【正则表达式】正则表达式及python的re模块学习
以前经常听正则表达式,但自己从来没用过,这次刚好需要,就学习一下。
参考链接:
https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832260566c26442c671fa489ebc6fe85badda25cd000
http://www.runoob.com/regexp/regexp-syntax.html
http://www.runoob.com/python3/python3-reg-expressions.html
一、语法介绍
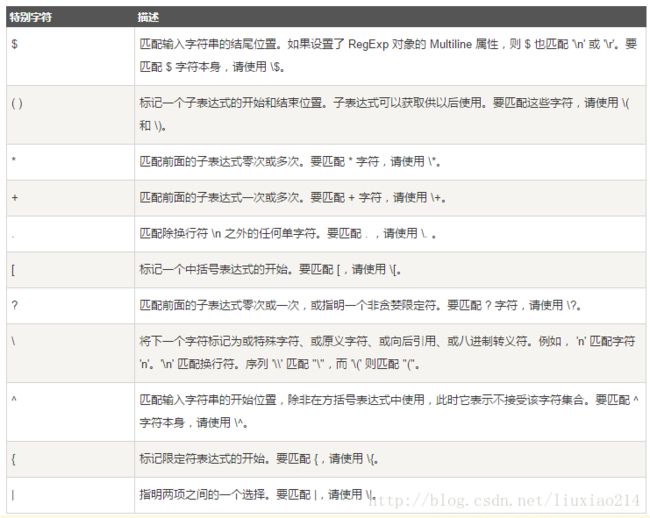
1.1 字符组成
正则表达式主要用于字符串匹配。
正则表达式是由普通字符和特殊字符组成的文字模式。
普通字符包括打印和非打印字符。

1.2 具体用法
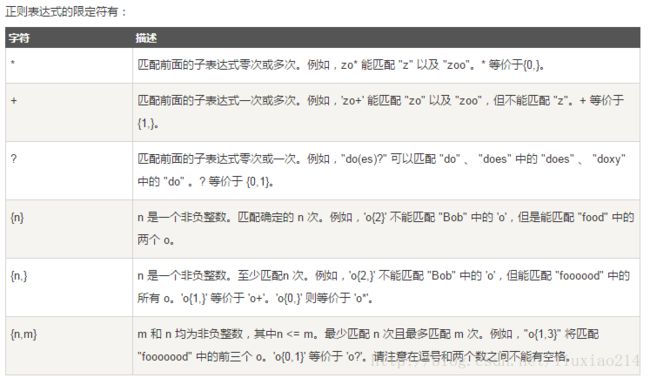
1、“\d”表示可以匹配一个数字,”\w”表示可以匹配一个数字或字母,”.”表示可以匹配除”\n”之外的所有字符,”*”表示包含0-n个字符,”+”表示包含1-n个字符,”?”表示包含0或1个字符。
举例:
“\d\d\d”可以匹配“345”
"\w\w\w"可以匹配"we2"
“a*”可以匹配“aaa”"aa"2、{n}表示含有n个字符,{n,m}表示含有n-m个字符。
举例:
"\d{3}\s+\d{3,9}"
表示可以匹配3个数字、空格1-n个,数字3-9个。
如:"231 34367"3、范围表示[]
[0-9a-zA-Z\_]表示可以匹配一个数字或字母或下划线,如"a","3"
[0-9a-zA-Z\_]+表示可以匹配由1-n个(数字或字母或下划线)组成的串,如"sdag1","sf321_12"
[a-zA-Z\_][0-9a-zA-Z\_]*表示可以匹配由一个字母或下划线开头,后面接0-n个(数字或字母或下划线)组成的串。我们在各种语言中定义的变量就是这种。
[a-zA-Z\_][0-9a-zA-Z\_]{0,19}表示可以匹配由一个字母或下划线开头,后面接0-19个(数字或字母或下划线)组成的串,即总长度在1-20之间。
4、”A|B”,表示匹配A或B
^表示行的开头,^\d表示必须以数字开头。
表示行的结束,\d 表 示 行 的 结 束 , \d 表示必须以数字结束。
^py$表示整行匹配,只能匹配’py’。
二、re模块
2.1 模块介绍
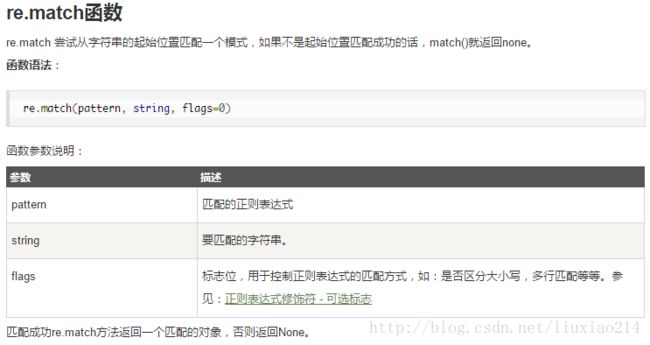
1、re.match函数
