mpi学习日志(5):mpi4py与多点通信续
在多点通信里我们已经学习了广播bcast,散播scatter,收集gather,规约reduce.
今天我们再来简略看一些可能更为少用的多点通信.
1.allgather
简单来说就是收集+广播.
gather中只有根进程会得到收集到的信息,而allgather则是所有进程都会得到收集到的信息,就相当于收集后再广播一次.


2.allreduce
reduce与allreduce的关系,和gather与allreduce类似.
也就是说,allreduce就是reduce之后得到的值会再广播一次,即allreduce=reduce+bcast.


(PS:10=0+1+2+3+4)
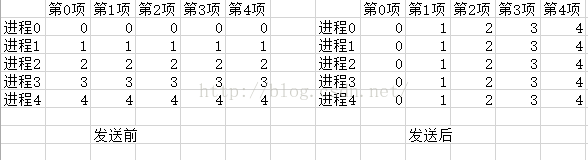
3.alltoall
alltoall实现的是转置的功能.
每个进程调用alltoall,都会把一个列表传递出去,然后也是得到一个列表.并且这两个列表的长度都必须等于总进程数.
具体操作的时候,alltoall会把第i个进程提供的列表的第j项,放到第j个进程返回的列表的第i项.
也就是相当于在一个n*n的矩阵A里,实现了swap(Aij,Aji).这就是矩阵的转置嘛.


4.scan
scan的操作和allreduce类似,但又更复杂
scan会把前i个收集的数据reduce成一个数据,返回发送给第i个进程.
下面的代码第i个进程会得到0+1+2+3+....的前i项和.


5.barrier
barrier是一种全局同步,就是说全部进程进行同步.
当一个进程调用barrier的时候,它会被阻塞.
当所有进程都调用了barrier之后,barrier会同时解除所有进程的阻塞.
相当于原本在跑道上跑得参差不齐的运动员,跑到起跑线上停下来等.当所有运动员都在起跑线上,他们才一起重新跑起来.
这就是所谓的全部进程进行同步.


说是这么说,但运行起来发现并不是这回事.所有进程没有像期待那样先全部输出begin,再全部输出end,barrier这个函数仿佛形同虚设.
其实这里问题不是在barrier,而是在print.
我们OS的IO是有缓冲的,一个数据要出现在屏幕上,简单来说是经过内存->标准IO文件->控制台屏幕.
而进程间不共享IO文件(后面会学到如何在MPI的进程里共享文件),共享控制台屏幕.
因此屏幕上语句的顺序依赖OS什么时候将IO文件里的内容推到屏幕上.
我们强制让内存->标准IO文件和标准IO文件->控制台屏幕这两步一起进行,也就是加上flush语句.
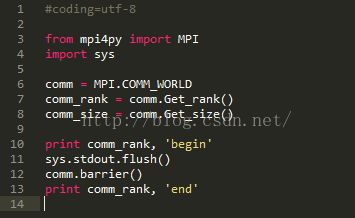

果然,输出结果和我们的期待吻合了.