Hive中对数据库,表的操作
在应用Hive之前,首先搭建Hive环境,关于Hive的搭建 参考之前的搭建文档
http://blog.csdn.net/liulihui1988/article/details/74351532
Hive官方应用文档
https://cwiki.apache.org/confluence/display/Hive/LanguageManual
数据定义语言 DDL

1、Create Database
Hive中数据库的创建和关系型数据库类似,用create datebase创建
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
hive 中的操作
hive> create database hive

2、Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
3、Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...)
4、Use Database
USE database_name;
USE DEFAULT;
Create/Drop/Truncate Table
Hive中创建表,和关系型数据库中的创建表类似,Hive中表的字段应该和原始文件中的格式一致,原始文件存在HSFS上
1、create table
create table t_emp(
id int,
name string,
age int,
dept_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','备注:FIELDS TERMINATED BY ‘,’ 表示原始文件中的格式使用 ‘,’ 隔开的
测试 创建一个emp_data文件,导入t_emp表中

Hive数据的导入
Hive不做任何转换,数据加载到表中。加载操作目前纯复制/移动操作,实际上进入Hive位置对应表。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]备注:[LOCAL] 本地文件,’filepath’ 路径
测试数据导入表t_emp中
load data local inpath '/root/emp_data' into table t_emp;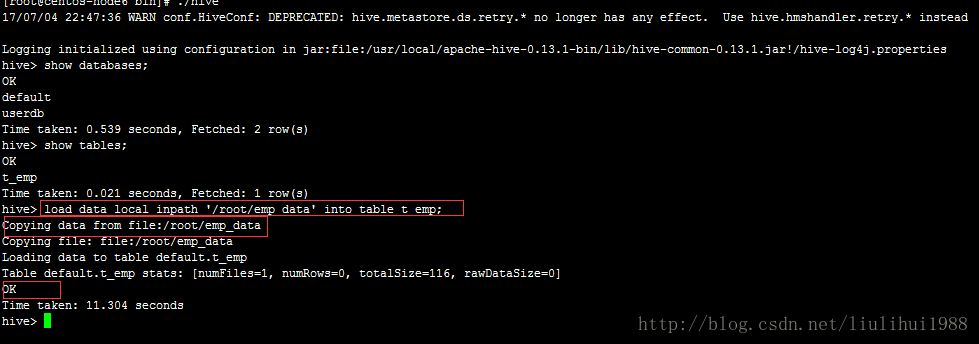
这时候我们查看Hadoop HDFS 的工作目录发现自动生成t_emp文件
/user/hive/warehouse/t_emp,Hive导入数据到t_emp表,(hadoop 环境变量)自动找到Hadoop HDFS 工作目录并且创建了工作目录

执行 select 语句查询统计
hive> select count(*) from t_emp where dept_name = '销售部' group by dept_name;Hadoop job information Mapreduce 执行结果

数据操作语言 DML
1、文件加载到表(本地导入)
Hive不做任何转换,数据加载到表中。加载操作目前纯复制/移动操作,实际上进入Hive位置对应表
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]- Hive从某个表导出到HDFS指定路径
export table t_emp to '/usr/input/emp.txt';2、插入数据到Hive表中
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2))
CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC;
INSERT INTO TABLE students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);3、更新Hive表数据
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]4、删除Hive表数据
DELETE FROM tablename [WHERE expression]5、查询插入Hive数据表dept_count (无分区)
create table dept_count(
dname string,
num int
);
insert into table dept_count select dept_name,count(1) from t_emp group by dept_name; 6、查询插入Hive数据表dept_count (有分区)
create table dept_count_1(
num int
) partitioned by (dname string);
insert into table dept_count_1 partition (dname = '销售部') select count(*) from t_emp where dept_name = '销售部' group by dept_name;
详细 见官方文档
https://cwiki.apache.org/confluence/display/Hive/LanguageManual