要分析这些url里面的详细每一页的url:
先分析网页结构,

发现我们要的url是再class为title里面的a标签,我们可以使用request来获取html,用正则表达法来分析获取详情页url:
import requests| 1 |
|
def一个方法,把得到的generate_allurl传进来再打印一下看看
| 1 2 3 4 5 6 |
|
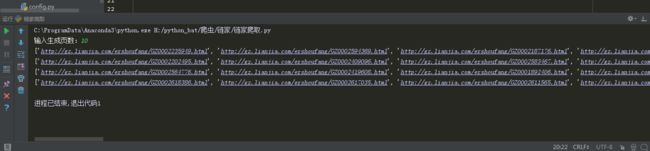
正常获取详细页的链接
下一步我们就要分析这些详细页连接以获取里面的资讯, 使用自带开发者工具点击这个箭头可以选择网页元素:
使用自带开发者工具点击这个箭头可以选择网页元素:
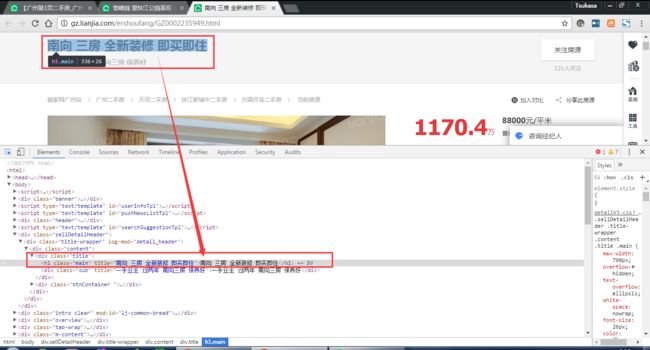
发现资讯在一个class为main里面,可以用BeautifulSoup模块里面的方法得到:
| 1 |
|
定义一个方法来把详情url链接传进来分析:
| 1 2 3 4 5 6 7 8 9 |
|
这里把requests.get对象传给res,然后把这个变量传给BeautifulSoup,用lxml解析器解析,再把结果传给soup,然后就可以soup.select方法来筛选,因为上面标题在,main下:
soup.select('.main'),因为这里是一个class,所以前面要加.,如果筛选的是id,则加#。
得到如下结果:

是一个list,所以我们要加[ 0 ]取出,然后可以运用方法 .text得到文本。
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
soup = BeautifulSoup(res.text,'lxml')
title = soup.select('.main')[0].text
print(title)得到结果