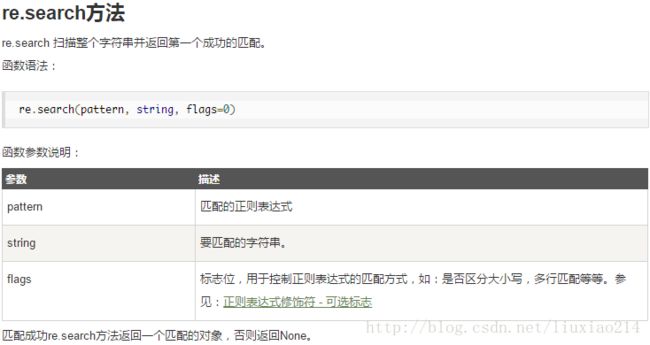
2、re.search函数
3、re.sub检索和替换函数
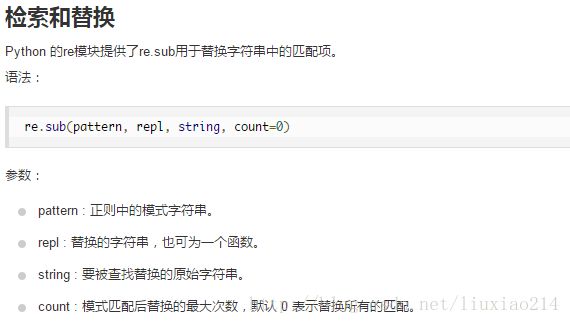
4、compile函数
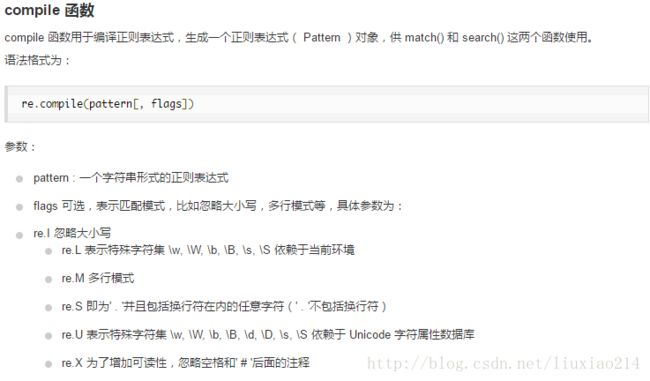
5、findall函数
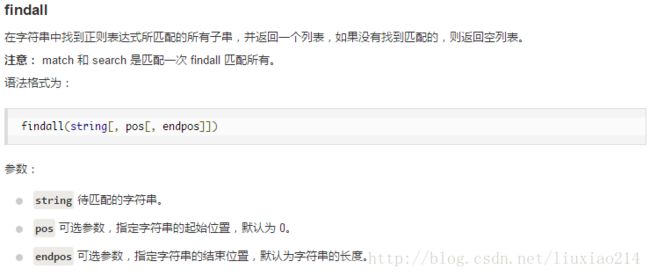
6、finditer函数
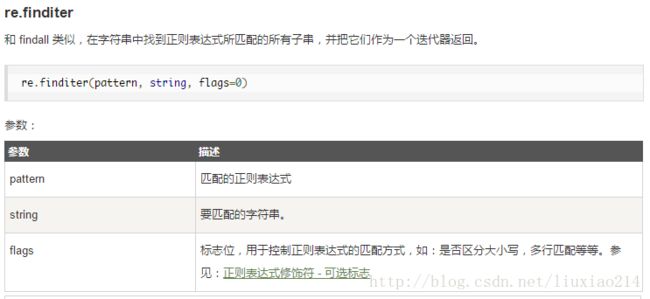
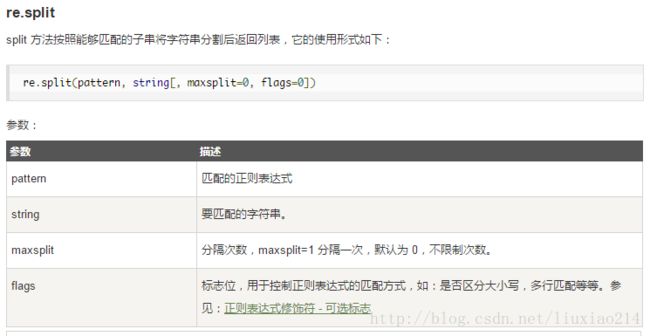
7、split函数
2.2 展开介绍
1、r
在表达式前加r,不用考虑转义问题。
s = "adb\\-sx2" 正则表达式:"adb\-sx2"
s = r"adb\-sx2"正则表达式:"adb\-sx2"
2、例子1,match匹配则返回一个Match对象,否则返回None
import re
a = re.match(r"\d{3}\-\d{6,8}","010-123467")
b = re.match(r"\d{3}\-\d{6,8}","010 123467")
print a
print b
if a:
print "yes"
else:
print "no"
if b:
print "yes"
else:
print "no"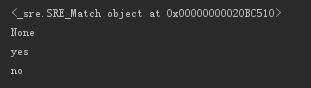
3、切割字符串,比如连续空格,分割所有不想要的
import re
s1 = "a b c d"
s2 = "a, b,c, d, e: f"
x1 = s1.split(" ")
x2 = re.split(r" +", s1)
x3 = re.split(r"[\s\,\:]+", s2)
print "x1=", x1
print "x2=", x2
print "x3=", x3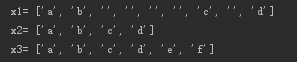
4、分组、提取子串,用()表示一组
import re
m = re.match(r"^(\d{3})-(\d{5,8})","010-123456")
print m
print m.group(0)
print m.group(1)
print m.group(2)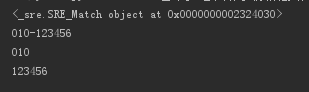
import re
time = "19:34:46"
