SSD 学习与研究
目标检测–SSD
论文地址:https://arxiv.org/abs/1512.02325
project:https://github.com/apache/incubator-mxnet/tree/master/example/ssd
其他参考链接:
1、https://blog.csdn.net/a8039974/article/details/77592395
2、https://www.cnblogs.com/fariver/p/7347197.html
3、https://www.sohu.com/a/168738025_717210
4、https://www.cnblogs.com/lillylin/p/6207292.html
5、https://cloud.tencent.com/developer/article/1052779
一、理解
1、对比
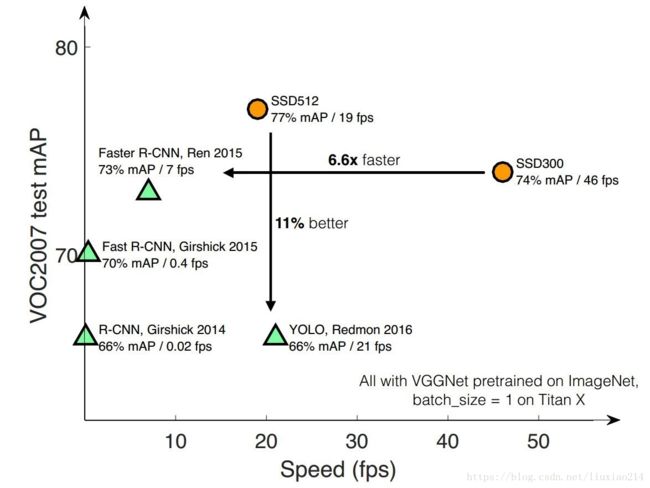
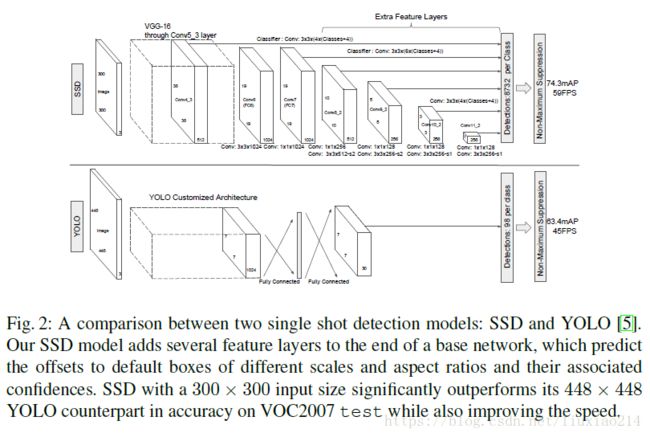
SSD的提出,为了解决实时性和准确性的问题。下面这种图给出了对比,SSD有两种模型,300和512代表不同size的输入图像。
SSD的主要思想就以下几点:
- 提出类似faster rcnn中的anchor机制,default box(与faster rcnn的区别:每个位置的default box一般是4~6个,Faster rcnn默认9个anchor;同时default box是设置在不同尺度的feature maps上的,且大小不同);
- 使用特征金字塔的方式,类似FPN,取多个feature map的预测结果,可以同时监测大目标和小目标;
- 同样是one-stage训练,采用回归的思想;
- 使用多种size的输入数据;
优缺点:
- 速度比YOLO快,准确率比faster rcnn高;
- 但是需要人工设置default box的min_size,max_size和aspect_ratio值,且每一层feature map下的值都不一样;
- 对小目标的召回仍然不理想,作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题;
2、核心思想
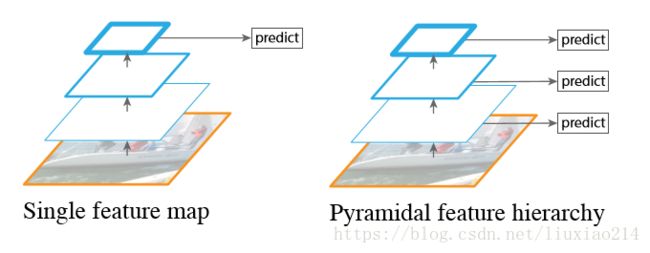
2.0 特征金字塔
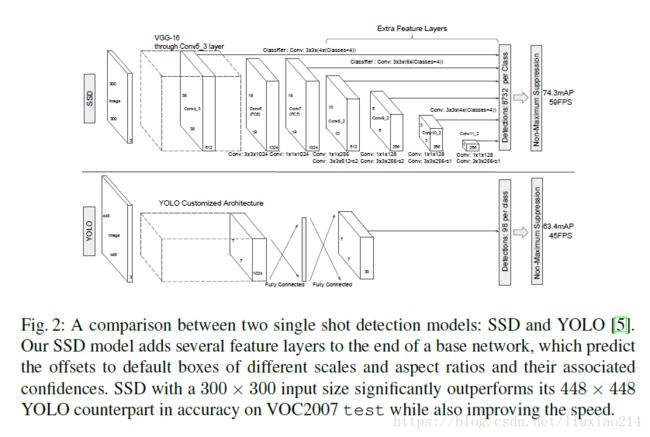
与YOLO直接在卷积层后加全连接不同,SSD使用多个卷积层进行预测,即不同size的feature map结果。SSD使用conv4_3、conv7(fc7)、conv8_2、conv9_2、conv10_2和conv11_2来预测定位和confidence,如下图所示。
特征金字塔的意思如下图所示。
2.1 default box
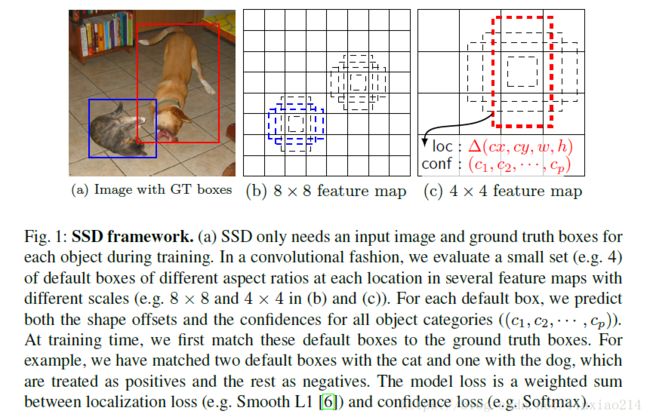
SSD中引入了default box,类似于faster rcnn中的anchor。但是不同于faster rcnn中,faster rcnn的默认anchor是9个,且只有最后特征层进行anchor提取。
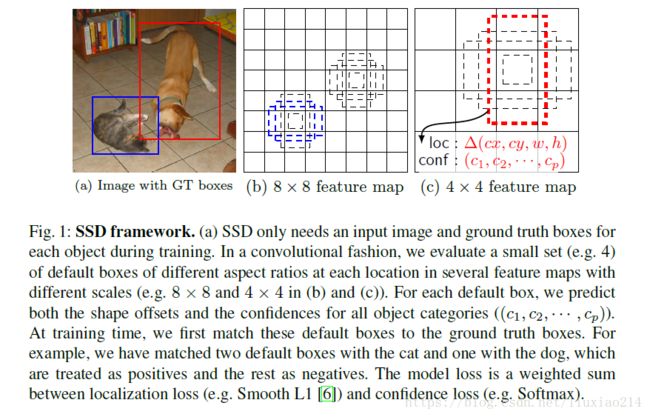
下面介绍SSD中的default box。其优点就是default box在不同的feature层有不同的scale,在同一个feature层又有不同的aspect ratio,基本上可以覆盖输入图像中的各种形状和大小的object。
