librdkafka的安装和使用
安装:
下载https://github.com/edenhill/librdkafka
预备环境:
The GNU toolchain
GNU make
pthreads
zlib (optional, for gzip compression support)
libssl-dev (optional, for SSL and SASL SCRAM support)
libsasl2-dev (optional, for SASL GSSAPI support)编译和安装:
./configure
make
sudo make installserver端开启
下载:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.2.0/kafka_2.11-0.10.2.0.tgz注意版本的选择,本文选择的是release版本。
http://kafka.apache.org/quickstart 中描述的是release版本。
开启ZooKeeper server :
bin/zookeeper-server-start.sh config/zookeeper.properties &
查看端口2181的使用:

说明此时的zookeeper已经启动。
开启Kafka server:
bin/kafka-server-start.sh config/server.properties &
从配置文件我们可以知道该服务占用的端口号是9092:

下面的使用当然可以用bin目录下的各个脚本,但是本文主要是介绍以lib的方式进行操作。
用法介绍:
Producer的使用方法:
创建kafka客户端配置占位符:
conf = rd_kafka_conf_new();即创建一个配置对象(rd_kafka_conf_t)。并通过rd_kafka_conf_set进行brokers的配置。
设置信息的回调:
用以反馈信息发送的成败。通过rd_kafka_conf_set_dr_msg_cb(conf, dr_msg_cb);实现。
创建producer实例:
1)初始化:
应用程序需要初始化一个顶层对象(rd_kafka_t)的基础容器,用于全局配置和共享状态。
通过调用rd_kafka_new()创建。创建之后,该实例就占有了conf对象,所以conf对象们在rd_kafka_new()调用之后是不能被再次使用的,而且在rd_kafka_new()调用之后也不需要释放配置资源的。
2)创建topic:
创建的topi对象是可以复用的(producer的实例化对象(rd_kafka_t)也是允许复用的,所以这两者就没有必要频繁创建)
实例化一个或多个 topic(rd_kafka_topic_t)用于生产或消费。
topic 对象保存 topic 级别的属性,并且维护一个映射,
该映射保存所有可用 partition 和他们的领导 broker 。
通过调用rd_kafka_topic_new()创建(rd_kafka_topic_new(rk, topic, NULL);)。
注:rd_kafka_t 和 rd_kafka_topic_t都源于可选的配置 API。
不使用该 API 将导致 librdkafka 使用列在文档CONFIGURATION.md中的默认配置。
3)Producer API:
通过调用RD_KAFKA_PRODUCER设置一个或多个rd_kafka_topic_t对象,就可以准备好接收消息,并组装和发送到 broker。
rd_kafka_produce()函数接受如下参数:
rkt : 待生产的topic,之前通过rd_kafka_topic_new()生成
partition : 生产的 partition。如果设置为RD_KAFKA_PARTITION_UA(未赋值的),则会根据builtin partitioner去选择一个确定 partition。kafka会回调partitioner进行均衡选取,partitioner方法需要自己实现。可以轮询或者传入key进行hash。未实现则采用默认的随机方法rd_kafka_msg_partitioner_random随机选择。
可以尝试通过partitioner来设计partition的取值。
msgflags : 0 或下面的值:
RD_KAFKA_MSG_F_COPY 表示librdkafka 在信息发送前立即从 payload 做一份拷贝。如果 payload 是不稳定存储,如栈,需要使用这个参数。这是以防消息主体所在的缓存不是长久使用的,才预先将信息进行拷贝。
RD_KAFKA_MSG_F_FREE 表示当 payload 使用完后,让 librdkafka 使用free(3)释放。 就是在使用完消息后,将释放消息缓存。
这两个标志互斥,如果都不设置,payload 既不会被拷贝也不会被 librdkafka 释放。
如果RD_KAFKA_MSG_F_COPY标志不设置,就不会有数据拷贝,librdkafka 将占用 payload 指针(消息主体)直到消息被发送或失败。librdkafka 处理完消息后,会调用发送报告回调函数,让应用程序重新获取 payload 的所有权。
如果设置了RD_KAFKA_MSG_F_FREE,应用程序就不要在发送报告回调函数中释放 payload。
payload,len : 消息 payload(message payload,即值),消息长度
key,keylen : 可选的消息键及其长度,用于分区。将会用于 topic 分区回调函数,如果有,会附加到消息中发送给 broker。
msg_opaque : 可选的,应用程序为每个消息提供的无类型指针,提供给消息发送回调函数,用于应用程序引用。
rd_kafka_produce() 是一个非阻塞 API,该函数会将消息塞入一个内部队列并立即返回。
如果队列中的消息数超过queue.buffering.max.messages属性配置的值,rd_kafka_produce()通过返回 -1,并将errno设置为ENOBUFS这样的错误码来反馈错误。
提示: 见 examples/rdkafka_performance.c 获取生产者的使用。
Consumer的使用方法:
consumer API要比producer API多一些状态。 在使用RD_KAFKA_CONSUMER类型(调用rd_kafka_new时设置的函数参数)创建rd_kafka_t 对象,再通过调用rd_kafka_brokers_add对上述new出来的Kafka handle(rk)进行broker的添加(rd_kafka_brokers_add(rk, brokers)),
然后创建rd_kakfa_topic_t对象之后,
rd_kafka_query_watermark_offsets
创建topic:
rtk = rd_kafka_topic_new(rk, topic, topic_conf)
开始消费:
调用rd_kafka_consumer_start()函数(rd_kafka_consume_start(rkt, partition, start_offset))启动对给定partition的consumer。
调用rd_kafka_consumer_start需要的参数如下:
rkt : 要消费的 topic ,之前通过rd_kafka_topic_new()创建。
partition : 要消费的 partition。
offset : 消费开始的消息偏移量。可以是绝对的值或两种特殊的偏移量:
RD_KAFKA_OFFSET_BEGINNING 从该 partition 的队列的最开始消费(最早的消息)。
RD_KAFKA_OFFSET_END 从该 partition 产生的下一个消息开始消费。
RD_KAFKA_OFFSET_STORED 使用偏移量存储。
当一个 topic+partition 消费者被启动,librdkafka 不断尝试从 broker 批量获取消息来保持本地队列有queued.min.messages数量的消息。
本地消息队列通过 3 个不同的消费 API 向应用程序提供服务:
rd_kafka_consume() - 消费一个消息
rd_kafka_consume_batch() - 消费一个或多个消息
rd_kafka_consume_callback() - 消费本地队列中的所有消息,且每一个都调用回调函数这三个 API 的性能按照升序排列,rd_kafka_consume()最慢,rd_kafka_consume_callback()最快。不同的类型满足不同的应用需要。
被上述函数消费的消息返回rd_kafka_message_t类型。
rd_kafka_message_t的成员:
* err - 返回给应用程序的错误信号。如果该值不是零,payload字段应该是一个错误的消息,err是一个错误码(rd_kafka_resp_err_t)。
* rkt,partition - 消息的 topic 和 partition 或错误。
* payload,len - 消息的数据或错误的消息 (err!=0)。
* key,key_len - 可选的消息键,生产者指定。
* offset - 消息偏移量。不管是payload和key的内存,还是整个消息,都由 librdkafka 所拥有,且在rd_kafka_message_destroy()被调用后不要使用。
librdkafka 为了避免消息集的多余拷贝,会为所有从内存缓存中接收的消息共享同一个消息集,这意味着如果应用程序保留单个rd_kafka_message_t,将会阻止内存释放并用于同一个消息集的其他消息。
当应用程序从一个 topic+partition中消费完消息,应该调用rd_kafka_consume_stop()来结束消费。该函数同时会清空当前本地队列中的所有消息。
提示: 见 examples/rdkafka_performance.c 获取消费者的使用。
在Kafka broker中server.properties文件配置(参数log.dirs=/data2/logs/kafka/)使得写入到消息队列中的topic在该目录下对分区的形式进行存储。每个分区partition下是由segment file组成,而segment file包括2大部分:分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
具体示例:
本文所采用的是cpp方式,和上述介绍的只是函数使用上的不同,业务逻辑是一样的。
在producer过程中直接是使用PARTITION_UA 但是在消费的时候,不能够指定partition值为PARTITION_UA因为该值其实是-1,对于Consumer端来说,是无意义的。根据源码可以知道当不指定partitioner的时候,其实是有一个默认的partitioner,就是Consistent-Random partitioner所谓的一致性随机partitioner。一致性hash对关键字进行map映射之后到一个特定的partition。
函数原型:
rd_kafka_msg_partitioner_consistent_random (
const rd_kafka_topic_t *rkt,
const void *key, size_t keylen,
int32_t partition_cnt,
void *opaque, void *msg_opaque);PARTITION_UA其实是Unassigned partition的意思,即是未赋值的分区。RD_KAFKA_PARTITION_UA (unassigned)其实是自动采用topic下的partitioner函数,当然也可以直接采用固定的值。
在配置文件config/server.properties中是可以设置partition的数量num.partitions。
分配分区
在分配分区的时候,要注意。对于一个已经创建了分区的主题且已经指定了分区,那么之后的producer代码如果是直接修改partitioner部分的代码,直接引入key值进行分区的重新分配的话,是不行的,会继续按照之前的分区进行添加(之前的分区是分区0,只有一个)。此时如果在程序中查看partition_cnt我们是可以看到,该值并没有因为config/server.properties的修改而变化,这是因为此时的partition_cnt是针对该已经创建的主题topic的。