然后还可以添加到字典,return返回字典:
| 1 2 3 4 5 6 7 8 9 |
|
得到结果:
还可以储存到xlsx文档里面:
| 1 2 3 |
|
ok基本完成,可能有没有说清楚的,留言我继续更新
![]()
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 # Author;Tsukasa
4
5 import json
6 from multiprocessing import Pool
7 import requests
8 from bs4 import BeautifulSoup
9 import re
10 import pandas as pd
11 import pymongo
12
13
14 def generate_allurl(user_in_nub, user_in_city): # 生成url
15 url = 'http://' + user_in_city + '.lianjia.com/ershoufang/pg{}/'
16 for url_next in range(1, int(user_in_nub)):
17 yield url.format(url_next)
18
19
20 def get_allurl(generate_allurl): # 分析url解析出每一页的详细url
21 get_url = requests.get(generate_allurl, 'lxml')
22 if get_url.status_code == 200:
23 re_set = re.compile('.*?' in i or len(i) > 0:
44 key, value = (i.split(''))
45 info[key[24:]] = value.rsplit('')[0]
46 for i in soup.select('.transaction li'):
47 i = str(i)
48 if '' in i and len(i) > 0 and '抵押信息' not in i:
49 key, value = (i.split(''))
50 info[key[24:]] = value.rsplit('')[0]
51 print(info)
52 return info
53
54
55 def update_to_MongoDB(one_page): # update储存到MongoDB
56 if db[Mongo_TABLE].update({'链家编号': one_page['链家编号']}, {'$set': one_page}, True): #去重复
57 print('储存MongoDB 成功!')
58 return True
59 return False
60
61
62 def pandas_to_xlsx(info): # 储存到xlsx
63 pd_look = pd.DataFrame(info)
64 pd_look.to_excel('链家二手房.xlsx', sheet_name='链家二手房')
65
66
67 def writer_to_text(list): # 储存到text
68 with open('链家二手房.text', 'a', encoding='utf-8')as f:
69 f.write(json.dumps(list, ensure_ascii=False) + '\n')
70 f.close()
71
72
73 def main(url):
74
75 writer_to_text(open_url(url)) #储存到text文件
76 # update_to_MongoDB(list) #储存到Mongodb
77
78
79 if __name__ == '__main__':
80 user_in_city = input('输入爬取城市:')
81 user_in_nub = input('输入爬取页数:')
82
83 Mongo_Url = 'localhost'
84 Mongo_DB = 'Lianjia'
85 Mongo_TABLE = 'Lianjia' + '\n' + str('zs')
86 client = pymongo.MongoClient(Mongo_Url)
87 db = client[Mongo_DB]
88 pool = Pool()
89 for i in generate_allurl('2', 'zs'):
90 pool.map(main, [url for url in get_allurl(i)]) ![]()
源码地址:https://gist.github.com/Tsukasa007/660fce644b7dd33afc57998fdc6c376a
为了更好
========以上为转载,拷贝过来主要担心原文章丢失,下面是自己的实际测试===========
简单修改如下:
import json
from multiprocessing import Pool
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import pymongo
session=requests.session()
def generate_allurl(user_in_nub, user_in_city): # 生成url
url = 'http://' + user_in_city + '.lianjia.com/ershoufang/pg{}/'
for url_next in range(1, int(user_in_nub)):
yield url.format(url_next)
def get_allurl(generate_allurl): # 分析url解析出每一页的详细url
#这里模拟一下请求头,头文件是从浏览器里面抓到的,否则服务会回复403错误,(其实就是服务器做的简单防爬虫检测)
headers={
'Host':'xa.lianjia.com',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie':'TY_SESSION_ID=bd212f0d-fa69-41b2-bd24-b147b1aa6f93; lianjia_uuid=4479a173-a725-499e-ae06-99e9e2d78c3a; UM_distinctid=167e9c20cd221b-0d1bfec5576324-10724c6f-1fa400-167e9c20cd42aa; select_city=442000; _jzqckmp=1; all-lj=c60bf575348a3bc08fb27ee73be8c666; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1546392681,1546572269,1546591543,1546591988; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1546591988; _smt_uid=5c23441b.121b752a; CNZZDATA1254525948=1906388473-1545883862-%7C1546590852; CNZZDATA1255633284=2126119324-1545884076-%7C1546587312; CNZZDATA1255604082=1549936819-1545883843-%7C1546591140; _jzqa=1.351604181808559040.1545815068.1546591544.1546591990.9; _jzqc=1; _jzqb=1.1.10.1546591990.1; _qzja=1.757497874.1545885920295.1546591543773.1546591989755.1546591839817.1546591989755.0.0.0.10.7; _qzjb=1.1546591543773.4.0.0.0; _qzjc=1; _qzjto=5.3.0; _ga=GA1.2.763502423.1545815070; _gid=GA1.2.1829352401.1546591547; lianjia_ssid=f3e5db05-9789-4d8e-aae2-80b919a3cfa8'
}
session.headers.clear()
session.headers.update(headers)
get_url = session.get(generate_allurl)
if get_url.status_code == 200:
#原来代码用没有正则搜索出结果,这里屏蔽下,用BS完成所有赛选
#re_set = re.compile('.*?' in i or len(i) > 0:
# key, value = (i.split(''))
# info[key[24:]] = value.rsplit('')[0]
# for i in soup.select('.transaction li'):
# i = str(i)
# if '' in i and len(i) > 0 and '抵押信息' not in i:
# key, value = (i.split(''))
# info[key[24:]] = value.rsplit('')[0]
print(info)
return info
def update_to_MongoDB(one_page): # update储存到MongoDB
Mongo_Url = 'localhost'
Mongo_DB = 'Lianjia'
Mongo_TABLE = 'Lianjia' + '\n' + str('zs')
client = pymongo.MongoClient(Mongo_Url)
db = client[Mongo_DB]
if db[Mongo_TABLE].update({'链家编号': one_page['链家编号']}, {'$set': one_page}, True): #去重复
# print('储存MongoDB 成功!')
return True
return False
# pandas写excel只找到了一次写入没找到追加方式,暂时不用吧
def pandas_to_xlsx(info): # 储存到xlsx
pd_look = pd.DataFrame(info,index = False)
pd_look.to_excel('链家二手房.xlsx', sheet_name='链家二手房')
def writer_to_text(list): # 储存到text
with open('链家二手房.text', 'a', encoding='utf-8')as f:
f.write(json.dumps(list, ensure_ascii=False) + '\n')
f.close()
def main(url):
info = open_url(url)
writer_to_text(info) #储存到text文件
# pandas_to_xlsx(info) #储存到xlsx文件
update_to_MongoDB(info) #储存到Mongodb
if __name__ == '__main__':
# user_in_city = input('输入爬取城市:')
# user_in_nub = input('输入爬取页数:')
pool = Pool()
for i in generate_allurl('2', 'xa'):
pool.map(main, [url for url in get_allurl(i)]) PyCharm运行截图:

存储到text和MongoDB截图:
