Text-Guided Attention Model for Image Captioning
In our approach, we leverage a guidance captions as associated text language to steer visual attention. Our image captioning network is trained to minimize the following loss:

1.给定一张图片,从训练集中选择一张相似的图片和一条描述
2.相似的图片和描述are transformed to separate multi-dimensional feature vectors, 用来计算attention map
3.In the attention map, the regions relevant to the guidance caption are highlighted while irrelevant regions are suppressed. The decoder generates an output caption based on a weighted sum of the image feature vectors, where the weights are determined by the attention map.
Ground-truth caption是理想的guidance caption,但是测试的时候没法用,因此采用采样的方法获取guidance caption。相似的图片有共同的显著区域和描述。
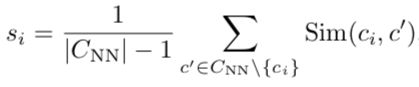
计算 当前描述 和 其他所有描述的相似性 。用CIDEr做相似性函数。
Encoder:
通过VGG得到image features
![]()
通过Skip-thought得到描述的vector
![]()
通过在大型语料库上预测超过74M个句子的周围两个句子,在无监督学习技术中训练该句子嵌入模型,模型是有GRU组成的。通过最后一个GRU的隐藏层得到vector
在训练期间固定两个encoder的参数
用
![]()
表示第i个位置的区域特征,为每个区域特征计算权重(soft attention)

三个W分别是image feature, guidance caption feature, and their weighted sum的参数
然后计算context vector

在损失函数后面加上三个权重的正则,惩罚过度关注某个区域的权重,促使注意力均匀。
Decoder:

计算h-1的时候不用h-2,用全0和z
The word embedding and prediction layers share their weights to reduce the number of parameters.
训练和测试:
训练时从得分最高的描述TOPN中随机选一个作为guidance caption,不选分数最高的,因为过拟合。
测试时使用k个候选guidance captions生成k个句子,然后对k个句子重新排序(与最近邻图像TOPN=60的CIDEr similarity)。k=10
beam search=2
实验细节:
1. VGGNet (VGG-FCN), which is fine-tuned on the MS-COCO dataset to predict image attributes,image feature maps are obtained from the last con- volutional layer. 10*10
也用了ResNet,得到14*14
2. we fix the parameters of two encoders, but train the text-guided attention model and the decoder from scratch
3. the dimensionalities of the word embedding space and the hidden state of LSTM are set to 512
mini-batch size of 80
dropouts with 0.5 are applied to the output layer of decoder
The learning rate starts from 0.0004 and after 10 epochs de- cays by the factor of 0.8 at every three epoch
4. 训练时如果每一步都从guidance caption中取词,测试时难以生成可靠的句子
每一步从guidance caption中随机取词