已完成部分:背包问题、排序、堆
引用leetcode上面的一张图,说明常见的面试内容:
下面分别介绍上面的算法。
输入输出
在编程题中,经常需要程序具有接收从终端输入字符数据的功能,下面分别以c、c++、python为例,演示如何接收用户输入。要求:用户从终端分别输入一个整数和一个小数,中间用一个或多个空格分隔,要求程序能够读入数据并打印出来。
- c语言版
// read.c
#include
int main(int argc, char* argv[]){
int a = 0;
float b = 0.0;
scanf("%d %f", &a, &b);
printf("a=%d, b=%f\n", a, b);
return 0;
}
如果想在输入的整数和小数之间用逗号隔开,可以将调用scanf函数的行改为:scanf("%d,%f", &a, &b); 允许在逗号前后存在任意多的空格、制表符、回车符。
- c++版
// read-1.cpp
#include
using std::cin;
using std::cout;
using std::endl;
int main(int argc, char* argv[]){
int a = 0;
float b = 0.0;
cin >> a >> b;
cout << a << ", " << b << endl;
return 0;
}
如果像前面一样,两个数之间用逗号隔开,可以通过读入一行,之后找到逗号所在位置并将其分割,最后分别转换成整数和小数,不过整个过程较为麻烦,建议使用c中的scanf函数。
- python版
# read.py
line = input()
s1, s2 = line.split()
a, b = int(s1), float(s2)
print("a=%d, b=%f" %(a,b))
如果两个数之间用逗号隔开,可以将字符串分割的语句改为 s1, s2 = line.split(',') 即可。
数据结构
程序 = 数据结构+算法。其中,数据结构是底层,算法是高层,因此我们先对数据结构的相关知识进行梳理。
字符串
字典树
后缀树
正则式的使用
数组
链表
单/双向链表
跳舞链
快慢指针
队列/栈
树/图
- 完全二叉树:若设二叉树的深度为h,除第h层所有的结点都连续集中在最左边,这就是完全二叉树。
最近公共祖先
并查集
堆
堆(Heap)是一种重要的数据结构,是实现优先队列(priority queue)首选的数据结构,其中最常见的是二叉堆。
小/大根堆
二叉堆具有如下的性质:
- 二叉堆是一棵完全二叉树;
- 二叉堆中某个节点的值总是不大于(或不小于)其孩子节点的值,称为小根堆(大根堆);
- 堆树中每个节点的子树都是堆树;

二叉堆通常用数组进行存储,根节点为索引等于1的元素,索引为i的元素,其父节点为索引等于⌊i / 2⌋的元素,其左子节点索引为 2×i,其右子节点索引为2×i+1,索引为0的元素可以用于保存节点的总个数。
对于堆而言,最主要的两个函数为push 和 pop,下面我们用c++实现一个大根堆并使用该堆:
#include
#include
#include
using namespace std;
class MaxHeap{
private:
vector a;
public:
MaxHeap(){
a.push_back(0);
}
MaxHeap(const vector& raw):a(raw){
a.insert(a.begin(), a.size());
heapify(a);
}
void heapify(vector& raw){
for(int i = (raw.size()-1)/2; i>0; --i)
siftdown(raw, i);
}
void siftup(vector& raw, int index){
while(index > 1){
int parent = index / 2;
if(raw[parent](raw[parent], raw[index]);
index /= 2;
}else
break;
}
}
void push(int v){
a[0] += 1;
a.push_back(v);
siftup(a, a.size()-1);
}
void siftdown(vector& raw, int index){
while(index*2a[selected_son])
selected_son = right_son;
if(a[selected_son]<=a[index]) break;
swap(a[selected_son], a[index]);
index = selected_son;
}
}
int pop(){
if(a.size()==1) return INT_MIN;
a[0] -= 1;
int ret = a[1];
a[1] = a.back();
a.pop_back();
siftdown(a, 1);
return ret;
}
size_t size(){
return a.size()-1;
}
};
int main(int argc, char* argv[]){
MaxHeap heap;
heap.push(2); heap.push(7); heap.push(26); heap.push(25);
heap.push(19); heap.push(17); heap.push(1); heap.push(90);
heap.push(3); heap.push(36);
//vector a{2, 7, 26, 25, 19, 17, 1, 90, 3, 36};
//MaxHeap heap(a);
while(heap.size())
cout << heap.pop() << " ";
cout << endl;
return 0;
}
下面的动图来自于: https://blog.csdn.net/qq_35109096/article/details/81513577
上述的push 和 pop 的动图为:


下面是 heapify 的过程,heapify 是指将一个数组变为符合heap要求的数组,动图来自 songwell2014 :
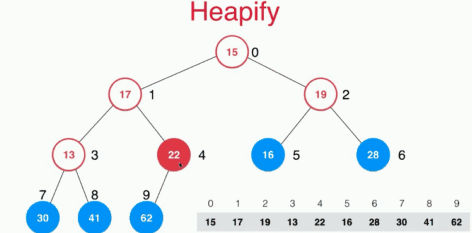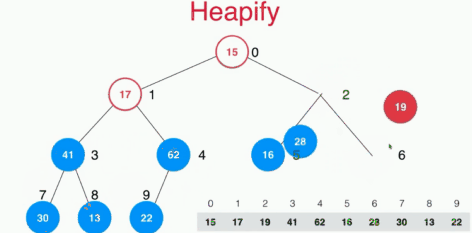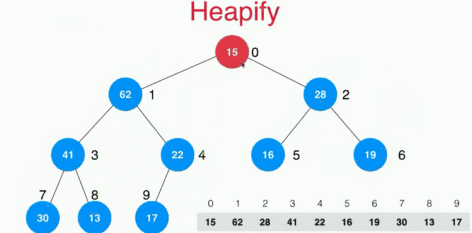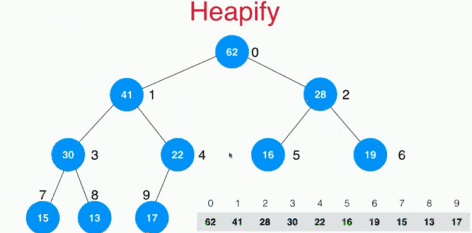
注意:上面的动图是自底向上的建堆规程,其时间复杂度为 O(n),分析过程见:https://www.zhihu.com/question/264693363/answer/291397356。
可并堆
可并堆是合并效率较高的堆。如果是二叉堆,那么在合并堆时最朴素的想法是将size小的堆中元素插入到size大的堆中,其时间复杂度为 O(n logn)。
可并堆(mergeable heap)是一类支持可合并的堆(即合并的时间复杂度较低,小于O(n) 的堆),包括左偏树、斜堆、二项堆、配对堆、斐波那契数列堆。
常用的可并堆为左偏树,相关介绍见:https://www.luogu.org/blog/cytus/ke-bing-dui-zhi-zuo-pian-shu。
编程库中的堆
c语言中没有提供堆的结构或函数。在c++中的algorithm库中提供和堆相关的操作,包括make_heap/pop_heap/push_heap,使用的demo如下:
#include
#include
#include
using namespace std;
int main(int argc, char* argv[]){
vector heap{5, 8, 0};
// auto comp = less();
auto comp = greater();
make_heap(heap.begin(), heap.end(), comp);
heap.push_back(19); push_heap(heap.begin(), heap.end(), comp);
heap.push_back(3); push_heap(heap.begin(), heap.end(), comp);
heap.push_back(17); push_heap(heap.begin(), heap.end(), comp);
heap.push_back(1); push_heap(heap.begin(), heap.end(), comp);
while(heap.size()){
pop_heap(heap.begin(), heap.end(), comp);
cout << heap.back() << " ";
heap.pop_back();
}
cout << endl;
}
用python实现相同功能的代码为:
import heapq
a = [5, 8, 0]
heapq.heapify(a)
heapq.heappush(a, 19)
heapq.heappush(a, 3)
heapq.heappush(a, 17)
heapq.heappush(a, 1)
while len(a):
print(heapq.heappop(a), end=" ")
print()
哈希表
算法
排序算法
如果试题考察的重点不是排序算法,我们可以直接调用库中的排序算法,下面分别演示c、c++和python中排序算法的调用。
- c
#include
// qsort/ heapsort/ mergesort 都在stdlib库中
#include
int cmp(const void* p1, const void* p2){
return *(int*)p1-*(int*)p2; //按从小到大排序
// return *(int*)p2-*(int*)p1; //按从大到小排序
}
int main(){
int a[] = {2,5,1,7,8,4,2,1};
int n = sizeof(a)/sizeof(*a);
qsort(a, n, sizeof(*a), cmp); //使用快速排序
//heapsort(a, n, sizeof(*a), cmp); //使用堆排序
//mergesort(a, n, sizeof(*a), cmp); //使用归并排序
for(int i=0; i - c++
#include
#include
// sort/greater/less函数都在该库中
#include
using namespace std;
int main(int argc, char* argv[]){
vector a{2,5,1,7,8,4,2,1};
sort(a.begin(), a.end());
//sort(a.begin(), a.end(), greater()); //递减排序
for(int i=0; i - python
a = [2,5,1,7,8,4,2,1]
a.sort() # 递减排序: a.sort(reverse=True)
print(a)
分析一个排序算法时,需要考察一下几个性质:
- 时间复杂度
- 空间复杂度
- 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,则称排序算法是稳定的
在排序过程中不另外申请内存空间的排序也称为原地排序。
| 排序算法 | best T | worst T | avg T | Memory | stability |
|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 快速排序 | O(n logn) | O(n^2) | O(n logn) | O(1) | 不稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n) | O(n^s) | O(n logn) | O(1) | 不稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(n logn) | O(n logn) | O(n logn) | O(1) | 不稳定 |
| 归并排序 | O(n logn) | O(n logn) | O(n logn) | O(n logn) | 稳定 |
| 基数排序 | O(kn) | O(kn) | O(kn) | O(n) | 稳定 |
| 计数排序 | O(n) | O(n) | O(n) | O(span+n) | -- |
算法的动图主要来自于维基百科。
冒泡排序

