数据挖掘学习(四)——常见案例总结
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

1、K-meaning算法实战
主要是通过均值来聚类的一个方法。
步骤为:
1)随机选择k个点作为聚类中心;
2)计算各个点到这k个点的距离,将距离相近的点聚集在一起,行程k个类;
3)将对应的点聚到与他最近的聚类中心;
4)分成k个聚类之后,重新计算聚类中心;
5)比较当前聚类中心与前一次聚类中心,如果是同一个点,则聚类收敛,得到聚类结果;如果为不同的点,则重复第二到五步。
#!/usr/bin/env python
# _*_ UTF-8 _*_
import numpy as npy
import pandas as pda
import matplotlib.pylab as pyl
# 通过程序实现录取学生的聚类;
fname = "F:/python_workspace/file/collection_method/luqu.csv"
dataf = pda.read_csv(fname)
x = dataf.iloc[:, 1:4].as_matrix()
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
# 调用kmeans方法,指定聚4类。
kms = KMeans(n_clusters=4)
y = kms.fit_predict(x)
# 一个y代表一个点,数字表示属于第几类。
print(y)
print(x)
# x代表学生
s = npy.arange(0, len(y))
pyl.plot(s, y, "o")
pyl.show()
# 通过聚类实现商品的聚类:
# 淘宝商品的聚类:
import matplotlib.pylab as pyl
import pymysql
conn = pymysql.connect(host="localhost",
user="root",
password="123456",
db="livan",
port=3306,
charset='utf8')
sql="select price, comments from goods"
dataf2 = pda.read_sql(sql, conn)
x = dataf2.iloc[:,:].as_matrix()
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
# 调用kmeans方法,指定聚3类。
kms = KMeans(n_clusters=3)
y = kms.fit_predict(x)
print(y)
for i in range(0, len(y)):
if(y[i]==0):
pyl.plot(dataf2.iloc[i:i+1, 0:1].as_matrix(),
dataf2.iloc[i:i+1, 1:2].as_matrix(),
"*r")
elif(y[i]==1):
pyl.plot(dataf2.iloc[i:i+1, 0:1].as_matrix(),
dataf2.iloc[i:i+1, 1:2].as_matrix(),
"sy")
elif(y[i]==2):
pyl.plot(dataf2.iloc[i:i+1, 0:1].as_matrix(),
dataf2.iloc[i:i+1, 1:2].as_matrix(),
"pk")
pyl.show()
2、决策树:
#!/usr/bin/env python
# _*_ UTF-8 _*_
import pandas as pda
# 信息熵:信源的不确定度。
fname = "F:/python_workspace/file/lessons.csv"
dataf = pda.read_csv(fname)
# 提取某行列,然后转换成矩阵[行,列]
x = dataf.iloc[:, 1:5].as_matrix()
y = dataf.iloc[:, 5].as_matrix()
# x为二维数组,可以对其进行遍历,遇到是、多等字段变为1
# 遇到否、少等字段变为0;
for i in range(0, len(x)):
for j in range(0, len(x[i])):
thisdata = x[i][j]
if(thisdata =="是" or thisdata=="多" or thisdata=="高"):
x[i][j] = int(1)
else:
x[i][j] = -1
for i in range(0, len(y)):
thisdata = y[i]
if(thisdata=="高"):
y[i] = 1
else:
y[i] = -1
# 容易错的地方:
# 正确的做法为:转化好格式,将xy转化为数据框,然后再转化为数组并制定格式。
xf = pda.DataFrame(x)
yf = pda.DataFrame(y)
x2 = xf.as_matrix().astype(int)
y2 = yf.as_matrix().astype(int)
# 建立决策树:
from sklearn.tree import DecisionTreeClassifier as DTC
# 信息熵的模式entropy
dtc = DTC(criterion="entropy")
dtc.fit(x2, y2)
# 直接预测销量高低:
import numpy as npy
x3 = npy.array([[1, -1, -1, 1], [1, 1, 1, 1], [-1, 1, -1, 1]])
rst = dtc.predict(x3)
print(rst)# 可视化决策树:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("F:/python_workspace/file/decision_tree/dtc.dot", "w") as file:
# 参数为:模式、特征值(实战、课时数、是否促销、是否提供配套资料)
export_graphviz(dtc, feature_names=["combat", "num", "promotion", "datum"], out_file=file)
# 此时已经生成决策树,但是dot的文件打不开,此时需要使用graph的软件打开。
Dot的使用方法:

可以得到决策树:

决策树往左看——负能量;往右看——正能量;
Entropy是信息熵,value是销量高地的统计情况【14,15】:即14是销量低的,15是销量高的。决策树会通过一层层的使用特征值,来划分数据。
3、逻辑回归:
求解逻辑回归参数的传统方法是梯度下降,构造为凸函数的代价函数后,每次沿着偏导方向(下降速度最快方向)迈进一小部分,直至N次迭代后到达最低点。
#!/usr/bin/env python
# _*_ UTF-8 _*_
import pandas as pda
fname = "F:/python_workspace/file/logic/luqu.csv"
dataf = pda.read_csv(fname)
# [行,列]
x = dataf.iloc[:, 1:4].as_matrix()
y = dataf.iloc[:, 0:1].as_matrix()
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
# 建立一个逻辑回归模型
r1 = RLR()
# 训练模型
r1.fit(x, y)
# 特征值筛选,获取有效特征。
r1.get_support()
# print(dataf.columns[r1.get_support()])
# 将可用的特征值参数转换成数组,用来预测y值。
t = dataf[dataf.columns[r1.get_support()]].as_matrix()
r2 = LR()
# 建立xy之间的关系并进行训练。
r2.fit(t, y)
print("训练结束")
print("模型正确率为:"+str(r2.score(x, y)))4、贝叶斯分类器:
思路为:
1、给定一个训练集、一个对应的标签集,训练集中的每一个数据点x(对应有多个维度(a1,a2,a3,a4))对应有一个标签A,即该训练集已经做好分类。
2、对给定的标签集进行计算,各个标签A在标签集中占的比例即为训练集中某一类A出现的出现概率。
3、在训练集中,某一类别中的数据有多个维度(a1,a2,a3,a4),各个维度值在这一类别A中的比例可以计算得出。
4、然后再使用贝叶斯公式计算新出现的数据的概率。
#!/usr/bin/env python
# _*_ UTF-8 _*_
import numpy as npy
# 贝叶斯分类:
class Bayes:
def __init__(self):
# -1表示测试方法没有做,表示没有进行训练。
self.length = -1
# 分类的类别标签
self.labelcount = dict()
self.vectorcount = dict()
# 训练函数:(dataSet:list 训练集指定为list类型)
def fit(self, dataSet:list, labels:list):
if(len(dataSet)!=len(labels)):
raise ValueError("您输入的测试数组跟类别数组长度不一致~")
self.length = len(dataSet[0]) # 测试数据特征值的长度。
# 所有类别的数据
labelsnum = len(labels)
# 不重复的类别的数量
norepeatlabel = set(labels)
# 以此遍历各个类别
for item in norepeatlabel:
# 计算当前类别占总类别的比例:
# thislabel为当前类别
thislabel = item
# 当前类别在总类别中的比例;
labelcount[thislabel]= labels.count(thislabel)/labelsnum
for vector, label in zip(dataSet, labels):
if(label not in vectorcount):
self.vectorcount[label]= []
self.vectorcount[label].append(vector)
print("训练结束~")
return self
# 测试数据:
def btest(self, TestData, labelsSet):
if(self, length==-1):
raise ValueError("您还没有进行训练,请先训练~~")
# 计算testdata分别为各个类别的概率:
lbDict = dict()
for thislb in labelsSet:
p = 1
# 当前类别占总类别的比例:
alllabel = self.labelcount[thislb]
# 当前类别中的所有向量:
allvector = self.vectorcount[thislb]
# 当前类别一共有多少个向量:
vnum = len(allvector)
# 数组转置
allvector =npy.array(allvector).T
for index in range(0, len(TestData)):
vector = list(allvector[index])
p* = vector.count(TestData[index])/vnum
lbDict[thislb] = p*alllabel
thislabel = sorted(lbDict, key=lambda x:lbDict[x], reverse=True)[0]
return thislabel
5、KNN手写体数字识别:
此处使用画图工具,建立一个含手写体数字的图片文件,然后找一些训练数据:
1)训练数据:
0、1、2、3、4、5、6、7、8、9,共十种手写体数据,用来训练程序,此处使用trainDigits;
2)测试数据:
即将之前的图片转换成的txt文件作为测试文件,此处使用testDigits;
3)图片处理:
在进行二维码或者图片数字识别时,需要将图片转换成txt的二进制文件,行程一个文件流。
KNN算法的主要思路为:
1)计算输入点与训练集中点的位置(欧式距离算法);
2)对计算出来的数据按照从小到大排序,最前面的为输入点到训练集中点的最短距离;
3)取出前k个距离值,并对距离值进行分组;
4)标记各组数据的多少,最多的标签值即为输入点的所在类别。
#!/usr/bin/env python
# _*_ UTF-8 _*_
from PIL import Image
from numpy import *
import operator
from os import listdir
# # 图片处理
# # 先将所有图片转换为固定宽高,比如:32*32,然后再转换成文本。
# im = Image.open("F:/python_workspace/file/hand_write/hand_write.png")
# # 另存为图片:
# #im.save("F:/python_workspace/file/hand_write/hand_write.jpg")
# fh =open("F:/python_workspace/file/hand_write/hand_write.txt","a")
# # 获取图片的长宽高: 0:宽;1:高;
# width = im.size[0]
# height = im.size[1]
# # 获取像素(宽为1,高为9的像素):
# # (255, 255, 255):白色
# # (0,0,0):黑色
# for i in range(0, width):
# for j in range(0, height):
# cl = im.getpixel((i, j))
# clall = cl[0]+cl[1]+cl[2]
# if(clall == 0):
# # 黑色;
# fh.write("1")
# else:
# fh.write("0")
# fh.write("\n")
# fh.close()
# 运算knn函数:
def knn(k, testdata, traindata, labels):
traindatasize = traindata.shape[0]
dif = tile(testdata, (traindatasize, 1))-traindata
sqdif = dif**2
sumsqdif =sqdif.sum(axis=1)
distance = sumsqdif**0.5
sortdistance =distance.argsort()
count = {}
for i in range(0, k):
vote = labels[sortdistance[i]]
count[vote] = count.get(vote, 0)+1
sortcount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
return sortcount[0][0]
# 手写体数字的识别:
# 1.加载数据
def datatoarray(fname):
arr = []
fh = open(fname)
for i in range(0, 32):
thisline = fh.readline()
for j in range(0, 32):
arr.append(int(thisline[j]))
return arr
# arr1 = datatoarray("F:/python_workspace/file/hand_write/trainingDigits/0_10.txt")
# print(arr1)
# 建立一个函数取文件的前缀:
def seplabel(fname):
filestr = fname.split(".")[0]
label = int(filestr.split("_")[0])
return label
# 2.建立训练数据:
def traindata():
labels = []
# 加载当前目录下的所有文件名:
trainfile =listdir("F:/python_workspace/file/hand_write/trainingDigits")
num = len(trainfile)
# 长度为1024,即为1024列,每一行存储一个文件。
# 用一个数组存储所有训练数据,行:文件总数;列:1024
# 用zeros建立一个数组:
trainarr =zeros((num, 1024))
for i in range(0, num):
thisfname = trainfile[i]
# 返回的是训练数字labels(0--9)
thislabel =seplabel(thisfname)
labels.append(thislabel)
# 将所有文件的训练集数据内容加载到trainarr中。
trainarr[i, :] =datatoarray("F:/python_workspace/file/hand_write/trainingDigits/"+thisfname)
return trainarr, labels
# 3.用测试数据调用knn算法测试,看是否能够准确识别:
def datatest():
trainarr, labels =traindata()
testlist = listdir("F:/python_workspace/file/hand_write/testDigits")
tnum = len(testlist)
for i in range(0, tnum):
thistestfile = testlist[i]
testarr = datatoarray("F:/python_workspace/file/hand_write/testDigits/"+thistestfile)
rknn = knn(3, testarr, trainarr, labels)
print(rknn)
datatest()
# 4.抽某一个测试文件出来进行试验:
trainarr, labels = traindata()
thistestfile = "6_6.txt"
testarr = datatoarray("F:/python_workspace/file/hand_write/testDigits/"+thistestfile)
rknn = knn(3, testarr, trainarr, labels)
print(rknn)
6、贝叶斯手写体数字识别:
#!/usr/bin/env python
# _*_ UTF-8 _*_
import numpy as npy
from numpy import *
from os import listdir
# 贝叶斯算法的应用:
class Bayes:
def __init__(self):
# -1表示测试方法没有做,表示没有进行训练。
self.length = -1
# 分类的类别标签
self.labelcount = dict()
self.vectorcount = dict()
# 训练函数:(dataSet:list 训练集指定为list类型)
def fit(self, dataSet:list, labels:list):
if(len(dataSet)!=len(labels)):
raise ValueError("您输入的测试数组跟类别数组长度不一致~")
self.length = len(dataSet[0]) # 测试数据特征值的长度。
# 所有类别的数据
labelsnum = len(labels)
# 不重复的类别的数量
norepeatlabel = set(labels)
# 以此遍历各个类别
for item in norepeatlabel:
# 计算当前类别占总类别的比例:
# thislabel为当前类别
thislabel = item
# 当前类别在总类别中的比例;
self.labelcount[thislabel]= labels.count(thislabel)/labelsnum
for vector, label in zip(dataSet, labels):
if(label not in self.vectorcount):
self.vectorcount[label]= []
self.vectorcount[label].append(vector)
print("训练结束~")
return self
# 测试数据:
def btest(self, TestData, labelsSet):
if(self.length==-1):
raise ValueError("您还没有进行训练,请先训练~~")
# 计算testdata分别为各个类别的概率:
lbDict = dict()
for thislb in labelsSet:
p = 1
# 当前类别占总类别的比例:
alllabel = self.labelcount[thislb]
# 当前类别中的所有向量:
allvector = self.vectorcount[thislb]
# 当前类别一共有多少个向量:
vnum = len(allvector)
# 数组转置
allvector =npy.array(allvector).T
for index in range(0, len(TestData)):
vector = list(allvector[index])
p = vector.count(TestData[index])/vnum
lbDict[thislb] = p*alllabel
thislabel = sorted(lbDict, key=lambda x:lbDict[x], reverse=True)[0]
return thislabel
# 手写体数字的识别:
# 1.加载数据
def datatoarray(fname):
arr = []
fh = open(fname)
for i in range(0, 32):
thisline = fh.readline()
for j in range(0, 32):
arr.append(int(thisline[j]))
return arr
# 建立一个函数取文件的前缀:
def seplabel(fname):
filestr = fname.split(".")[0]
label = int(filestr.split("_")[0])
return label
# 2.建立训练数据:
def traindata():
labels = []
# 加载当前目录下的所有文件名:
trainfile =listdir("F:/python_workspace/file/hand_write/trainingDigits")
num = len(trainfile)
# 长度为1024,即为1024列,每一行存储一个文件。
# 用一个数组存储所有训练数据,行:文件总数;列:1024
# 用zeros建立一个数组:
trainarr =zeros((num, 1024))
for i in range(0, num):
thisfname = trainfile[i]
# 返回的是训练数字labels(0--9)
thislabel =seplabel(thisfname)
labels.append(thislabel)
# 将所有文件的训练集数据内容加载到trainarr中。
trainarr[i, :] =datatoarray("F:/python_workspace/file/hand_write/trainingDigits/"+thisfname)
return trainarr, labels
bys = Bayes()
# 训练数据:
train_data, labels =traindata()
bys.fit(train_data, labels)
# 测试:
thisdata = datatoarray("F:/python_workspace/file/hand_write/trainingDigits/8_90.txt")
labelsall = [0,1,2,3,4,5,6,7,8,9]
