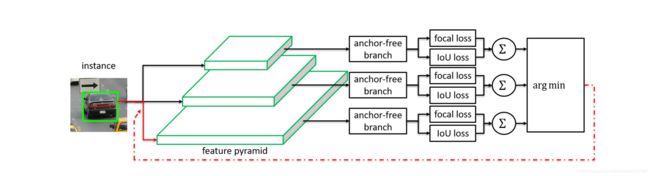
Feature Selective Anchor-Free Module for Single-Shot Object Detection
《Feature Selective Anchor-Free Module for Single-Shot Object Detection》发表于CVPR2019
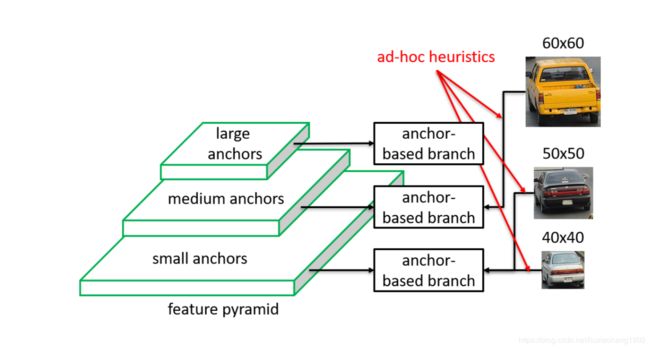
文章认为现有的anchor的检测方式,为了解决多尺度的问题,容易引入人为的一些规则,这样会导致检测结果不是最优的,比如常用的fpn结构,按照待检测物体的大小规定某些层检测一定大小区域的物体,如下图所示,6060使用某一层feature预测,5050或者40*40大小的物体使用另一层feature来预测。
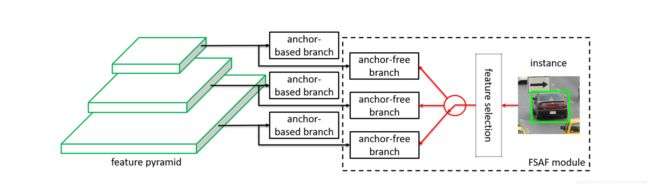
为了解决这种问题,文章提出了一种网络自动选择featuremap来预测不同的物体来进行物体的检测,如下示意图所示。
一、网络结构
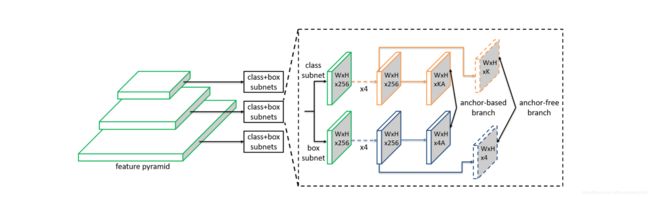
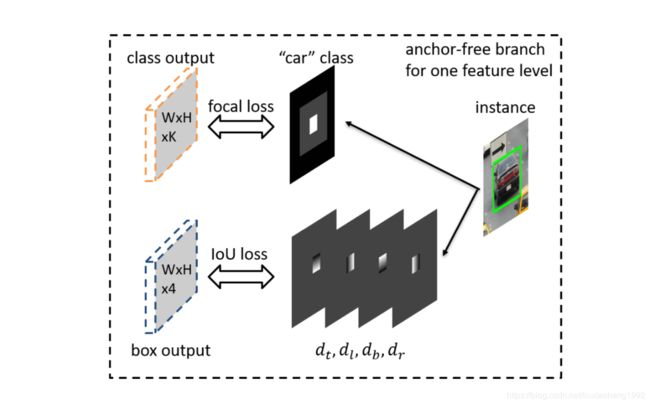
网络结构如下图所示,下图显示的是采用retinanet的结构加上FSAF模块,也就是本文提出的anchor free预测物体的模块,来进行物体的检测。如图中的虚线框中的虚线块所示,在fpn结构输出的几层不同尺寸的featuremap后,经过K个 3 × 3 3\times 3 3×3的卷积后在经过一个sigmoid层即得到分类的结果(这里的结果是指每个像素是那一类的结果)。同样的,使用4个 3 × 3 3\times 3 3×3的卷积在使用一层relu层即得到物体的位置结果(这里是指每个像素代表的框的位置)。下图其实还画出来了基于anchor的预测方式,表明此提出的方法可以很方便的将anchor预测方法和anchor-free的方法联合使用。
二、gt
与以前anchor的方式很不相同的是上面所说的每个像素代表一类和每个像素代表一个框的位置,要理解这一点就必须知道groundtruth是怎么生成的。这部分其实和17年的一篇做ocr的文章EAST
)很像,这里先定义几个概念。
投影框,有效框和忽略框
我们知道对于一个物体来说,标注有类别信息,比如属于k类,还有位置信息比如使用矩形框表示b=[x,y,w,h],其中(x, y)表示矩形框的中心点,(w, h)分别表示矩形框的宽和高。
投影框指的是因为fpn不同层的输出feature大小不一样,对于第 P l P_l Pl层feature来说,投影框用 b p l = [ x p l , y p l , w p l , h p l ] b^l_p=[x^l_p, y^l_p, w^l_p, h^l_p] bpl=[xpl,ypl,wpl,hpl]表示,它与原始标注框的关系为 b p l = b / 2 l b^l_p=b/2^l bpl=b/2l。
有效框定义为 b e l = [ x e l , y e l , w e l , h e l ] b^l_e=[x^l_e, y^l_e, w^l_e, h^l_e] bel=[xel,yel,wel,hel],有效框是相对于投影框来定义的,因为训练时,不同层的gt已经不是原始的标注框了,而是对应的投影框。 x e l = x p l , y e l = y p l , w e l = ϵ e w p l , h e l = ϵ e h p l x^l_e = x^l_p, y^l_e = y^l_p, w^l_e = \epsilon_e w^l_p, h^l_e = \epsilon_e h^l_p xel=xpl,yel=ypl,wel=ϵewpl,hel=ϵehpl,其中 ϵ e = 0.2 \epsilon_e=0.2 ϵe=0.2