- 以feature map的每个location,都会生成多个同心的default box;
- 宽高比为1,2,3,1/2,1/3;
- 当宽高比为1时,方形box,最小边长为min_size,最大边长为根号下(min_size*max_size);
- 长方形的长和宽分别为根号下(aspect_ratio)*min_size、1/根号下(aspect_ratio)*min_size;
- 每个feature map的min_size、max_size都不一样。
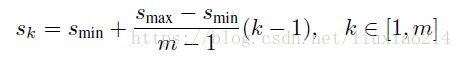
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.9,m是feature map的数量,SSD-300中m=6。
多个feature map生成的default box后,还经过 PriorBox 层生成 prior box(生成的是坐标)。每个feature map中每一层的default box的数量是给定的(8732个)。最后将前面三个计算结果分别合并然后传给loss层。
假定有8×8和4×4两种不同的feature map。假设每个feature map cell有k个default box,那么对于每个default box都需要预测c个类别score和4个offset,如果一个feature map的大小是m×n,则这个feature map就一共有(c+4)k * mn 个输出。
prior box,是指实际中选择的default box(每一个feature map cell 不是k个default box都取)。也就是说default box是一种概念,prior box则是实际的选取。
如果是图中的5层feature map,最后会得到(38384 + 19196 + 10106 + 556 + 334 + 114)= 8732个prior box。
2.2 匹配策略
- 正样本:与每一个groundtruth box有最大交并比的default box;或者default box与任意有一个groundtruth box的交并比超过了阈值;
- 负样本:正样本剩下的
由于负样本数量远大于正样本数量,所以在训练时,会挑选confidence高的box进行匹配,正负样本比为1:3;
2.3 损失函数
损失函数仍然分为两部分,confidence损失和location损失,如下面公式,其中N是所有default box的数量。
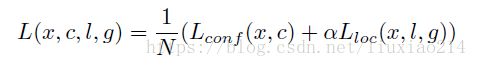
location损失采用smooth-L1损失,如下所示:
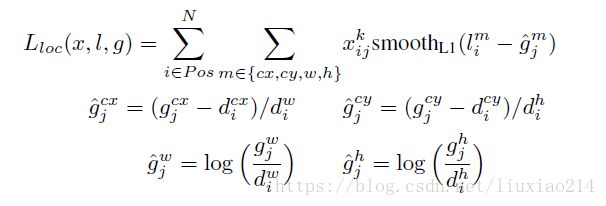
confidence损失使用softmax损失,如下,
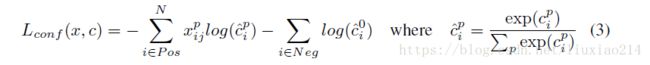
其中
![]()
表示第i个default box匹配到了第j个groundtruth box,类别是p。
粘来别人的具体解释:

2.4 训练
- 使用数据增强:有6.7%的mAP提升;包括随机裁剪,使得裁剪部分与目标重叠为0.1, 0.3, 0.5, 0.7, 0.9,剪裁完resize到固定尺寸;以0.5的概率进行水平翻转;
- 使用基础网络中的conv4_3进行检测,提升小目标的召回率;增加这一部分大概会提示4%mAP;
