关于Kafka 的消息日志Offset 的了解
之前在做Kafka 整合Storm的时候,因为对Kafka 不是很熟,考虑过这样的一个场景问题,针对一个Topic,Kafka消息日志中有个offset信息来标注消息的位置,Storm每次从kafka 消费数据,都是通过zookeeper存储的数据offset,来判断需要获取消息在消息日志里的起始位置。
那么我们想,这个Offset 是消息在日志里是一个什么样的位置,是绝对位置还是相对位置?而Kafla 有个参数log.retention.hours会根据设定的小时,来清理日志文件。这样就可能会有这样的一个问题,针对一个Topic,Kafka 生产数据后,消费者消费信息后,此时的消息的offset是一个高位,比如100,消费者在消费完会记录这个offset准备下个数据的获取。而当系统时间达到参数log.retention.hours设定的时间后,kafka会自动删除这个Topic的缓存日志,那么这个时候新加入10条消息,消息的offset 是重新开始还是从删除日志前的Offset 开始?如果是前者,这个时候消费者因为记录消费这个Topic信息的Offset 仍在高位,那么他就获取不到在这个Offset前的新加入数据,这样就比较麻烦了。而后者,offset又是怎么记录消息相对位置的从而消费者一直消费到数据,无论系统怎么处理日志。这个是Storm 消费Kafla数据的时候必须要确认的问题。
所以做了一个针对性测试。
将log.retention.hours设置为1个小时,然后重启kafka,创建一个测试Topic,然后往这个Topic里生产点数据,然后消费者那边也有输出,保证程序通顺正常。观察参数log.dirs=/tmp/kafka-logs目录下对应的话题目录。
下图是Topic下面的消息日志。

然后等一个小时后,继续观察日志
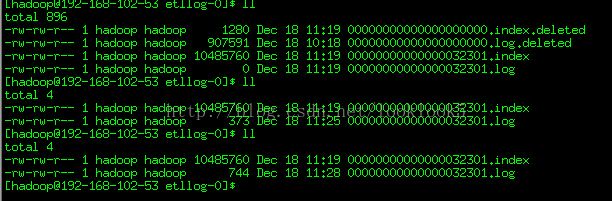
我们发现之前的消息日志被打上deleted 标志,然后并生成了新的日志。且日志名称改变了。
这个时候我们再生产数据会发现Kafka消费者还是能够正常输出数据的。那么之前假设offset是消息日志的绝对位置是不成立的。
官网5.5 Log的介绍,http://kafka.apache.org/documentation.html#introduction这里有对kafka的消息日志有详细的说明,其中也说到Offset的内容。
如果英语阅读困难,可以看这篇文章http://my.oschina.net/frankwu/blog/305010
下面是我是摘录的。
日志
如果一个topic的名称为"my_topic",它有2个partitions,那么日志将会保存在my_topic_0和my_topic_1两个目录中;日志文件中保存了一序列"log entries"(日志条目),每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置..每个partition在物理存储层面,有多个log file组成(称为segment).segment file的命名为"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始消息的offset.
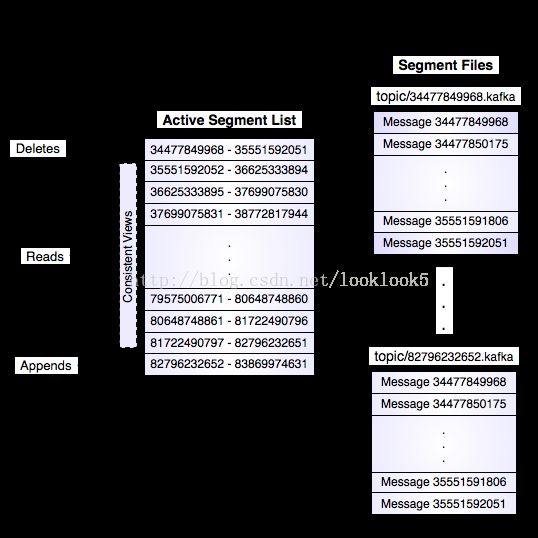
其中每个partiton中所持有的segments列表信息会存储在zookeeper中.
当segment文件尺寸达到一定阀值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果"距离最近一次flush的时间差"达到阀值时,也会触发flush到日志文件.如果broker失效,极有可能会丢失那些尚未flush到文件的消息.因为server意外失败,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启动时需要检测最后一个segment的文件结构是否合法并进行必要的修复.
获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数).根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可.
日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间).为了避免删除文件时仍然有read操作(consumer消费),采取copy-on-write方式.
从文章中可以看出,消息日志名是最小offset位置,消息所在位置加上文件名的offset就是消息的offset位置,而系统没生成一个新的日志后会就将最后的offset作为新日志文件的文件名。我们可以认为kafka 消息日志里的offset实际就相当于是一个增量序列索引。那样我们就不用纠结消费数据的时候会不会丢失,而可以安心关注Storm的业务问题了。