# 识别单个手写体数字:
# rst = bys.btest(thisdata, labelsall)
# print(rst)
# 识别多个手写体数字(批量测试):
testfileall = listdir("F:/python_workspace/file/hand_write/trainingDigits")
num = len(testfileall)
for i in range(0, num):
thisfilename = testfileall[i]
thislabel = seplabel(thisfilename)
thisdataarray = datatoarray("F:/python_workspace/file/hand_write/testDigits/"+thisfilename)
label = bys.btest(thisdataarray, labelsall)
print("该数字正确的是:"+str(thislabel)+",识别出来的数字是:"+str(label))
if(label!=thislabel):
x+=1
print(x)
print("错误率是:"+str(x/num))
7、神经网络课程销量识别:
#!/usr/bin/env python
# _*_ UTF-8 _*_
import pandas as pda
# BP人工神经网络的实现
# 1、读取数据;
# 2、keras.models 下面有:Sequential:建立模型使用
# keras.layers.core下面有以下两个函数:
# Dense:建立层(输入层、输出层)
# Activation: 添加函数(激活函数)
# 3、建立神经网络模型,通过sequential建立
# 4、建立层,通过Dense建立。
# 5、设置激活函数:Activation。
# 6、模型编译,使用compile
# 7、训练:fit(),即学习的过程。
# 8、验证:测试阶段,分类预测等。
# 1\数据的读取与整理:
fname = "F:/python_workspace/file/BP_nets/lessons.csv"
dataf = pda.read_csv(fname, encoding='utf-8')
x = dataf.iloc[:, 1:5].as_matrix()
y = dataf.iloc[:, 5].as_matrix()
for i in range(0, len(x)):
for j in range(0, len(x[i])):
thisdata = x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j] = int(1)
else:
x[i][j] = -1
for i in range(0, len(y)):
thisdata = y[i]
if(thisdata=="高"):
y[i] = 1
else:
y[i] = -1
xf = pda.DataFrame(x)
yf = pda.DataFrame(y)
x2 = xf.as_matrix().astype(int)
y2 = yf.as_matrix().astype(int)
# 使用人工神经网络模型:
from keras.models import Sequential
from keras.layers.core import Dense, Activation
# 构建人工神经网络:
model = Sequential()
# 建立输入层:
model.add(Dense(10, input_dim=len(x2[0])))
# 建立输入层激活函数:
model.add(Activation("relu"))
# 建立输出层:
model.add(Dense(1, input_dim=1))
# 建立输出层激活函数:
model.add(Activation("sigmoid"))
# 模型的编译,参数为(损失函数,求解方法, 模式):,class_mode="binary"
model.compile(loss="binary_crossentropy", optimizer="adam")
# 训练nb_epoch:制定学习的次数;batch_size:批大小
model.fit(x2, y2, nb_epoch=100, batch_size=100)
# 预测分类:预测x所有数组的各个特征的y值
rst = model.predict_classes(x).reshape(len(x))
# print(rst)
x = 0
for i in range(0, len(x2)):
if(rst[i]!=y[i]):
x+=1
# 准确率:
print(1-x/len(x2))
# 课程销量预测:
import numpy as npy
x3 = npy.array([[1,-1,-1,1],[1,1,1,1],[-1,1,-1,1]])
rst2 = model.predict_classes(x3).reshape(len(x3))
print("预测结果为:"+str(rst2))
8、神经网络手写体数字识别:
#!/usr/bin/env python
# _*_ UTF-8 _*_
from numpy import *
import operator
from os import listdir
import numpy as npy
import numpy
import pandas as pda
def datatoarray(fname):
arr = []
fh = open(fname)
for i in range(0, 32):
thisline = fh.readline()
for j in range(0, 32):
arr.append(int(thisline[j]))
return arr
# 建立一个函数用来取文件名前缀:
def seplabel(fname):
filestr = fname.split(":")[0]
label = int(filestr.split("_")[0])
return label
# 2.建立训练数据:
def traindata():
labels = []
# 加载当前目录下的所有文件名:
trainfile =listdir("F:/python_workspace/file/hand_write/trainingDigits")
num = len(trainfile)
# 长度为1024,即为1024列,每一行存储一个文件。
# 用一个数组存储所有训练数据,行:文件总数;列:1024
# 用zeros建立一个数组:
trainarr =zeros((num, 1024))
for i in range(0, num):
thisfname = trainfile[i]
# 返回的是训练数字labels(0--9)
thislabel = seplabel(thisfname)
labels.append(thislabel)
# 将所有文件的训练集数据内容加载到trainarr中。
trainarr[i, :] =datatoarray("F:/python_workspace/file/hand_write/trainingDigits/"+thisfname)
return trainarr, labels
trainarr, labels = traindata()
# 传数据框:
xf = pda.DataFrame(trainarr)
yf = pda.DataFrame(labels)
# 转为数组:
tx2 = xf.as_matrix().astype(int)
ty2 = yf.as_matrix().astype(int)
# 以上为数据读取部分,下面构建人工神经网络模型:
# 使用人工神经网络模型:
from keras.models import Sequential
from keras.layers.core import Dense, Activation
# 构建人工神经网络:
model = Sequential()
# 建立输入层:
model.add(Dense(10, input_dim=len(tx2[0])))
# 建立输入层激活函数:
model.add(Activation("relu"))
# 建立输出层:
model.add(Dense(1, input_dim=1))
# 建立输出层激活函数:
model.add(Activation("sigmoid"))
# 模型的编译,参数为(损失函数,求解方法, 模式):,class_mode="binary"
model.compile(loss="mean_squared_error", optimizer="adam")
# 训练nb_epoch:制定学习的次数;batch_size:批大小
model.fit(tx2, ty2, nb_epoch=1000, batch_size=6)
# 预测分类:预测x所有数组的各个特征的y值
rst = model.predict_classes(x).reshape(len(x))
# print(rst)
x = 0
for i in range(0, len(x2)):
if(rst[i]!=y[i]):
x+=1
# 准确率:
print(1-x/len(x2))
# 课程销量预测:
import numpy as npy
tx3 = npy.array([[1,-1,-1,1],[1,1,1,1],[-1,1,-1,1]])
rst2 = model.predict_classes(tx2).reshape(len(tx2))
print("预测结果为:"+str(rst2))
9、Apriori算法实现:
支持度:A、B同时发生的概率。Support ===P(AB)
置信度:若A发生,B发生的概率。Confidence=== P(B/A)
1. 设定阈值:即最小支持度、最小置信度。
2. 计算置信度和支持度。
Support=(AB同时发生的数量)/事件总数量;
= support_Count(A and B)/total_Count(A)
Confidence(AàB) = p(B/A)=support(A andB)/support(A)
= support_count(A andB)/support(A)
#!/usr/bin/env python
# _*_ UTF-8 _*_
from __future__ import print_function
import pandas as pda
# 自定义连接函数,用于实现L_[k-1]到C_k的连接
def connect_string(x, ms):
# 对传进来的数据进行排序
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
# 剪枝叶的过程:
for i in range(len(x)):
for j in range(i, len(x)):
if x[i][:l-1]==x[j][:l-1] and x[i][l-1] != x[j][l-1]
r.append(x[i][:l-1]+sorted([x[j][l-1], x[i][l-1]]))
return r
# 寻找关联规则的函数:
def find_rule(d, support, confidence, ms=u'--'):
# 定义输出结果
result = pda.DataFrame(index=['support','confidence'])
# 支持度序列
support_series = 1.0 * d.sum()/len(d)
# 初步根据支持的筛选。
column = list(support_series[support_series>support].index)
k=0
while len(column)>1:
k=k+1
print(u'\n正在进行第 %s 次搜索' % k)
column = connect_string(column, ms)
print(u'数目:%s ...' % len(column))