- 使用不同宽高比的default box会提升2.9%mAP;
- 使用atrous卷积,预训练模型VGG-16采用了atrous卷积,可以保持感受野不变的条件下,减少padding噪声。使用这种预训练模型会提高0.7mAP;
2.5 网络结构
SSD的结构在VGG16网络的基础上进行修改,
针对conv4_3(4),fc7(6),conv6_2(6),conv7_2(6) ,conv8_2(4),conv9_2(4)(括号里数字是每一层选取的default box种类)中的每一个再分别采用两个3*3大小的卷积核进行卷积,这两个卷积核是并列的,
- 这两个33的卷积核一个是用来做localization的(回归用,如果prior box是6个,那么就有64=24个这样的卷积核,卷积后map的大小和卷积前一样,因为pad=1,下同),
- 另一个是用来做confidence的(分类用,如果prior box是6个,VOC的object类别有20个,那么就有6*(20+1)=126个这样的卷积核)。
假设,conv6_2的localizaiton的33卷积核操作,卷积核个数是24(64=24,由于pad=1,所以卷积结果的map大小不变,下同),
这里的permute层就是交换的作用,比如你卷积后的维度是32×24×19×19,那么经过交换层后就变成32×19×19×24,顺序变了而已。
而flatten层的作用就是将32×19×19×24变成32*8664,32是batchsize的大小。
另一方面结合conv4_3(4),fc7(6),conv6_2(6),conv7_2(6),conv8_2(4),conv9_2(4)中的每一个和数据层(ground truth boxes)经过priorBox层生成prior box。
经过上述两个操作后,对每一层feature的处理就结束了。对前面所列的5个卷积层输出都执行上述的操作后,就将得到的结果合并:采用Concat,类似googleNet的Inception操作,是通道合并而不是数值相加。
二、论文翻译
1、摘要
提出一个比较小的深度神经网络用做图像中的目标检测。本文的方法称为SSD,对于每个feature map定位,将bounding box的输出空间描述为一组default box,有不同的宽高比、大小。在预测时,这个网络对每个default box,生成每个目标类别可能存在的分数,然后调整box以适合目标的shape。此外,这个网络结合了多种分辨率的feature map的预测,可以自然地处理各种大小的目标。SSD相对于那些需要目标proposal的方法来说要简单,因为它完全消除了proposal的产生和随后像素或特征的重采样步骤,将所有计算都压缩在一个简单网络中。这使得SSD很容易训练,并且可以直接整合到需要检测成分的系统中。在PASCAL VOC、COCO、ILSVR数据集上的实验结果证明,SSD对比那些使用额外目标proposal的方法具有可竞争性的准确率,并且比这些方法更快,为训练和推断提供了一个统一的框架。使用英伟达Titan X,对于300x300的输入,SSD在VOC2007测试数据集上,74.3%mAP,59FPS,对于512x512的输入,SSD是76.7%mAP,超过了faster RCNN。相对其他single-stage方法,SSD使用更小size的输入图像有更高的准确率。源码见: https://github.com/weiliu89/caffe/tree/ssd .
2、介绍