而如果尚自单纯修改代码中的partition_cnt在用于计算分区值时候:djb_hash(key->c_str(), key->size()) % 5 是会得到如下结果的:提示分区不存在。

我们可以通过rdkafka_example来查看某个topic下对应的partition数量的:
./rdkafka_example -L -t helloworld_kugou -b localhost:9092
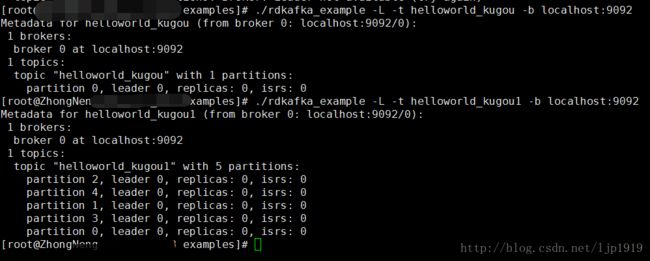
从中我们可以看到helloworld_kugou主题只有一个partition,而helloworld_kugou1主题是有5个partition的,这个和我们预期的相符合。
我们可以对已经创建的主题修改其分区:
./bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --alter --partition 5 --topic helloworld_kugou
修改完之后,我们可以看出,helloworld_kugou已经变为5个分区了。


具体示例:
创建topic为helloworld_kugou_test,5个partition。我们可以看到,在producer端进行输入之前,在预先设置好的log目录下是已经有5个partition:

producer端代码:
class ExampleDeliveryReportCb : public RdKafka::DeliveryReportCb
{
public:
void dr_cb (RdKafka::Message &message) {
std::cout << "Message delivery for (" << message.len() << " bytes): " <<
message.errstr() << std::endl;
if (message.key())
std::cout << "Key: " << *(message.key()) << ";" << std::endl;
}
};
class ExampleEventCb : public RdKafka::EventCb {
public:
void event_cb (RdKafka::Event &event) {
switch (event.type())
{
case RdKafka::Event::EVENT_ERROR:
std::cerr << "ERROR (" << RdKafka::err2str(event.err()) << "): " <<
event.str() << std::endl;
if (event.err() == RdKafka::ERR__ALL_BROKERS_DOWN)
run = false;
break;
case RdKafka::Event::EVENT_STATS:
std::cerr << "\"STATS\": " << event.str() << std::endl;
break;
case RdKafka::Event::EVENT_LOG:
fprintf(stderr, "LOG-%i-%s: %s\n",
event.severity(), event.fac().c_str(), event.str().c_str());
break;
default:
std::cerr << "EVENT " << event.type() <<
" (" << RdKafka::err2str(event.err()) << "): " <<
event.str() << std::endl;
break;
}
}
};
/* Use of this partitioner is pretty pointless since no key is provided
* in the produce() call.so when you need input your key */
class MyHashPartitionerCb : public RdKafka::PartitionerCb {
public:
int32_t partitioner_cb (const RdKafka::Topic *topic, const std::string *key,int32_t partition_cnt, void *msg_opaque)
{
std::cout<<"partition_cnt="<std::endl;
return djb_hash(key->c_str(), key->size()) % partition_cnt;
}
private:
static inline unsigned int djb_hash (const char *str, size_t len)
{
unsigned int hash = 5381;
for (size_t i = 0 ; i < len ; i++)
hash = ((hash << 5) + hash) + str[i];
std::cout<<"hash1="<std::endl;
return hash;
}
};
void TestProducer()
{
std::string brokers = "localhost";
std::string errstr;
std::string topic_str="helloworld_kugou_test";//自行制定主题topic
MyHashPartitionerCb hash_partitioner;
int32_t partition = RdKafka::Topic::PARTITION_UA;
int64_t start_offset = RdKafka::Topic::OFFSET_BEGINNING;
bool do_conf_dump = false;
int opt;
int use_ccb = 0;
//Create configuration objects
RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
RdKafka::Conf *tconf = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC);
if (tconf->set("partitioner_cb", &hash_partitioner, errstr) != RdKafka::Conf::CONF_OK)
{
std::cerr << errstr << std::endl;
exit(1);
}
/*
* Set configuration properties
*/
conf->set("metadata.broker.list", brokers, errstr);
ExampleEventCb ex_event_cb;
conf->set("event_cb", &ex_event_cb, errstr);
ExampleDeliveryReportCb ex_dr_cb;
/* Set delivery report callback */
conf->set("dr_cb", &ex_dr_cb, errstr);
/*
* Create producer using accumulated global configuration.
*/
RdKafka::Producer *producer = RdKafka::Producer::create(conf, errstr);
if (!producer)
{
std::cerr << "Failed to create producer: " << errstr << std::endl;
exit(1);
}
std::cout << "% Created producer " << producer->name() << std::endl;
/*
* Create topic handle.
*/
RdKafka::Topic *topic = RdKafka::Topic::create(producer, topic_str, tconf, errstr);
if (!topic) {
std::cerr << "Failed to create topic: " << errstr << std::endl;
exit(1);
}
/*
* Read messages from stdin and produce to broker.
*/
for (std::string line; run && std::getline(std::cin, line);)
{
if (line.empty())
{
producer->poll(0);
continue;
}
/*
* Produce message
// 1. topic
// 2. partition
// 3. flags
// 4. payload
// 5. payload len
// 6. std::string key
// 7. msg_opaque? NULL
*/
std::string key=line.substr(0,5);//根据line前5个字符串作为key值
// int a = MyHashPartitionerCb::djb_hash(key.c_str(),key.size());
// std::cout<<"hash="<
RdKafka::ErrorCode resp = producer->produce(topic, partition,
RdKafka::Producer::RK_MSG_COPY /* Copy payload */,
const_cast<char *>(line.c_str()), line.size(),
key.c_str(), key.size(), NULL);//这里可以设计key值,因为会根据key值放在对应的partition
if (resp != RdKafka::ERR_NO_ERROR)
std::cerr << "% Produce failed: " <std ::endl;
else
std::cerr << "% Produced message (" << line.size() << " bytes)" <<std::endl;
producer->poll(0);//对于socket进行读写操作。poll方法才是做实际的IO操作的。return the number of events served
}
//
run = true;
while (run && producer->outq_len() > 0) {
std::cerr << "Waiting for " << producer->outq_len() << std::endl;
producer->poll(1000);
}
delete topic;
delete producer;
} 在Consumer端进行验证的时候,可以发现不同的partition确实写入了不同的数据。结果如下:

Consumer端代码:
void msg_consume(RdKafka::Message* message, void* opaque)
{
switch (message->err())
{
case RdKafka::ERR__TIMED_OUT:
break;
case RdKafka::ERR_NO_ERROR:
/* Real message */
std::cout << "Read msg at offset " << message->offset() << std::endl;
if (message->key())
{
std::cout << "Key: " << *message->key() << std::endl;
}
printf("%.*s\n", static_cast<int>(message->len()),static_cast<const char *>(message->payload()));
break;
case RdKafka::ERR__PARTITION_EOF:
/* Last message */
if (exit_eof)
{
run = false;
}
break;
case RdKafka::ERR__UNKNOWN_TOPIC:
case RdKafka::ERR__UNKNOWN_PARTITION:
std::cerr << "Consume failed: " << message->errstr() << std::endl;
run = false;
break;
default:
/* Errors */
std::cerr << "Consume failed: " << message->errstr() << std::endl;
run = false;
}
}
class ExampleConsumeCb : public RdKafka::ConsumeCb {
public:
void consume_cb (RdKafka::Message &msg, void *opaque)
{
msg_consume(&msg, opaque);
}
};
void TestConsumer()
{
std::string brokers = "localhost";
std::string errstr;
std::string topic_str="helloworld_kugou_test";//helloworld_kugou
MyHashPartitionerCb hash_partitioner;
int32_t partition = RdKafka::Topic::PARTITION_UA;//为何不能用??在Consumer这里只能写0???无法自动吗???
partition = 3;
int64_t start_offset = RdKafka::Topic::OFFSET_BEGINNING;
bool do_conf_dump = false;
int opt;
int use_ccb = 0;
//Create configuration objects
RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
RdKafka::Conf *tconf = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC);
if (tconf->set("partitioner_cb", &hash_partitioner, errstr) != RdKafka::Conf::CONF_OK)
{
std::cerr << errstr << std::endl;
exit(1);
}
/*
* Set configuration properties
*/
conf->set("metadata.broker.list", brokers, errstr);
ExampleEventCb ex_event_cb;
conf->set("event_cb", &ex_event_cb, errstr);
ExampleDeliveryReportCb ex_dr_cb;
/* Set delivery report callback */
conf->set("dr_cb", &ex_dr_cb, errstr);
/*
* Create consumer using accumulated global configuration.
*/
RdKafka::Consumer *consumer = RdKafka::Consumer::create(conf, errstr);
if (!consumer)
{
std::cerr << "Failed to create consumer: " << errstr << std::endl;
exit(1);
}
std::cout << "% Created consumer " << consumer->name() << std::endl;
/*
* Create topic handle.
*/
RdKafka::Topic *topic = RdKafka::Topic::create(consumer, topic_str, tconf, errstr);
if (!topic)
{
std::cerr << "Failed to create topic: " << errstr << std::endl;
exit(1);
}
/*
* Start consumer for topic+partition at start offset
*/
RdKafka::ErrorCode resp = consumer->start(topic, partition, start_offset);
if (resp != RdKafka::ERR_NO_ERROR) {
std::cerr << "Failed to start consumer: " << RdKafka::err2str(resp) << std::endl;
exit(1);
}
ExampleConsumeCb ex_consume_cb;
/*
* Consume messages
*/
while (run)
{
if (use_ccb)
{
consumer->consume_callback(topic, partition, 1000, &ex_consume_cb, &use_ccb);
}
else
{
RdKafka::Message *msg = consumer->consume(topic, partition, 1000);
msg_consume(msg, NULL);
delete msg;
}
consumer->poll(0);
}
/*
* Stop consumer
*/
consumer->stop(topic, partition);
consumer->poll(1000);
delete topic;
delete consumer;
}那么在producer端怎么根据key值获取具体是进入哪个partition的呢?是否有接口可以查看呢?这个有待补充。