忽略框定义为 b i l = [ x i l , y i l , w i l , h i l ] b^l_i = [x^l_i, y^l_i, w^l_i, h^l_i] bil=[xil,yil,wil,hil],其中忽略框也是相对于投影框来定义的, x i l = x p l , y i l = y p l , w i l = ϵ i w p l , h i l = ϵ i h p l x^l_i = x^l_p, y^l_i = y^l_p, w^l_i = \epsilon_i w^l_p, h^l_i = \epsilon_i h^l_p xil=xpl,yil=ypl,wil=ϵiwpl,hil=ϵihpl,这里 ϵ i = 0.5 \epsilon_i=0.5 ϵi=0.5
下面来看看真实标签的定义,如下图所示,对于car这个物体,需要两个标签,一个是类别标签,一个是距离标签。
2.1分类的标签
分类标签的真值有K个通道,每个通道代表一个类,这里那第k类的待测物体来说,它的类别标签来自于三个方向,第一个是有效框,有效框 b e l b^l_e bel内的像素全是正样本,如上图的白色区域。第二是忽略框内有效框外 ( b i l − b e l ) (b^l_i-b^l_e) (bil−bel),这部分是不参与计算的,如图中的灰色部分。第三,相邻feature层的忽略框 ( b ( l − 1 ) i , b ( l + 1 ) i ) (b^(l-1)_i, b^(l+1)_i) (b(l−1)i,b(l+1)i)也是本feature层需要忽略的。这里还需要注意的一点是,如果两个待测区域重叠,重叠部分优先选小的。剩余的区域为负样本。
这部分的训练采用的是focalloss,参数和原文一样。详情参考Focal Loss for Dense Object Detection论文详解
2.2 定位标签
定位标签有4个通道,这四个通道的值是像素到框的距离的偏移值。而且这里的有效像素是上面有效框里的像素。例如有个像素在图像中的位置为(i, j),且该像素在有效框内,在该位置上的四个通道值表示为, d i , j l = [ d t i , j l , d l i , j l , d b i , j l , d r i , j l ] d^l_{i,j}=[d^l_{t_{i,j}}, d^l_{l_{i,j}}, d^l_{b_{i,j}}, d^l_{r_{i,j}}] di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl],其中 d t i , j l , d l i , j l , d b i , j l , d r i , j l d^l_{t_{i,j}}, d^l_{l_{i,j}}, d^l_{b_{i,j}}, d^l_{r_{i,j}} dti,jl,dli,jl,dbi,jl,dri,jl分别表示为点(i, j)到投影框 b p l b^l_p bpl上,左,下,右边的距离。4个通道的真值为真值,所以值为 d i , j l / S d^l_{i,j}/S di,jl/S,这里 S = 4 S=4 S=4。
这部分的训练采用IoUloss。
三、推断
知道训练时标签的计算后,来看看推断怎么做的。