前面巴拉巴拉一堆废话。这篇论文提出第一个基于目标检测器的深度网络,而不依赖于对bounding box假设的像素或特征冲采样,并且同样准确。这个结果又很大的提升。在VOC2007测试集上,59FPS,74.3%mAP,而faster RCNN的7 FS,73.2%mAO,YOLO 45FPS,63.4%mAP。速度上的提高主要是消除了bounding box proposal和像素、特征的重采样步骤。本文并不是第一个做这些的,但是通过添加一系列的提高,我们比先前的尝试准确率有明显的提高。我们的提高包括,使用小的卷积核来预测目标类别和bounding box定位的偏移。分别使用不同比例的检测器预测,在网络的最后阶段,在多层feature map上应用这些filter,以实现多种scale的检测。这些修改,特别是使用不同scale的多层预测,我们可以实现相对低分辨率的输入的高准确率,进一步提高检测速度。尽管这些贡献似乎每个单独来说都比较小,但是对于在PASCAL VOC的实时检测上,YOLO只有63.4%mAP,而SSD有74.3%mAP。从最近有着高收益的残差网络来说,相对于检测正确来说,这个相对来说提升更大。进一步,高质量检测的速度显著提升可以扩展应用范围,计算机视觉是有用的。
本文的贡献点如下:
- 我们介绍了SSD,一个针对多目标的single-shot的检测器。比之前state-of-the-art的single-shot的检测器YOLO要快,并且准确率更高。事实上,相同准确率更慢的技术,使用明确的region proposals和池化(包括faster RCNN)
- SSD的核心是,对于一组default bounding box的修正集合,预测类别分数和box offset,对feature map使用小的卷积核。
- 为了实现高的检测准确率,我们对不同scale的feature map产生预测,然后通过宽高比分别采用这些预测。
- 这些设计的特征导致简单的端到端训练和高准确率,甚至是在低分辨率的输入图像上。进一步提高了速度。
- 实验包括模型在PASCAL VOC, COCO, and ILSVRC数据集上,不同输入大小之间关于时间和准确率的分析。并且于最近的state-of-the-art方法进行了比较。
3、The Single Shot Detector (SSD)
这一部分介绍提出的SSD框架和相关的训练方法。然后给出具体数据集的模型细节和实验结果。
3.1 model
SSD方法是基于前馈卷积神经网络,该网络产生固定大小的bounding box的集合,和这些box是否存在目标类别实例的分数,然后使用非极大值一直产生最终的检测。早期的网络层是基于标准架构,使用高质量图像分类(在任何分类层中删除顶端),我们称之为基础网络,然后将辅助功能添加到网络中以产生检测,具有以下关键特征:
多尺度feature map检测. 我们在截断基础网络后添加了卷积层,这些层的尺寸逐渐减小,并允许在多个尺度上预测检测。用于预测检测的卷积层对每个特征层(操作在单个尺度的feature map)是不一样的(参见overfeat、YOLO)。
针对检测的卷积预测器. 每一个添加的feature层(或者是从基础网络中选择已存在的一组),使用一组卷积核,都可以产生一组固定的检测预测集合。这些可以在图2中,SSD网络架构的顶端看到。对于一个feature层,其size为mnp通道,潜在检测的预测参数的基础元素是33p的卷积核,用来生成类别的分数或者相对于default box坐标的shape偏移。对m*n的每一个位置采用卷积核,将产生一个输出值。对于每个feature map的location,bounding box偏移输出值是相对于default box的位置计算的(参加YOLO的结构,直接使用全连接层的而不是卷积滤波器用于这一步)