# 新一批支持度计算
sf = lambda i:d[i].prod(axis=1, numeric_only=True)
# 创建连接数据,这一步耗时、耗内存严重,当数据量较大时,可以
# 考虑并行运算
d_2 = pda.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum()/len(d)
column = list(support_series_2[support_series_2>support].index)# 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
# 遍历可能的推理,如[A,B,C]究竟是A+B-->C还是B+C-->还是A+C-->B
for i in column:
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pda.Series(index=[ms.join(i) for i in column2])
for i in column2:
# 计算置信度序列:
cofidence_series[ms.join(i)]=support_series[ms.join(sorted(i))]/support_series
for i in cofidence_series[cofidence_series>confidence].index:
result[i] = 0.0
result[i]['confidence'] = confidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
# 结果整合
result = result.T.sort(['confidence','support'], ascending=False)
print(u'/n结果为:')
print(result)
return result比如:

十个学员课程购买的情况:
#!/usr/bin/env python
# _*_ UTF-8 _*_
from Apriori import *
import pandas as pda
filename = "F:/python_workspace/file/Apriori/lesson_buy.xls"
dataframe = pda.read_excel(filename, header=None)
# 转化一下数据:
change = lambda x:pda.Series(1, index=x[pda.notnull(x)])
map_Ok = map(change, dataframe.as_matrix())
# 将对应的数据转化为数组,并将nan转化为0
data = pda.DataFrame(list(map_Ok)).fillna(0)
print(data)
# 临界支持度
spt = 0.1
# 置信度设置
cfd = 0.3
# 使用apriori算法计算结果(数据,支持度, 置信度, 连接符)
find_rule(data, spt, cfd, "&&")10、微博数据情感分析:
----即词语是正面的还是负面的,使用聚类分析、结巴分词、文本相似度等。
爬虫的几种方式:
1.使用scrapy爬取;
2.使用接口去取。
此次重点将如何通过接口方式获取微博的数据:
在微博中使用开发模式:
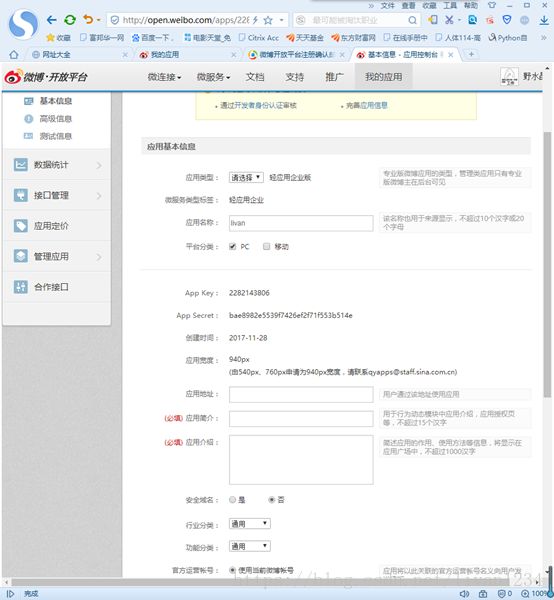

微博开发接口即可使用接口了。
微博接口开发上:
App Key:2282143806
App Secret:bae8982e5539f7426ef2f71f553b514e
然后阅读接口文档,寻找相应的接口信息。
#!/usr/bin/env python
# _*_ UTF-8 _*_
import weibo
import urllib
import urllib2
import re
import time
def weibo():
APP_KEY = "2282143806"
APP_SECRET = "bae8982e5539f7426ef2f71f553b514e"
CALLBACK_URL = "http://api.weibo.com/livan/default.html"
AUTH_URL = "http://api.weibo.com/livan/default.html"
USERID = "2577633693"
PASSWD = "xujingboyy123"
client =weibo.APIClient(app_key=APP_KEY,
app_secret=APP_SECRET,
redirect_uri=CALLBACK_URL)
referer_url =client.get_authorize_url()
print "refererurl is: %s" % refer_url
cookies =urllib2.HTTPCookieProcessor()
opener =urllib2.build_opener(cookies)
urllib2.install_opener(opener)
postdata = {
"client_id":APP_KEY,
"userId":USERID,
"passwd":PASSWD,
"isLoginSina":"0",
"action":"submit",
"response_type":"code",
}
headers = {
"User-Agent":"",
"Host":"api.weibo.com",
"Referer":referer_url
}
req = urllib2.Request(
url = AUTH_URL,
data = urllib.urlencode(postdata),
headers = headers
)
try:
resp = urllib2.urlopen(req)
print "callbackurl is: %s" % resp.geturl()
pat = "code=(.*?)$"
print(resp.geturl())
