《高性能MySQL》读书笔记(上)
http://blog.csdn.net/dc_726/article/details/41777773
《High Performance MySQL》真是本经典好书,从应用层到数据库到硬件平台,各种调优技巧、常见问题全都有所提及。数据库的各种概念技巧平时都有接触,像索引、分区、Sharding等等,但要想真正提高还是得如此系统学习一下。
Chapter 1: MySQL Architecture and History
1.1 Transaction Isolation Level
事务隔离级别真是个老生常谈的问题的,但大多材料一提到脏读、幻读、重复读就讲得云里雾里,所以还是自己动手实践能体会最深。推荐文章: MySQL数据库事务隔离级别。
1.2 Implicit and Explicit Locking
InnoDB默认自动根据事务隔离级别管理锁,同时支持两种标准SQL未提及的显示锁(Explicit Locking):
- SELECT ... LOCK IN SHARE MODE
- SELECT ... FOR UPDATE
- LOCK/UNLOCK TABLES
InnoDB采用 两阶段锁协议(Two-phase Locking Protocol)。在事务内任意时刻加锁,最后提交或回滚时一起释放所有锁。两阶段锁协议(跟分布式事务XA的两阶段提交)具体如下:
“一次性锁协议:事务开始时,一次性申请所有的锁,之后不会再申请任何锁。如果其中某个锁不可用,则整个申请就不成功,事务就不会执行,在事务尾端,一次性释放所有的锁。一次性锁协议不会产生死锁的问题,但事务的并发度不高。
“两阶段锁协议:整个事务分为两个阶段,前一个阶段为加锁,后一个阶段为解锁。在加锁阶段,事务只能加锁,也可以操作数据,但不能解锁。直到事务释放第一个锁,就进入解锁阶段,此过程中事务只能解锁,也可以操作数据,不能再加锁。
两阶段锁协议
使得事务具有较高的并发度,因为解锁不必发生在事务结尾。它的
不足是没有解决死锁的问题,因为它在加锁阶段没有顺序要求。如两个事务分别申请了A, B锁,接着又申请对方的锁,此时进入死锁状态。
1.3 Multiversion Concurrency Control
类似于乐观锁机制,但一些文章介绍到InnoDB实现不是纯粹的MVCC。先标注一下,回头进行深入源码研究。收藏文章:何登成的 InnoDB多版本(MVCC)实现简要分析,老码农的 MySQL中的MVCC。
“Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
“理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用, Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
“理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用, Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
Chapter 4: Optimizing Schema and Data Types
4.1 Choosing Optimal Data Types
本章一上来就精辟的提出了关于模式和数据类型的总设计原则,那就是:
- Smaller is usually better(越小通常越好):因为占用更少磁盘空间,内存以及CPU缓存,所以越小通常代表越快。
- Simple is good(简单的就是好的):因为字符集和排序规则(Collation)使得字符串的比较很复杂,所以我们应当用Integer等内建类型而非字符串来保存日期时间或IP地址。
- Avoid NULL if possible(尽可能避免NULL):MySQL对NULL有特殊的处理逻辑,所以NULL会使索引、索引统计、值比较都变得更加复杂。
4.2 Using ENUM Instead Of A String Type
MySQL内部将枚举保存为整数,通过一张Lookup Table保存枚举与整数的对应关系。所以使用枚举非常节省空间(原则1越小越好越快),根据枚举总个数而定,只会占用1或2个字节。
但是随之而来的问题是:添加删除枚举值都要ALTER TABLE。并且使用Lookup Table进行转换时也会有开销,尤其是与CHAR或VARCHAR类型的列做联接时,但有时这种开销可以被枚举节省空间的优势所抵消。
4.3 Cons of A Normalized Schema
规范化范式(Normalized Schema)不仅增加JOIN数,并且会使本可以属于一个索引的列分隔到不同的表中。
例如:
SELECT ... FROM message INNER JOIN user USING(user_id)
WHERE user.account_type = 'premium'
ORDER BY message.published DESC LIMIT 10
则有两种执行计划:
- 倒序走published索引扫描message表,每行都去user表检查是否type为'premium',直到找到10行。
- 走account_type索引扫描user表找到所有type为'premium'的行,进行filesort后返回10行。
上面的问题本质在于:
JOIN使我们无法通过一个索引就同时完成排序和过滤。
改为非规范化 =>
SELECT .. FROM user_message
WHERE account_type = 'premium'
ORDER BY published DESC LIMIT 10
则(account_type, published)上的索引能高效地完成任务!
4.4 Cache and Summary Tables
这一部分紧接上面关于Normalized和Denormalized Schema的Pros and Cons的讨论,从4.4到4.6提出了几种冗余数据的常用且实用的方法。
这几种技术本质上都是为了加速查询操作,但代价是拖慢了写操作,并且会增加开发的复杂度。
缓存表(Cache Table)指那些包含能够轻松从Schema中获得的数据的表,即表中的数据是逻辑冗余(Logically Redundant)。汇总表(Summary/Roll-up Table)是说包含通过聚合函数得到的数据的表,例如表中数据是通过GROUP BY得到的。
为什么需要它们呢?最常见的场景就是报表等统计工作。生成这些统计数据要扫描大量数据,实时计算成本很高且很多时候没有必要。而且查询这些数据还要加大量组合索引(各种维度的)才能提高性能,然而这些索引又会对平时的更新和插入等操作造成影响。于是常用技术就是添加中间表到其他引擎(利用MyISAM更小的索引和全文检索能力),甚至其他系统(Lucene或Sphinx)。
有了中间表作为缓存,我们需要定期的更新或者重建它。影子表(Shadow Table)是一种不错的技术!