default box和宽高比. 对网络顶层的多个feature map,我们将一组default bounding box的集合与每一个feature map cell相关联。default box以卷积的方式平铺feature map,因此每一个box的位置与其相对的cell是固定的。对每一个feature map cell,我们预测每个cell相对default box的shape的偏移,同样,也预测每一个类别分数,表明在每个box中这个类别实例的存在可能性。特别地,对给定location的k个box的每一个,我们计算c个类别分数和4个相对于原始default box shape的偏移。在feature map的每个location,有(c+4)k个滤波器,因此,对m*n的feature map,有(c+4)kmn个输出。有关default box的说明,可以参见图1.我们的default box相对于faster rcnn中使用的anchor box要小,但是我们在不同分辨率的几个feature map上使用。在几个feature map上允许不同的default box shape使得我们可以有效地离散可能的输出输出box shape空间。
3.2 training
在训练SSD和训练使用region proposal的典型检测器来说,其关键区别就是,在固定检测器输出集合上,groundtruth信息需要指定特定的输出。一些版本训练时也需要指定,如YOLO,还有faster-rcnn、multibox中的region proposal阶段。一旦配置决定,损失函数和反向传播就可以端到端。训练时也涉及到选择检测的default box和scale的集合,同样需要困难负样本的挖掘的数据增强策略。
匹配策略. 在训练时,我们需要确认,哪个default box与groundtruth检测相关联,并且进行相关地训练。对每个groundtruth box,我们从default box中选择,这些box的宽高比、尺寸都不一样。通过将每个groundtruth box与default box进行最佳jaccard重叠(如multibox)匹配。但不同于multibox,我们然后将default box与所有groundtruth进行了jaccard重叠超过0.5的进行了匹配。这简化了学习问题,允许网络对预测多个重叠的default 认box的高分,而不是只选取最大重叠的那个。
训练目标. SSD的训练目标源自multibox,但是扩展为处理多个目标类别。![]()
可以认为是类别p的第i的default box和第j个groundtruth box的匹配。在以上的匹配策略中,可以使得![]()
整个目标损失是定位损失的加权和confidence损失,如下:
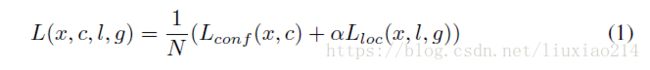
其中,N是匹配到的default box的数量。如果N=0,则损失设为0。定位损失采用预测box(l)和groundtruth box(g)参数之间的smooth l1损失。类似faster-rcnn,我们回归default bounding box(d)的中心偏置(cx, cy)和宽(w)、高(h)。
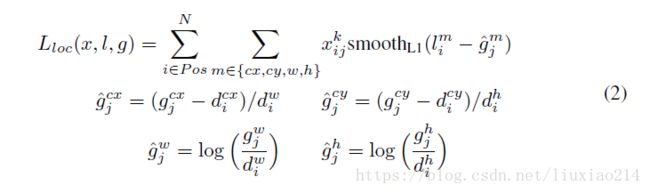