m = re.match(r"(0[0-9]|1[0-9]|2[0-3]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9])", time)
print m.groups()
print m.group(1)
print m.group(2)
print m.group(3)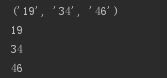
5、贪婪匹配
正则匹配默认是贪婪匹配,尽可能匹配更多的字符。
import re
m = re.match(r"^(\d+)(0*)$", "230010000")
print m.groups()![]()
这里我们本来想匹配两组,一组是末尾以0开头的0-n个组,一组是上一组的数字。
但是”\d+”采用贪婪匹配,把后面的“0000”页匹配了,导致”0*”没有匹配到。
所以要采用非贪婪匹配,”\d+”后面加个“?”就可以。
import re
m = re.match(r"^(\d+?)(0*)$", "230010000")
print m.groups()![]()
6、编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配。
import re
pattern = re.compile(r"^(\d{3})-(\d{5,9})$")
s1 = "010-1234567"
s2 = "212-3421534"
m1 = pattern.match(s1)
m2 = pattern.match(s2)
print m1.groups()
print m2.groups()![]()
7、作业1
请尝试写一个验证Email地址的正则表达式。版本一应该可以验证出类似的Email:
[email protected]
[email protected]
import re
pattern = re.compile(r"^[\w.]+@\w+.com$")
s1 = "[email protected]"
s2 = "[email protected]"
print pattern.match(s1).group()
print pattern.match(s2).group()![]()
8、作业2
版本二可以验证并提取出带名字的Email地址:
import re
pattern = re.compile(r"^(<[\w\s]+>)\s[\w.]+@\w+.\w+$")
s = " [email protected]"
print pattern.match(s).group()
print pattern.match(s).group(1)![]()
以上。