深入理解mysql中的B-tree索引以及查询类型
学过mysql的估计知道,mysql中具有索引功能,通过索引我们能更快的得到数据。而mysql的索引使用的数据结构,没有特别说明,都是用的B-tree(更进一步说是B+-tree),当然也有hash索引,位图索引,R树索引等。但是绝大多数还是B+树索引
B树
B-tree即B树,不是B减树。。中间的横杆只是分隔符。B树是一种平衡树,如下:


B树的特点很明显,与二叉排序树,AVL树,红黑树类似。左边的节点比右边的节点小,所以如果你从左到右读,就会发现,是从小到大排序的。但与他们不同的是。B树不是二叉树,而是多叉树,至于有多少个叉,看需求。因此,B树中一个节点会存放多个子节点的指针。这样,每次B树在一个节点可以经过多次比较,从而确定下一个节点的位置。直到找到数据,或者找不到返回。可见其速率之快。
但是,B树由于是平衡树,跟AVL树,红黑树一样,每次插入,删除,修改数据后,都必须调整节点顺序,这使得B树的增删改操作变得十分浪费时间。这就是为什么很多人说,mysql的索引尽量建立在不常修改的列上
对比比红黑树的优点:由于每个节点有多个子节点,因此树的深度将会变低。而树的深度影响IO次数(后面会说),也就提高了速度
B+树
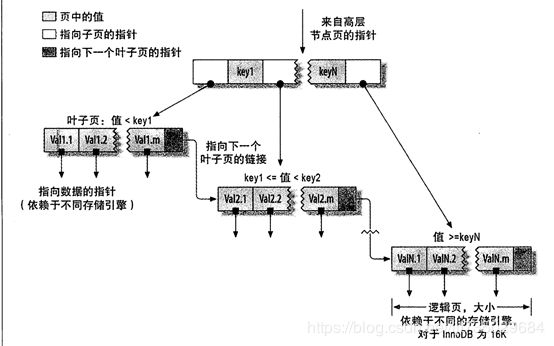
B+树是B树的改版,为了更适合磁盘索引来使用的,与B树的不同是,B+树中,只在叶子节点存放数据,非叶子节点不存储数据。如下图

比B树的优点:由于B+树一般是在磁盘上使用的,以页为单位,B+树一个节点就是一个页。因为非叶子节点不存放数据,所以非叶子节点便可利用这空间存放更多的索引(或者说指针),这就进一步导致B+树的深度比B树低。
比B树的缺点:需要走到叶子节点才能找到数据。如果数据在上层将比较浪费时间。
实际上,B+树在实际使用时,还会在叶子节点当成一个双向链表。这样,在需要时,可以直接遍历叶子节点(如InnoDB中的索引级别type中index,就是这样遍历,后面会说)

综合考虑后,大多数数据库还是使用了B+树做为索引。
外存中使用B+树的优点
这里先给出结论,一般内存中使用红黑树,外存(如磁盘)中使用B+树。
至于为什么呢,这里就要提到内存跟磁盘的找数据的不同
计算机使用的主存基本都是随机读写存储器(RAM),抽象出一个十分简单的存取模型来说明RAM的工作原理
内存RAM中找数据
我们将内存模型简化,那么就会如下图一样:
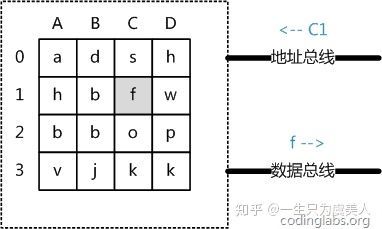
CPU在地址总线中传入第C列跟第1行的电信号C1(如果懂点操作系统,就会在知道这叫段地址跟偏移地址),然后取出数据f。
可以看到的是,无论访问矩阵上的哪个数据,基本都是一样的时间,因为只要内存把那行跟列的数据激活就行了。因此内存的在计算机上的名字是RAM(Random Access Memory),随机访问存储器,意味着:无论你找哪个地方的数据,对我来说找到的时间都一样。
这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响
磁盘查找数据
索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O 与主存不同,磁盘I/O存在机械消耗,因此磁盘I/O时间消耗巨大

磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各磁盘必须同步转动) 在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不能转动,但是可以沿磁盘半径方向运动(实际是斜切向运动)

盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,不同盘片上所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。为了简单起见,我们下面假设磁盘只有一个盘片和一个磁头。
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区 为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
局部性原理与磁盘预读
由于存储介质特性,磁盘本身存取就比主存慢,再加上机械运动耗费,磁盘的存取速度往往是主存的几百万分之一,因此为了提高效率,要尽量减少磁盘I/O次数,如果要减少I/O,那么就只能每次增加数据长度。 为了达到这个目的,磁盘每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理, 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
那么,这个长度多少合适呢?操作系统规定:
预读的长度一般为页(page)的整数倍 页是存储器的逻辑块,操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页大小通常为4k,这也是B+树为什么一个节点设为一个页的原因,这部分由MMU管理,有兴趣的可以参考《深入理解计算机系统》中的虚拟内存章节)
为什么使用B+树,而不是红黑树
通过上面的讲解,我们知道了在一定范围内增长节点长度,有利于减少磁盘I/0,因此,B+树的优点就体现在此,因为B+树每个节点的数据长度都很长(一个页),而红黑树是二叉树,一个节点只存放一个数据,指针跟颜色的等,因此B+数比红黑树更能减少磁盘I/0,这就是为什么外存中要使用B+树的原因。
而在内存中,由于长度并不影响索引速度,因此红黑树更胜一筹,因为它不用找到叶子节点才返回数据,再加上B+树增删改比红黑树更麻烦,因为需要考虑分裂等问题,导致B+树没有红黑树那么适合用在内存存储。
MYSQL索引
上面的讲解,说了B+树是怎样的数据结构,以及B+树有什么优点。下面开始说mysql的索引,可能太多了一下子写不完,只能留着以后补坑(先讲原理,例子有时间再补坑)
聚集索引与非聚集索引
非聚集索引中
mysql的索引中,叶子节点存放的不数据,而是指向表数据的指针。如InnoDB中,叶子节点存放表的主键,然后通过主键去寻找表中的列找到数据后返回。
聚集索引
聚集索引跟费聚集索引最大的不同就是,聚集索引叶子节点存放着从表中拷贝来的列的数据,如果索引中字段存在,则不需要回表操作。
优点很明显:不需要回表操作,只需要在此索引中搜索便可以找到数据。减少了回表跟锁开销,速度很快。
缺点也很明显:每次修改时,都需要对每个B+树节点进行调整,因此进行写操作时会非常浪费时间,而且,索引由于保存了数据,也会浪费空间,总体来说,这是以空间换时间的策略
当你建立了一个多列索引的时候是这样的,这里的索引
key(last_name, first_name, birthday)

可以发现,里面的排序,字符串一般是按字典序顺序排列,,当字段值一样时,根据后字段一个大小进行排序(如最后一个)。
根据这个图,存储结构,就可以理解索引的数据是多么重要,为什么要索引要使用第一个字段后再第二个字段再第三了。这就是为什么mysql中有个最左原则

如上图中,假设现在有索引inde(C1,C2,C3), 最大块的两块蓝色跟绿色代表两个不同的C1值,橙色跟黄色代表不同的C2值,灰色代表不同的C3值。
事先说明:由于InnoDB中会B+树叶节点会保留主键值,因此,可以直接通过索引获取id
ref级查询原理
此时,如果是一个ref级的查询,比如查找select id from table C1=蓝,C2=橙色,C3=3。C1上有C2索引,因此只需要一次就找到橙色,由于C2上有C3索引,因此一次就找到3,一个两次,mysql会找到唯一的 3号数据。ref级就是经典的B树查询,只需要log(n)-1次I/O就可以找到
range级查询的原理
但是如果你再查找时,使用的select id from table where C1=蓝,C3=3,那么由于没有传入C2的值。那么mysql只能在蓝色区域顺序遍历判断所有C3(图中1-9)。那么你一共使用了10次,那么明显慢了很多。(这里只是方便说明,并不代表真实用了10次)
另外,mysql5.6之后的版本加入了Using index condition,可以达到range级。如select C4 from table where C1 in(蓝,绿)
由于C1具有索引且是第一列,mysql会找到适合的数据,但由于C4不是索引中有的数据,会在引擎层先where过滤(5.6前都是服务层),然后再进行回表操作,找到C4
index级查询原理
加入你单纯的使用select C3 from table where C2=黄色,那么,此时的查询会是index级的。一般被称为覆盖索引,因为的索引中有包含此数据,但是你连第一个的索引字段都没有使用,导致B+树的查找数据方法几乎完全失效。
不过你还是幸运的,因为你查找的值C3在B+树叶子节点有保留一,因此不需要回表操作。还记得B+树比B树多的其中一个特性么?就是叶子节点使用了指针连起来构成双向链表,因此,你只要顺着这链表遍历完所有节点,就能完事了,这样的速度,还是比回表操作快不少的。你通过遍历所有节点,取出C2=黄色的节点,再将其C3的值返回就完事了。此时你也会发现explain中的的extra字段为using index
ALL级操作
最低级的操作,如select C4 from table where C2=黄色。由于条件只有C2,一般要使用覆盖索引,但因为没有包括C4字段,因此无法使用索引,只能回表,并进行全表扫描,因此退化为All级。没有建立索引时也为All级
由于本人知识跟查找资料有限限制,对mysql也只有非常浅的了解,若有出现什么错误,望大神在评论区告知,本人会进行修正,非常感谢!!
参考文章:
https://zhuanlan.zhihu.com/p/49947103(若原文失效,印象笔记链接:https://app.yinxiang.com/Home.action#n=c113f03c-5207-499c-8f08-1152c082c72a&s=s64&ses=4&sh=2&sds=5&)
https://www.cnblogs.com/aspwebchh/p/6652855.html(若原文失效,印象笔记链接:https://app.yinxiang.com/Home.action#n=267dd113-beb1-4dc0-a33d-d8c868664383&s=s64&ses=4&sh=2&sds=5&)
《高性能Mysql第三版》