python进行文本分类,基于word2vec,sklearn-svm对微博垃圾评论分类
差不多一年前的第一个分类任务,记录一下
语料库是关于微博的垃圾用户评论,分为两类,分别在normal,和spam文件夹下。里面是很多个txt文件,一个txt是一条用户评论。

一、进行分词
利用Jieba分词和去除停用词(这里我用的是全模式分词),每一篇文档为一行 用换行拼接,得到result.txt。其中用到的停用词是在网上随便下载的。
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('stopword.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr去停用词后的结果如图

二.用gensim.word2vec得到词向量模型
这里要用到word2vec来训练词向量,python要安装对应的库。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus(u"./data111") # 加载语料
if os.path.exists("./model"):
model = gensim.models.Word2Vec.load('./model')
else:
model = word2vec.Word2Vec(sentences, min_count=1, size=50) # 训练skip-gram模型
model.save("./model")三.每个文档的句子向量求平均求得文档向量
这里主要是要求得能代表文档的向量,这里就简单的将文档中的句子相加求平均,得到一个50维的文档向量。
def get_word_vector(path):
ip = open(path, 'r', encoding='utf-8')
content = ip.readlines()
vecs = []
for words in content:
# vec = np.zeros(2).reshape((1, 2))
vec = np.zeros(50).reshape((1, 50))
count = 0
words = remove_some(words)
for word in words[1:]:
try:
count += 1
# vec += model[word].reshape((1, 2))
vec += model[word].reshape((1, 50))
# print(vec)
except KeyError:
continue
vec /= count
vecs.append(vec)
return vecs四.sklearn-svm进行分类
这里人工创建两个分别对应垃圾评论和非垃圾评论的标签,分别用0,1来表示两类。然后把对应的标签和语料随机划分成训练集和测试集,放到分类器中训练和测试。
这里的标签是建立了两个列表:
normal_tag = np.ones((len(normal)))
spam_tag = np.zeros((len(spam)))用3:7的比例划分测试和训练集
X_train, X_test, y_train, y_test = train_test_split(np.array(train, dtype='float64'),
np.array(train_tag, dtype='float64'), test_size=0.30,
random_state=0) # 随机选择30%作为测试集,剩余作为训练集训练并得到测试结果
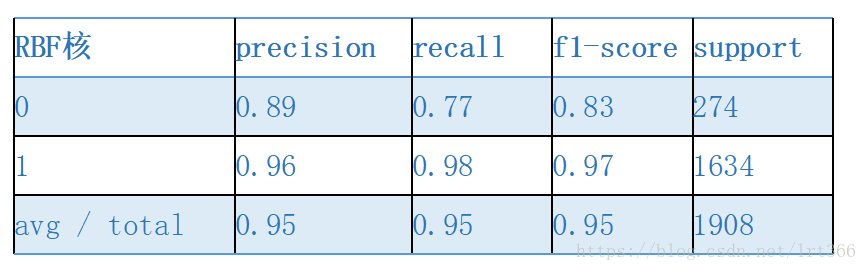
clf = svm.SVC() # 使用RBF核
clf_res = clf.fit(X_train, y_train)
# train_pred = clf_res.predict(X_train)
test_pred = clf_res.predict(X_test)
print(classification_report(y_test, test_pred))其中rbf核的结果比较好,如下所示