// bubbleSort.cpp
#include
#include
using std::vector;
void bubbleSort(vector& a){
for(int i=a.size()-1; i>0; --i){
bool ok = true;
for(int j=0; ja[j+1]){ // 编程时一定要注意判断条件
swap(a[j], a[j+1]);
ok = false;
}
}
if(ok) break;
}
}
快速排序

void quickSort(int a[], int left, int right){
if(left>=right) return;
int tleft=left, tright=right;
int v = a[left];
while(tleft=a[tleft]) ++tleft; // 注意点同上
if(tleft 插入排序

如果带排序的数组较为有序,那么直接插入排序的效率会非常高。
#include
using namespace std;
void insertSort(vector& a){
for(int i=1; i=0 && v 希尔排序

希尔排序相当于对插入排序的升级,先以大的跨度将待排序数组变得较为有序,最后使用直接排序。在c++中随机产生一个包含100000个元素的数组,以直接插入的方式进行排序,用时约为 12000ms,用希尔排序算法用时约为 42ms。
#include
#include
using namespace std;
// gap为1,即为一次直接插入排序
void insertSort(vector&a, int gap=1){
for(int i=gap; i=0 && a[j]>v; j-=gap){
a[j+gap] = a[j];
}
a[j+gap] = v;
}
}
void shellSort(vector& a){
for(int i=a.size()/2; i>0; i/=2)
insertSort(a, i);
}
选择排序

#include
using namespace std;
void selectSort(vector& a){
for(int i=a.size()-1; i>0; --i){
int max_index = 0;
for(int j=1; j<=i; ++j){
if(a[max_index] <= a[j])
max_index = j;
}
int t = a[max_index];
a[max_index] = a[i];
a[i] = t;
}
}
虽然大多数人都说选择排序是不稳定的算法,不过觉得还是可以保证相同值相对前后顺序不变,也就是说可以为稳定的排序算法。
堆排序
堆排序是利用堆这种数据结构进行排序的算法。首先,将数组变成符合要求的堆,然后不断从堆中弹出元素,使整个数组变得有序。其中,建立堆的时间复杂度为 O(n),每次弹出一个元素的时间复杂度为 O(logn),因此,整个过程的时间复杂度为 O(n+n logn)=O(n logn)。

#include
#include
#include
using namespace std;
template
void heapSort(RandomAccess& a, Compare cmp){
make_heap(a.begin(), a.end(), cmp);
for(int i=0; i a{3,1,6,7,8,13,1,2};
//heapSort(a, greater()); // 降序排序
heapSort(a, less()); // 升序排序
for(auto v : a)
cout << v << " ";
cout << endl;
}
归并排序

#include
#include
using namespace std;
void mergeSort(vector& a, int left, int right){
if(left>=right) return;
int mid = (left+right)/2;
mergeSort(a, left, mid);
mergeSort(a, mid+1, right);
vector ta(a.begin()+left, a.begin()+right+1);
int p=left, p1=0, p2=mid+1-left;
while(p1 a{2,1,5,3,6,7,12,2,6};
mergeSort(a, 0, a.size()-1);
for(auto v : a) cout << v << " ";
cout << endl;
}
基数排序
基数排序(radix sort) 是一种非比较型整数排序算法,其原理是将整数按数位切分成不同的数字,然后按每个位数进行比较。它是这样实现的:将所有待比较数值(正整数)统一为同样的数字长度,数字较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序的python代码为:
import math
def radixSort(a, radix=10):# a是一个整数数组
# k为最大的位数
k = math.ceil(math.log(max(a)+1, radix))
for i in range(k):
b = [[] for j in range(radix)]
for v in a:
b[(v//radix**i)%(radix**i)].append(v)
del a[:]
for e in b:
a.extend(e)
return a
print(radixSort([3,12,421,22,41,52]))
计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
#include
#include
#include
using namespace std;
void countingSort(vector& a, int minv, int maxv){
vector buf(maxv-minv+1, 0);
for(auto v: a)
buf[v-minv] += 1;
a.clear();
for(int i=0; i a{2,5,6,2,3,7,4,3,7,6};
countingSort(a, *min_element(a.begin(),a.end()),
*max_element(a.begin(),a.end()));
for(auto v: a) cout << v << " ";
cout << endl;
}
搜索算法
回溯
递归
剪枝
图论
最短路径
最小生成树
网络流建模
动态规划
背包问题
关于背包问题,推荐看《背包问题九讲》 这里只对其中的部分内容进行讲解。
- 0-1 背包问题
0-1背包问题最基本的背包问题,该问题的描述为:有N件物品和一个容量为V的背包,放入第i件物品耗费的空间为,得到的价值为,求解将哪些物品装入背包能使价值总和最大。
如果用暴力枚举法进行问题的求解,N件物品每一件都有选中和不选中两种状态,故共有种情况,求解的时间复杂度为 ,这种时间复杂度明显是不可容忍的。
假设将前 i-1 个物品放入容量为 v 的背包得到的最大价值为 pack(i-1, v),对于第 i 个物品而言,如果不选中,则最大的价值等于 pack(i-1, v); 如果选中,则最大的价值等于 pack(i-1, v-Ci)+Wi,因此将前 i 个物品放入容量为v的背包得到的最大价值为 max{ pack(i-1, v), pack(i-1, v-Ci)+Wi }。该函数即为状态转移函数。我们定义一个长度为 (N+1)×(V+1) 的二维整数数组a,其中元素 a[i][j] 存放 pack(i, j) 的值,上述0-1背包问题的伪代码为:
a[0..N+1, 0..V+1] <- 0
for i <- 1 to N
for v <- Ci to V
a[i, v] <- max{F[i-1, v], F[i-1, v-Ci]+Wi}
ret_value = a[N, V]
上述算法的时间复杂度和空间复杂度都为 O(NM),其实可以将空间复杂度将为 O(M),伪代码如下:
a[0..V+1] <- 0
for i <- 1 to N
for v <- V to Ci
a[v] <- max{F[v], F[v-Ci]+Wi}
ret_value = a[V]
下面用一个例子来实践上述问题:华为应用商城举办下应用得积分的活动,月末你还有40兆流量未使用,现在有4个应用可以下载,每个应用需要的流量分别为 12, 13, 23, 36,下载每个应用获得的积分为 10, 11, 20, 30,求用户可以获得的最大积分数为多少?
V = 40
C = [12, 13, 23, 36]
W = [10, 11, 20, 30]
a = [0]*(V+1)
for i in range(len(C)):
for j in range(V, C[i]-1, -1):
a[j] = max(a[j], a[j-C[i]]+W[i])
print("ret_value = %d" %(a[V]))
结果为31。
如果需要具体指出需要取出的物品号,那么只能保持空间复杂度为 O(MN):
V = 40
C = [12, 13, 23, 36]
W = [10, 11, 20, 30]
N = len(C)
a = [[0]*(V+1) for _ in range(N+1)]
for i in range(len(C)):
for j in range(C[i], V+1):
a[i+1][j] = max(a[i][j], a[i][j-C[i]]+W[i])
print("ret_value = %d" %(a[N][V]))
print("Select apps:", end="")
pv = V
for i in range(N, 0, -1):
if a[i][pv]!=a[i-1][pv]:
print(i, end=" ")
pv -= C[i-1]
求最优解的背包问题题目中,事实上有两种不太相同的问法。有的题目要求“恰好装满背包”时的最优解,有的题目则并没有必须把背包装满,一种区别这两种问法的实现方法是在初始化的时候有所区别。第一种问法,要求恰好装满背包,那么在初始化时除了F[0]为0,其他F[1..V+1]均设为-∞;第二种问法,将 F[0..V+1]都设为0。
- 完全背包问题
有N种物品和一个容量为V的背包,每种物品都有无限件可能,放入第 i 种物品的费用是 Ci,价值是Wi。求解:将哪些物品装入背包,可以使这些物品的费用总和不超过背包的容量,且价值总和最大。
完全背包问题的转移函数有两个:
其中转移函数2的代码更加简洁,时间复杂度也更低,为O(MN),伪代码为:
F[0..V+1] <- 0
for i <- 1..N
for v <- Ci..V
F[v] = max(F[v], F[v-Ci]+Wi)
与0-1背包问题唯一不同的地方是第三行v的取值顺序。
- 多重背包问题
有N种物品和一个容量为V的背包。第i种物品最多有Mi件可用,每件耗费的空间为 Ci,价值为Wi,求解将哪些物品装入背包可以使这些物品耗费的空间总和不超过背包容量,且价值总和最大。可以将N种物品进行扩展,第i种物品的Mi件分别看成不同种物品,因此扩展后一共有 种物品,其中一些物品具有相同的Ci和Wi,因此将多重背包问题变为了0-1背包问题。多重背包问题的转移函数可以写成:
- 二维背包问题
对于每件物品,具有两种不同的费用,选择这件物品必须同时付出这两种费用。对于每种费用都有一个可付出的最大值(背包容量)。问怎样选择物品可以得到最大的价值。
设第 i 件物品所需的两种费用分别为 Ci 和 Di。两种费用可付出的最大值(也即两种背包容量)分别为 V 和 U。物品的价值为 Wi。其转移函数可以写成: ,其伪代码为:
a[0..V+1, 0..U+1] <- 0
for i <- 1 to N
for v <- V to Ci
for u <- U to Di
a[v, u] <- max{F[v, u], F[v-Ci, u-Di]+Wi}
ret_value = a[V, U]
二维背包问题的一个例子:https://leetcode.com/problems/ones-and-zeroes/
假定我们有m个0和n个1,另外有一组字符串,其中的每个字符串都由0和1组成,问最多能够组成多少个字符串,例如:m=5, n=3, array={"01", "0001", "111001", "1", "0"},我们可以组成4个字符串,分别为“0”、“1”、“01”,“0001”。
def findMaxForm(V, U, strs):
N = len(strs)
bags = [[0]*(U+1) for i in range(V+1)]
for s in strs:
zeros = s.count('0')
ones = s.count('1')
for v in range(V, zeros-1, -1):
for u in range(U, ones-1, -1):
bags[v][u] = max(bags[v][u], bags[v-zeros][u-ones]+1)
return bags[V][U]
m, n = 5, 3
array = ["01", "0001", "111001", "1", "0"]
print(findMaxForm(m, n, array))
- 总结
0-1背包问题的基本思路:
a[0..V+1] = 0 // 改为 a[0..V+1]=-∞即变为恰好装满背包的0-1背包问题
for i <- 1 to V
// 内层循环的层数控制背包问题的维数
for v <- V..Ci // 改为 for v <- Ci..V 即变为完全背包问题
a[v] = max(a[v], a[v-Ci]+Wi)
result = a[V]