对于位置为(i, j)的像素,预测出的位置偏移值 [ o t i , j ^ , o l i , j ^ , o b i , j ^ , o r i , j ^ ] [\hat{o_{t_{i,j}}}, \hat{o_{l_{i,j}}}, \hat{o_{b_{i,j}}}, \hat{o_{r_{i,j}}}] [oti,j^,oli,j^,obi,j^,ori,j^],计算出的预测为 [ S o t i , j ^ , S o l i , j ^ , S o b i , j ^ , S o r i , j ^ ] [S\hat{o_{t_{i,j}}}, S\hat{o_{l_{i,j}}}, S\hat{o_{b_{i,j}}}, S\hat{o_{r_{i,j}}}] [Soti,j^,Soli,j^,Sobi,j^,Sori,j^],那么预测投影框的左上角点和右下角点为 ( i − S o t i , j ^ , j − S o l i , j ^ ) (i-S\hat{o_{t_{i,j}}}, j-S\hat{o_{l_{i,j}}}) (i−Soti,j^,j−Soli,j^)和 ( i + S o b i , j ^ , j + S o r i , j ^ ) (i+S\hat{o_{b_{i,j}}}, j+S\hat{o_{r_{i,j}}}) (i+Sobi,j^,j+Sori,j^),最后乘以相应的倍数 2 l 2^l 2l得到预测框。
对于置信度为所有通道中位置为(i, j)的最大值。
四、Online Feature Selection
上面提到的本文提出了一种方法不用人为的定义哪些feature检测哪些物体。对于待测物体I来说,我们定义在feature P l P_l Pl分类loss和定位loss为 L F L I ( l ) L^I_{FL}(l) LFLI(l)和 L I o U I ( l ) L^I_{IoU}(l) LIoUI(l),它们是每个像素的平均值。
L F L I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l F L ( l , i , j ) L^I_{FL}(l)=\frac{1}{N(b^l_e)}\sum_{i,j\in b^l_e}FL(l,i,j) LFLI(l)=N(bel)1∑i,j∈belFL(l,i,j)和 L I o U I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l I o U ( l , i , j ) L^I_{IoU}(l)=\frac{1}{N(b^l_e)}\sum_{i,j\in b^l_e}IoU(l,i,j) LIoUI(l)=N(bel)1∑i,j∈belIoU(l,i,j), N ( b e l ) N(b^l_e) N(bel)是为在有效框 b e l b^l_e bel内像素的总数。 F L ( l , i , j ) FL(l,i,j) FL(l,i,j)和 I o U ( l , i , j ) IoU(l,i,j) IoU(l,i,j)为像素(i,j)在feature P l P_l Pl上的focal loss和IoU loss。
下图所示,展示来如何选feature,它是通过选择最小的loss来选的,有点像ohem的感觉,公式表示为
l ∗ = a r g m i n l L F L I ( l ) + L I o U I ( l ) l^* = argmin_l L^I_{FL}(l)+L^I_{IoU}(l) l∗=argminlLFLI(l)+LIoUI(l)