mysql>
DROP TABLE IF EXISTS my_summary_new, my_summary_old;
mysql>
CREATE TABLE my_summary_new LIKE my_summary;
mysql>
RENAME TABLE my_summary TO my_summary_old, my_summary_new TO my_summary
只需一条rename操作,我们就可以原子地将影子表替换上去(swap with an atomic rename),并且之前的表也保留下来以防需要回滚。
4.5 Materialized Views
物化视图即预先计算并真正存储在磁盘上的视图(一般视图是不会实际存储,在访问视图时执行对应的SQL获得数据)。MySQL没有物化视图,但有一个很棒的开源实现 Flexviews Tools。它有一些很有用的功能,例如:
- CDC(Change Data Capture)工具能够读取日志(Binary Logs),并提取对应的行变化。
- 一组帮助定义和管理视图的存储过程
- 将改变反应到物化视图数据上的工具
具体来说,它利用基于行的日志(Row-based Binary Log)包含了变化行的前后数据,所以Flextviews能够在无需访问源表的情况下,知道变化前和变化后的数据,并重新计算物化视图。这是它相比我们自己维护的Cache表或Summary表的优势。
4.6 Counter Tables
Web应用一个常见问题就是并发访问计数表,此书中提出方案来提高并发量。总体设计思路是:添加更多的槽来分散并发的访问。与Java的Concurrent并发包中的ConcurrentHashMap的设计理念有些像。
计数表和对应访问SQL可以简化如下:
mysql>
CREATE TABLE hit_counter(cnt int unsigned not null) ENGINE=InnoDB;
mysql>
UPDATE hit_counter SET cnt = cnt + 1;
可以看出,表中的一行计数器数据其实相当于全局锁,对它的更新将会被串行化。所以,首先建表时加入Slot一列。并初始化100条数据。
CREATE TABLE hit_counter(
slot tinyint unsigned not null primary key,
cnt int unsigned not null
) ENGINE=InnoDB;
之后将更新和查询SQL改为:
mysql>
UPDATE hit_counter SET cnt = cnt + 1 WHERE slot = RAND() * 100;
mysql>
SELECT SUM(cnt) FROM hit_counter;
ps:如果需要每天刷新计数器的话,那么建表时就加入时间列:
CREATE TABLE daily_hit_counter(
day date not null,
slot tinyint unsigned not null primary key,
cnt int unsigned not null,
primary key(day, slot)
) ENGINE=InnoDB;
pss:如果不想每天都插入初始数据的话,可以用下面的SQL:
mysql>
INSERT INTO daily_hit_counter(day, slot, cnt)
VALUES(CURRENT_DATE, RAND() * 100, 1)
ON DUPLICATE KEY UPDATE cnt = cnt + 1;
psss:如果想减少计数器的行数来节约空间,那么可以执行一个定期任务来合并所有记录到Slot 0:
Chapter 5: Indexing for High Performance
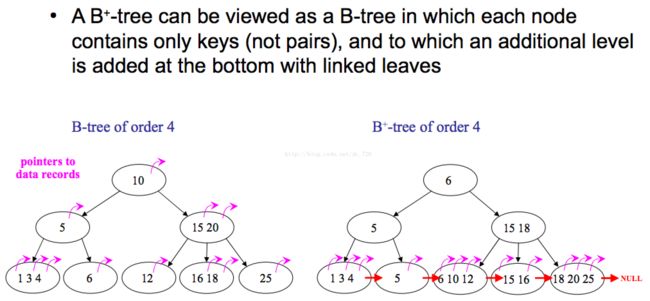
5.1 B-Tree Family
所以准确地说我们使用的是B树大家族里B树的各种变形。
各种变形的核心是围绕着内结点出度(例如基于内存的T树和基于磁盘的B树)、存储使用率(B树和B+树)等方面进行的。
首先B树与其他数据结构如红黑树、普通AVL树的最大区别就是:B树的结点有很多个子结点。而这一点正是为减少磁盘I/O读取开销而设计。因为子结点很多,所以树的总体高度很低,这样就只需加载少量的磁盘页就能查找到目标数据。那关于B树和B+树的区别呢:B+树的内结点不存data(即指向key所在数据行的指针),只存key。
B+树的优势:
- 因为内部结点不存data了,所以在一个磁盘页上能存更多的key了,树的高度进一步降低,从而加快key的查找命中。
- 需要全树遍历时(如某字段的范围查询甚至full scan,这都是很常见而频繁的查询操作),只需要对B+树的叶子结点进行线性遍历即可,而B树则需要树遍历。而线性遍历比树遍历命中率更高(因为相邻数据都很近,不会分散在结点的左右子树中,跨页的概率能低一些吧)
B树的优势:
- 在B树中查找可能在内部结点结束,而B+树则必须在叶子结点结束。
首先引用一个B树查找的 例子:
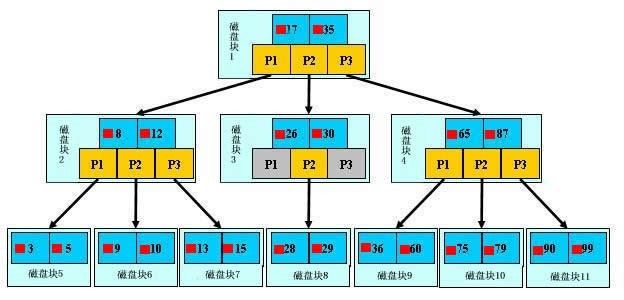
“下面,咱们来模拟下查找文件29的过程:
- 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
- 此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
- 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
- 此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
而B+树就是这个样子:
