mongodb 的集群方式主要分为三种Replica Set / Sharding / Master-Slaver ,这里只说明最简单的集群搭建方式(生产环境),如果有多个节点可以此类推或者查看官方文档。
Replica Set
中文翻译叫做副本集。其实简单来说就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致。如下图:
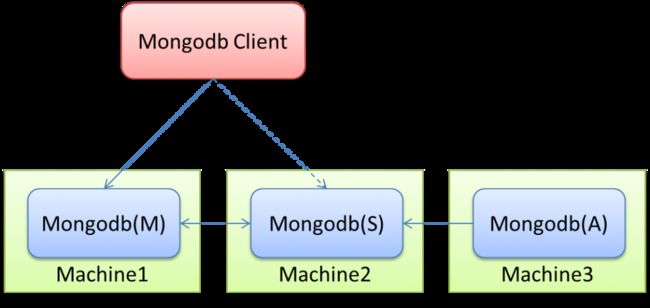
Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据(M,S),仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
介绍完了集群方案,那么现在就开始搭建了。
1、将三台计算机同时下载,解压安装文件
下载命令:apt-get install mongo
2、同时创建mongodb数据文件夹
1 mkdir -p /mongodb/data/master 2 mkdir -p /mongodb/data/slaver 3 mkdir -p /mongodb/data/arbiter 4 #三个目录分别对应主,备,仲裁节点
3、建立配置文件(M,S,A)
(一) 主节点配置文件
1 #master.conf 2 dbpath=/mongodb/data/master 3 logpath=/mongodb/log/master.log 4 pidfilepath=/mongodb/master.pid 5 directoryperdb=true 6 logappend=true 7 replSet=testrs 8 bind_ip=10.10.148.130 9 port=27017 10 oplogSize=10000 11 fork=true 12 noprealloc=true
(二) 从节点配置文件
1 #slaver.conf 2 dbpath=/mongodb/data/slaver 3 logpath=/mongodb/log/slaver.log 4 pidfilepath=/mongodb/slaver.pid 5 directoryperdb=true 6 logappend=true 7 replSet=testrs 8 bind_ip=10.10.148.131 9 port=27017 10 oplogSize=10000 11 fork=true 12 noprealloc=true
(三) 仲裁节点配置文件
1 #arbiter.conf 2 dbpath=/mongodb/data/arbiter 3 logpath=/mongodb/log/arbiter.log 4 pidfilepath=/mongodb/arbiter.pid 5 directoryperdb=true 6 logappend=true 7 replSet=testrs 8 bind_ip=10.10.148.132 9 port=27017 10 oplogSize=10000 11 fork=true 12 noprealloc=true
*配置文件中参数解释:
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,方便停止mongodb
directoryperdb:为每一个数据库按照数据库名建立文件夹存放
logappend:以追加的方式记录日志
replSet:replica set的名字
bind_ip:mongodb所绑定的ip地址
port:mongodb进程所使用的端口号,默认为27017
oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5%
fork:以后台方式运行进程
noprealloc:不预先分配存储
4、相继启动mongod 或者安装mongo服务
进入每个mongodb节点的bin目录下(配置文件路径有更改请自行更改下面命令)
./monood -f master.conf ./mongod -f slaver.conf ./mongod -f arbiter.conf
5、配置主,备,仲裁节点
可以通过客户端连接mongodb,也可以直接在三个节点中选择一个连接mongodb。
./mongo 10.10.148.130:27017 #ip和port是某个节点的地址 >use admin >cfg={ _id:"testrs", members:[ {_id:0,host:'10.10.148.130:27017',priority:2}, {_id:1,host:'10.10.148.131:27017',priority:1}, {_id:2,host:'10.10.148.132:27017',arbiterOnly:true}] }; >rs.initiate(cfg)
cfg是可以任意的名字,当然最好不要是mongodb的关键字,conf,config都可以。最外层的_id表示replica set的名字,members里包含的是所有节点的地址以及优先级。优先级最高的即成为主节点,即这里的10.10.148.130:27017。特别注意的是,对于仲裁节点,需要有个特别的配置——arbiterOnly:true。这个千万不能少了,不然主备模式就不能生效。
6、测试配置是否成功
配置的生效时间根据不同的机器配置会有长有短,配置不错的话基本上十几秒内就能生效,有的配置需要一两分钟。如果生效了,执行rs.status()命令会看到如下信息:
{ "set" : "testrs", "date" : ISODate("2013-01-05T02:44:43Z"), "myState" : 1, "members" : [ { "_id" : 0, "name" : "10.10.148.130:27017", "health" : 1, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 200, "optime" : Timestamp(1357285565000, 1), "optimeDate" : ISODate("2013-01-04T07:46:05Z"), "self" : true }, { "_id" : 1, "name" : "10.10.148.131:27017", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 200, "optime" : Timestamp(1357285565000, 1), "optimeDate" : ISODate("2013-01-04T07:46:05Z"), "lastHeartbeat" : ISODate("2013-01-05T02:44:42Z"), "pingMs" : 0 }, { "_id" : 2, "name" : "10.10.148.132:27017", "health" : 1, "state" : 7, "stateStr" : "ARBITER", "uptime" : 200, "lastHeartbeat" : ISODate("2013-01-05T02:44:42Z"), "pingMs" : 0 } ], "ok" : 1 }
正在进行配置提示:"stateStr" : "RECOVERING"
后话:
Replica Set 是我现在主要使用的集群方式,也是我使用过最稳定和高效的无规则大数据存储方式。这样的配置要求运行环境需要至少三台windows/ubuntu,当然我们可以使用VM来进行虚拟化测试,在项目实施的过程中还是建议多台服务器进行配置,如果有能力当然可以上虚拟+存储。至于大数据的数据检索部分,千万级别以下的使用mongodb的索引完全能解决,过亿建议使用检索平台,最近个人在研究 elasticseach 大数据检索平台,如果有兴趣的可以一起学习了解~ 以上是mongodb Replica Set 的配置过程。 小的敬上!
以上为转自 https://www.cnblogs.com/callmecool/p/4662876.html
二:另外还有两种部署方式如下
Sharding
和Replica Set类似,都需要一个仲裁节点,但是Sharding还需要配置节点和路由节点。就三种集群搭建方式来说,这种是最复杂的。部署图如下:
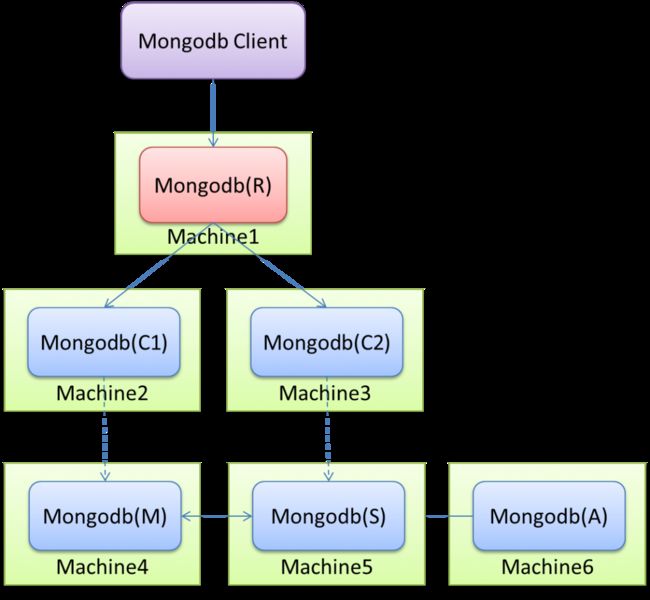
1.启动数据节点
- ./mongod --fork --dbpath ../data/set1/ --logpath ../log/set1.log --replSet test #192.168.4.43
- ./mongod --fork --dbpath ../data/set2/ --logpath ../log/set2.log --replSet test #192.168.4.44
- ./mongod --fork --dbpath ../data/set3/ --logpath ../log/set3.log --replSet test #192.168.4.45 决策 不存储数据
2.启动配置节点
- ./mongod --configsvr --dbpath ../config/set1/ --port 20001 --fork --logpath ../log/conf1.log #192.168.4.30
- ./mongod --configsvr --dbpath ../config/set2/ --port 20002 --fork --logpath ../log/conf2.log #192.168.4.31
3.启动路由节点
- ./mongos --configdb 192.168.4.30:20001,192.168.4.31:20002 --port 27017 --fork --logpath ../log/root.log #192.168.4.29
4.配置Replica Set
这里可能会有点奇怪为什么Sharding会需要配置Replica Set。其实想想也能明白,多个节点的数据肯定是相关联的,如果不配一个Replica Set,怎么标识是同一个集群的呢。这也是人家mongodb的规定,咱们还是遵守吧。配置方式和之前所说的一样,定一个cfg,然后初始化配置。
- ./mongo 192.168.4.43:27017 #ip和port是某个节点的地址
- >use admin
- >cfg={ _id:"testrs", members:[ {_id:0,host:'192.168.4.43:27017',priority:2}, {_id:1,host:'192.168.4.44:27017',priority:1},
- {_id:2,host:'192.168.4.45:27017',arbiterOnly:true}] };
- >rs.initiate(cfg) #使配置生效
5.配置Sharding
- ./mongo 192.168.4.29:27017 #这里必须连接路由节点
- >sh.addShard("test/192.168.4.43:27017") #test表示replica set的名字 当把主节点添加到shard以后,会自动找到set里的主,备,决策节点
- >db.runCommand({enableSharding:"diameter_test"}) #diameter_test is database name
- >db.runCommand( { shardCollection: "diameter_test.dcca_dccr_test",key:{"__avpSessionId":1}})
到这里Sharding也已经搭建完成了,以上只是最简单的搭建方式,其中某些配置仍然使用的是默认配置。如果设置不当,会导致效率异常低下,所以建议大家多看看官方文档再进行默认配置的修改。
Master-Slaver
这个是最简答的集群搭建,不过准确说也不能算是集群,只能说是主备。并且官方已经不推荐这种方式,所以在这里只是简单的介绍下吧,搭建方式也相对简单。
- ./mongod --master --dbpath /data/masterdb/ #主节点
- ./mongod --slave --source
以上三种集群搭建方式首选Replica Set,只有真的是大数据,Sharding才能显现威力,毕竟备节点同步数据是需要时间的。Sharding可以将多片数据集中到路由节点上进行一些对比,然后将数据返回给客户端,但是效率还是比较低的说。
我自己有测试过,不过具体的机器配置已经不记得了。Replica Set的ips在数据达到1400w条时基本能达到1000左右,而Sharding在300w时已经下降到500ips了,两者的单位数据大小大概是10kb。大家在应用的时候还是多多做下性能测试,毕竟不像Redis有benchmark。
Mongodb现在用的还是比较多的,但是个人觉得配置太多了。。。。我看官网都看了好多天,才把集群搭建的配置和注意要点弄明白。而且用过的人应该知道mongodb吃内存的问题,解决办法只能通过ulimit来控制内存使用量,但是如果控制不好的话,mongodb会挂掉。。。