code = input()
print "code is :%s" % code
except Exception, e:
print e
r = client.request_access_token(code)
access_token1 = r.access_token
expires_in = r.expires_in
print "access_token=", access_token1
print "expires_in=", expires_in
client.set_access_token(access_token1, expires_in)
return client, access_token1
# 定义确定转发页面数量的函数:
def getPageNum(mid):
count = client.get.statuses__,count(ids = mid)
repostNum = count[0]['reposts']
if repostNum%200 ==0:
pages = repostNum/200
else:
pages = int(repostNum/200)+1
return pages
# 定义抓取转发的函数:
def getReposts(mid, page):
r =client.get.statuses__profile_list(access_token=mid, uid = , capital="A")
print("r:"+str(r))
if len(r) == 0:
pass
else:
m = int(len(r['reposts'])) # 该页面里的微博转发数量
try:
for i in range(0, m): # 使用for循环遍历该页面里的所有转发微博
#转发微博的属性
mid = r['reposts'][i].id
text = r['reposts'][i].text.replace(",","")
created = r['reposts'][i].created_at
reposts_count = r['reposts'][i].comments_count
# 微博转发者的属性
user = r['reposts'][i].user
user_id = user.id
user_name = user.name
user_province = user.province
user_city = user.city
user_gender = user.gender
user_url = user.url
user_followers =user.followers_count
user_friends =user.friends_count
user_statuses = user.statuses_count
user_created =user.created_at
user_verified = user.verfied
# 原微博的属性
rts = r['reposts'][i].retweeted_status
rts_mid = rts.id
rts_created = rts.created_at
rts_reposts_count =rts.reposts_count
rts_comments_count =rts.comments_count
# 原微博发出者的属性
rtsuser_id = rts.user.id
rtsuser_name = rts.user.name
rtsuser_province =rts.user.province
rtsuser_city = rts.user.city
rtsuser_gender =rts.user.gender
rtsuser_url = rts.user.url
rtsuser_followers =rts.user.followers_count
rtsuser_friends =rts.user.friends_count
rtsuser_statuses = rts.user.statuses_count
rtsuser_created =rts.user.created_at
rtsuser_verfied =rts.user.verfied
timePass = clock()-start
if round(timePass) % 2 == 0:
print mid, rts_mid, "I havebeen working for %s seconds" % round(timePass)
time.sleep(random.randrange(3, 9, 1))
print >>dataFile, "%s, '%s',%s" % (mid, created, text)
except Exception, e:
print >>sys.stderr, 'EncounteredException:', e, page
time.sleep(120)
pass
client, access_token1 = weiboClient() # 连接到API接口
# mid为微博的mid,即在转发——私信中确定的路径后几位。
mid = client.get.statuses__queryid(mid = 'EqXcf9AyW', isBase62 = 1, type = 1)['id']
mid = "EqXKmhj85"
# 定义存储文档地址
dataFile = open("F:/python_workspace/file/weibo/weibo_repost_all.csv", "wb")
pageNum = 10
for page in range(1, pageNum+1):
thisdata = getReposts(access_token1, page)
print(thisdata)
dataFile.close()

其中statuses/user_timeline为可调用函数:
调用时改成statuses__user_timeline()即可,对应的参数为:

上面为常用的几个案例,可以作为练习。