confidence损失是多个类别confidence©的softmax损失,其中权重参数α在交叉验证时设置为1。
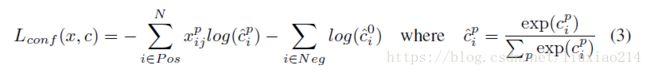
为default box选择尺度和宽高比. 为了处理不同尺度的目标,一些方法建议处理不同size的图像,然后再结合结果。然而,通过利用一个网络中的不同层的feature map来做预测,可以模仿相同的效果,且共享了所有尺度的目标的参数。先前的工作展示出,使用低层的feature map可以提到语义分割质量,因为低层捕捉到了输入目标更细节的东西。类似的,xx论文展示出,从一个feature map上添加全局环境池化可以帮助平滑分割结果。受这些方法启发,我们使用了高层和低层的feature map用来检测。图1中,两个feature map(8x8和4x4)用在了这个框架中。事实上,我们可以用一点小的开销,使用更多的feature map。
一个网络中不同层的feature map已知是不同感受野大小的。幸运的是,SSD框架,default box不需要与每一层的实际感受野相关联。我们设计了default box的平铺,因此指定feature map学习相应的特定尺度的目标。假设我们想要使用feature map来预测,每个feature map default box的尺度如下计算:
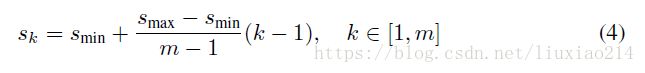
其中,s_min=0.2,s_max=0.9,意味着最低层的scale是0.2,最高层是0.9,中间所有层都是规律间隔。我们对default box施以不同宽高比,表示
![]()
![]()
我们可以为每一个default box计算其宽和高
![]()
对于宽高比为1,我们添加一个default box,其scale是
![]()
这样可以造成每个feature map location有6个default 认box。我们设置每个default box的中心是
![]()
其中|f_k|是第k个feature map的大小,切i,j属于[0, [f_k]]。事实上,也可以设计成default box的分布以最好的拟合特定数据集。如何设计最好tiling是一个开放的问题。
通过结果来自很多featuremap的所有location的不同scale和宽高比的所有default box的预测,我们有了大量预测集合。覆盖了不同size和shape的输入目标。例如,图一中,狗与4x4的feature map中的一个default 认box匹配,但是与8x8的feature map的所有default box都不匹配。这是因为这些不同scale的box不匹配狗的box,因此在训练中被认为是负样本。
hard negative挖掘. 在结束匹配后,大多数default box都是负的,特别是当可能的default box比较大的时候。这里介绍了一个明显的正负训练样本不均衡的例子。我们不使用所有的负样本,而是将这些负样本,按照每个default box的最高confidence 损失进行排序,并且选择最高的一个,因此正负样本的比例是1:3。我们发现,这可以导致更快的优化和更稳定的训练。
数据增强. 为了使得模型对于不同size和shape的输入更具有鲁棒性,每一个训练图像都使用下列方法进行随机采用:
- 使用整个原始的输入图像
- 采样一个图像块,使得与目标的最小jaccard重叠分别是 0.1, 0.3,0.5, 0.7, or 0.9.
- 随机采样图像块
每一个采样的图像块的发现都是原来图像size的[0.1, 1],并且宽高比在12与2之间。如果groundtruth box的中心在采样图像块中,我们保留与groundtruth box重叠的部分。在上述提到的采样之后,每一个采样的图像块被resize为固定的size,并且以0.5的概率进行水平翻转,此外还添加一些测光扭曲等。
4、Experimental Results
基础网络. 我们的网络是基于VGG-16的,并且在ILSVRC CLS-LOC数据集上进行了预训练。类似于DeepLab-LargeFOV,我们将fc6和fc7转换成了卷积层,下采样fc6和fc7的参数,改变pool5的池化核,将2x2改为3x3,然后使用 `a trous 算法来充满”holes”。我们去除了所有的dropout层和fc8层。使用SGD,初始学习率为0.001,momentum=0.9,weight decay=0.0005,batch size=32,进行微调结果。学习率衰减策略每个数据集都略有不同,细节稍后给出。开源代码见:https://github.com/weiliu89/caffe/tree/ssd
4.1 PASCAL VOC2007
在PASCAL VOC2007数据集上与fast rcnn、faster rcnn方法进行了比较,测试集是4952张图像。所有方法都是在预训练的VGG-16模型上微调的。
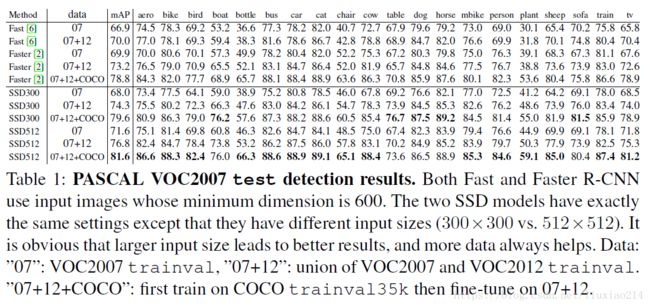
图2是SSD-300模型的网络细节。我们使用conv4_3、conv7(fc7)、conv8_2、conv9_2、conv10_2和conv11_2来预测定位和confidence。设置conv4_3的default box,scale=0.1。
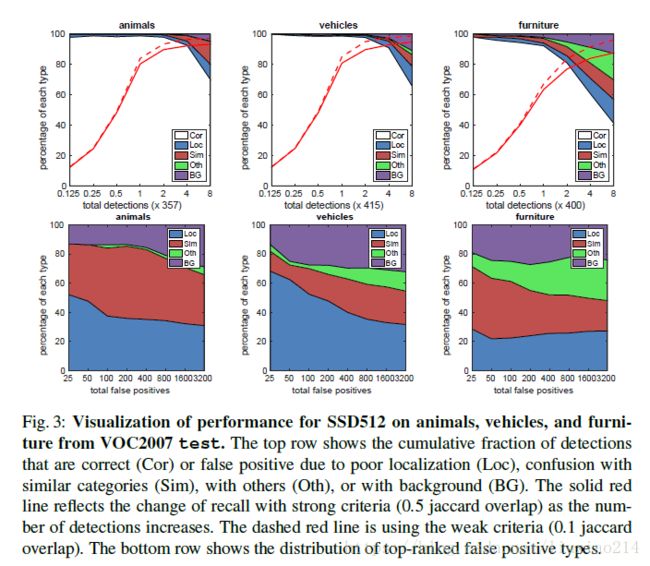
4.2 Model analysis

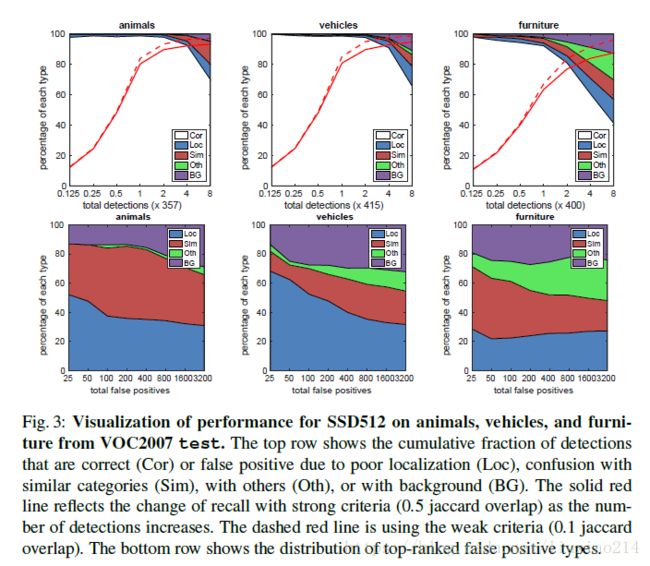

4.3 PASCAL VOC2012
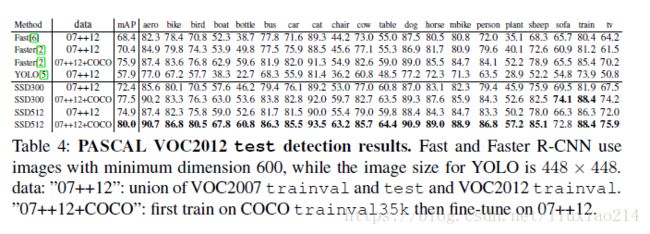
4.4 COCO
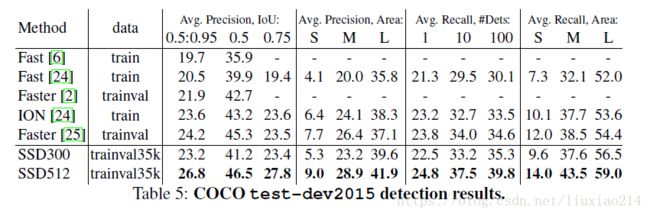
4.5 Preliminary ILSVRC results
4.6 Data Augmentation for Small Object Accuracy
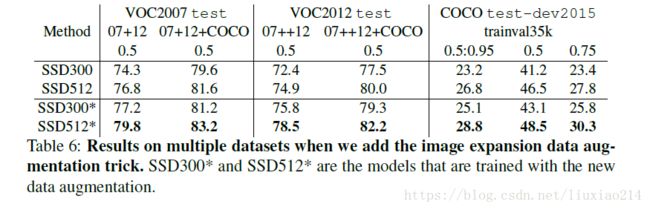
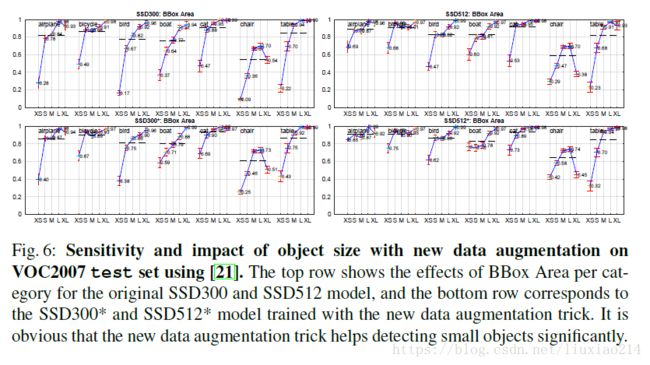
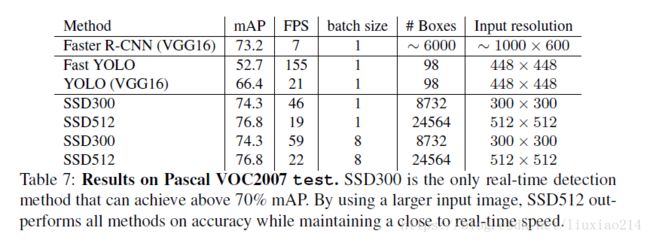
4.7 Inference time
5、结论
这篇论文介绍了SSD,一个基于多类别的快的single-shot的检测器。我们这个模型的关键特征是使用与网络顶层多个feature map匹配的mult-scale的卷积bounding box的输出。这种表示允许我们有效地训练可能的box的shape空间。我们进行实验验证了给定的合理的训练策略,一组数目很大的经过仔细选择的default box结果可以提高性能。与现有方法相比,我们建立的SSD模型,至少有一个数量级的box预测采样位置、scale、宽高比。我们表明,在给定相同的VGG-16基础架构,SSD相比之前的state-of-the-art目标检测器在准确率和速度上都实现了超越。我们的SSD-512明显地比state-of-the-art faster rcnn在PASCAL VOC 和 COCO数据集上的准确率要高,并且有3倍快。我们的实时SSD-300速度是59FPS,比目前的实时YOLO要快,且检测准确率更高很多。
除了这些独立的实用性,我们相信,我们的单片和相对简单的SSD模型为更大的需要目标检测的系统提供了有用的building block。一个充满希望的未来方向是探索使用RNN来检测,并同时跟踪视频目标,来作为系统的一部分使用。