JVM工作原理及相关知识总结 (一)
如今公司Java面试对Java底层越来越看重,不仅是阿里、百度这样的大厂,许多互联网公司对这方面的要求也越来越高,一般都会考核JVM相关知识和实践的经验。
毕竟项目上线以后,JVM的运行及GC是现在工程师必须关注的事情,本文对JVM的区域划分及工作原理进行简单的讲解,仅仅代表个人的见解,如有错误和不足,希望大家指出。
区域划分
JVM的区域划分 :
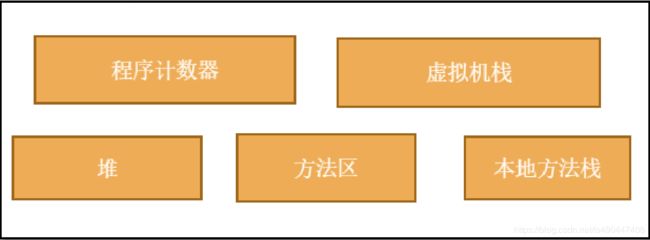
大致分为:程序计数器,虚拟机栈,堆,方法区,本地方法区这几个部分。
接下来,根据Java代码如何通过JVM运行起来,来分析各个区域都起到什么样的作用及运行原理。
程序计数器
我们都知道,我们编译好的Java代码,都是文件后缀为.java的文件,但是这样的文件计算机其实是识别不了的,那么,我们的代码是怎么运行的呢?
如下图:

这是最简单的一个Hello World,也就是java源代码文件,这时就需要编译器,将java文件编译成 .classe 后缀的字节码文件,这个文件里存放着代码编译好的字节码,这些字节码才是计算机能够读懂的语言。
编译好的字节码大致如下图:

说明:只是展示字节码文件大致模样,并非由上图的Java代码转译得到
比如上图的 0:aload_0这样的东西,就是"字节码指令",它对应每一条机器指令,计算机根据这些指令,也就知道自己应该做些什么了。
总结一点就是:java代码转移成字节码,字节码对应字节码指令,这样,JAVA通过JVM跑起来的第一件事情也就明确了。
在编译完成之后,在执行字节码指令时,程序计数器就是记录每个线程当前执行的字节码指令的位置的,记录当前线程目前执行到哪一条指令上。因为计算机在在执行线程是理论随机分配资源的,所以,有可能上一秒在当前线程,下一秒就跳到另外一个线程上面,所以,为了方便记录并且使得当再切回当前线程,可以让计算机根据上次执行位置继续执行当前线程,程序计数器起到了很大的作用。
因为会有许多条线程并发执行不同的代码,所以每个线程都有自己的一个程序计数器,专门记录当前线程执行到哪一条指令上面。
如下图更加清晰的描述他们之间的关系:

Java虚拟机栈
java在执行的时候,一定是线程来执行某个方法中的代码,即使是最基础的Hello Word 也是一个main方法来执行。
在方法里,我们通常会定义一些局部变量,如下图,我们在方法里定义一个 name 的局部变量。

所以,JVM必须有一块区域来保存我们定义的这些局部变量以及其他的一些数据,这个区域就是 Java虚拟机栈。
每个线程都会执行自己对应的Java代码,所以每个线程都有自己的虚拟机栈。
如果一个线程执行一个方法,就会为这个方法调用创建一个 栈帧。
栈帧里有每个方法的局部变量表,操作数栈,动态链接,方法出口等数据。
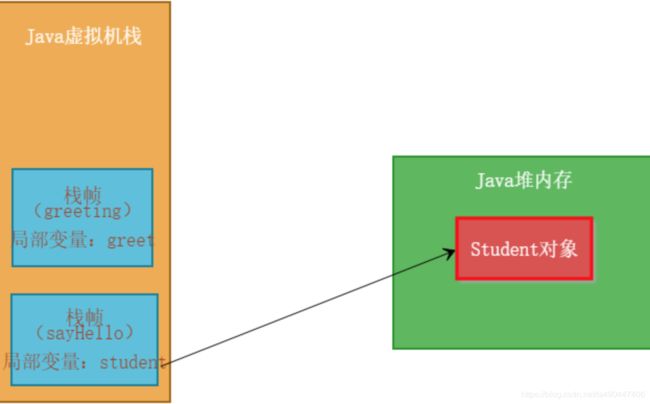
举个例子,比如我们创建一个 "sayHellow()"方法,那么就会为它创建一个栈帧,然后压入线程自己的Java虚拟机栈中,在这个栈帧的局部变量表里就有 name 这个变量。
如下图:

接着,如果这个方法调用另外一个 greating方法:

然后又会为 greating方法创建一个栈帧,压入线程的虚拟机栈中,因为开始执行该方法了,而且,局部变量表中会有 great 这个局部变量。

然后greating方法执行完毕后出栈,最后sayHello方法执行完毕出栈。
不难发现一个规律:先入栈的后出栈,后入栈的先出栈。也就是先入后出,后入先出这个规律。
这也就是Java虚拟机栈的作用:调用任何方法的时候,都会创建栈帧,然后入栈。这个栈帧中存放着局部变量一类的数据,执行完毕后,出栈。
Java堆内存
JVM另外一个非常重要的区域,就是堆,这里存放着我们代码里创建出来的各种对象,比如下图:

上图中,我们 new student() 这样的一个对象实例,这个对象里包含了一些数据,比如 name。
Java堆内存区域里存放着 student的对象,然后方法的栈帧里,会存放这个引用类型为 "student"的局部变量,也就是在堆内存的student这个实例的内存地址,这也就是我们比较两个对象看似都是创建的相同的对象,但是为什么比较会出现false的情况,因为他们在堆内存中地址不一样,怎么会是同一对象呢。
换句话就是说: 局部变量表里的 student 指向 堆里的 student对象。如下图:
方法区/Metaspace
方法区这个概念是在 JDK1.8之前的版本,代表JVM的一块区域。
他存放的主要是 student 这样的类的类信息,比如我们平常用的各种类的信息,都会存放在这里。
在JDK1.8之后,改名为 Metaspace,当然存放的一些信息没有变。
本地方法栈
在JDK底层API里,比如IO,网络Socket这些,如果我们点进他们的内部源码,会发现很多地方都不是Java代码了。
很多地方都会走一个叫 native方法,去调取他本地库里的一些方法,可能是一些C语言或者其他的方法,作者能力有限,并不是看的太懂。比如最常见的 hashCode()方法。
堆外内存
该区域并不属于JVM区域,通过NIO的 allocateDirect这种API,可以在Java堆内存之外分配内存空间,然后通过Java虚拟机DirectByteBuffer来引用和操作这些堆外内存,这也是很多技术JVM调优,提升性能的方法。
总结
java代码通过JVM运行:
1. 首先转译成字节码指令
2. 执行过程中,线程为每个方法创建栈帧存放在JAVA虚拟机栈,来入栈出栈,每个栈帧存放着局部变量等信息
3. 接着对象创建,存放在堆内存中
4. 类信息,会存放在方法区这个区域里
特殊区域:
本地方法栈:执行native这样方法的栈,运行原理和虚拟机栈基本相同
堆外内存:分配Java堆内存外的内存区域。存储对象。
到这里,本文对JVM相关的区域划分和总结基本就结束了,当然这些大部分都是浅谈,仅仅靠这些进入大厂是不够得,还有很多需要了解和懂得运用的东西,比如内存模型,方法区和堆调优,其实从上文可以发现,JVM调优本质就是对方法区和堆内存的条用,因为类是自己编写,而内存的占用堆控制,而其余的本地方法栈,程序计数器其实我们并不能做太多的控制,当然堆外内存也是一块调优的重要部分。堆内存调优也就是GC,垃圾回收机制要有深的理解。我会在之后的文章,写写自己的理解和认知。最后,谢谢大家的阅读。