Apache Druid 平台化 - 数据接入篇
文章目录
- 数据接入
- 背景
- 方案设计
- druid 数据接入的一些经验
- 一. hive 数据导入自动填充分区
- 二. zstd 编码支持
- 三. keberos
- 四. druid-0.15.0 进程自动退出
- 五. 启动 supervisor 失败
- 六. druid 对数据进行 ETL
数据接入
背景
使用界面化和 sql 的方式将数据导入到 druid,提供数据给后续告警,监控,查询等服务使用。
方案设计
数据源1:内部消息服务 dclog ,本质上是一个 kafka topic,使用 record header 进行应用划分,可以抽象为单 Kafka topic 写多个 Druid datasource 的场景
数据源2:Kafka
数据源3:Hive
kafka 使用 kis 方式接入,hive 使用 hadoop batch ingestion 接入,这里主要是考虑消费 dclog 写入 druid 的三种方式:
| 方案 | 描述 | 优缺点 |
|---|---|---|
| KIS | 在 kafka indexing service 消费的时候对 header 进行 filter (需要修改源码在消费时增加 header filter 的功能),然后写入相应的 datasource。 参考 Druid 消费一个 kafka topic 发送到不同数据源 |
这种方式不需要额外的外部依赖,修改的源码也比较少,但是每个 task 都需要遍历相同 topic 的数据对其进行过滤,对 kafka 的压力比较大,同时每个 datasource 都需要一个 task。 |
| Spark SS + Tranquility | 使用 spark struct streaming 进行消费,(目前的 release 版本还不支持直接读取 kafka header,需要打入一个 patch Add support for Kafka headers in Structured Streaming),消费后直接通过http 的方式发送到 tranquility server,然后由 tranquility 写入相应的 datasource。 | task 由统一的 tranquility 负责,每次更新配置需要重新启动配置,该过程中可能会丢失数据,需要用 batch 任务进行 overwrite。 |
| Spark SS + KIS | 同样使用 spark SS 进行消费,将消费后的数据写入到对应的 kafka topic 中,使用 KIS 消费相应 topic 并将数据写入到对应的 datasource | 类似第一种,额外的一些区别是每个 kis 只需要访问相应的数据,但是需要对 topic 中的每种 header 建立一个新的 kafka topic。 |
出于控制 druid indexing task 和 kafka topic 数量的目的,最早的时候选择了方案二:

但在实际使用的一段过程中,发现诸多问题,例如:
- tranquility 从 druid 0.9 以后就停止更新,因此相关的 ingestion 相关功能缺失,例如 jq 解析,数值类型的维度列等。
- 提供的接口过于简单,很多状态无法获取,例如 kafka lag 等。
- 使用的 stream push 模型,任务异常终端会造成数据丢失,需要使用 hive 备份数据源进行回补。
- 超过时间窗口的数据会丢失。
- tranquility 配置更新需要重启服务。
此外同时维护两套代码逻辑不仅增加了系统复杂度,还大大增加了编码和维护的工作量。
后续改为方案三:
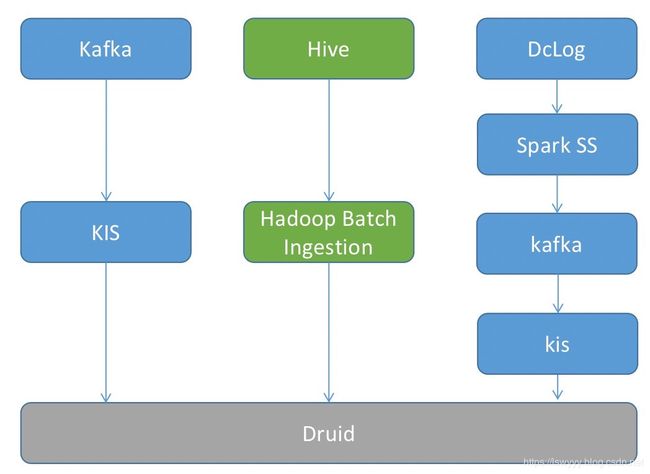
实际生成的 indexing task 和 kafka topic 数量其实并不多,不需要把这个因素作为选型的重要指标进行判断。
该方案数据消费的延时和配置更新的间隔对比第二种都有大幅度的减少,目前能做到1S内接入延时,1分钟内更新配置,且更新配置的过程中不会丢失数据。
druid 数据接入的一些经验
一. hive 数据导入自动填充分区
因为 hive 分区信息并不包含在真实数据中,可以使用 missing value 进行填充
// 该例子中的 ds 字段为分区字段,如果该字段在真实数据中不存在,就会以 2019-01-01 值进行填充
"timestampSpec": {
"column": "ds"
"format": "yyyyMMdd"
"missingValue": "2019-01-01"
}
二. zstd 编码支持
有部分 hive 表使用 zstd 压缩,所以需要 druid 支持相应的编码。
Add Codec for ZStandard Compression hadoop 在2.9版本提供了 zstd 的支持。
我们目前使用的版本为 hadoop2.6.0-cdh5.15.0,原生还不支持 zstd,需要打入相关补丁,重新编译获取 hadoop-common 后,将 druid 目录下的 hadoop-dependencies/hadoop-client/2.6.0-cdh5.15.0 / extensions/druid-hdfs-storage / extensions/druid-kerberos 中的 hadoop-common 包进行替换。
然后在 hadoop 导入作业中指定包含 zstd.so 的 hadoop_native 地址
"mapreduce.reduce.java.opts": "-Djava.library.path=/usr/install/libraries/hadoop_native"
"mapreduce.map.java.opts": "-Djava.library.path=/usr/install/libraries/hadoop_native"
三. keberos
historical 节点需要 kinit 登录,否则 historical 无法连接 hdfs
四. druid-0.15.0 进程自动退出
druid-0.15.0 以后提供了新的服务启动方式,例如 /bin/start-cluster-data-server,如果用 nohup 启动后没有使用 exit 命令退出终端,在终端断开时会被认为是异常终端,相应进程也会被关闭,日志信息如下:
[Fri Aug 16 18:36:22 2019] Sending signal[15] to command[broker] (timeout 360s).
[Fri Aug 16 18:36:22 2019] Sending signal[15] to command[coordinator-overlord] (timeout 360s).
[Fri Aug 16 18:36:22 2019] Sending signal[15] to command[router] (timeout 360s).
[Fri Aug 16 18:36:22 2019] Command[router] exited (pid = 37865, exited = 143)
[Fri Aug 16 18:36:23 2019] Command[broker] exited (pid = 37864, exited = 143)
[Fri Aug 16 18:36:23 2019] Exiting.
[Fri Aug 16 18:37:44 2019] Command[coordinator-overlord] exited (pid = 42773, exited = 143)
[Fri Aug 16 18:37:44 2019] Exiting.
五. 启动 supervisor 失败
启动 supervisor 时提示错误
"error": "Instantiation of [simple type, class io.druid.indexing.kafka.supervisor.KafkaSupervisorTuningConfig] value failed: Failed to create directory within 10000 attempts (tried 1508304116732-0 to 1508304116732-9999)"
overlord 节点 java.io.tmpdir 指定路径不存在导致。
六. druid 对数据进行 ETL
一些简单的 ETL 使用 ingestion 中的 transformSpec 中的 filter / transform 和 flattenSpec 就能解决,较为复杂的例如数据1对多等可以借助于 flink / spark SS 的计算能力。下面举3个
-
dimension 重命名
"dataSchema" : { "dimensionsSpec" : { "dimensions" : ["mb"] } } "transformSpec" : { "transforms" : [{ "type" : "expression", "name" : "mb", "expression" : "mobile" }] } -
从 seqId 中抽取前 13 位作为 timestampSpec 的时间戳
"flattenSpec": { "fields": [{ "expr": ".seqId[0:13]", "name": "ts", "type": "jq" }] }, "timestampSpec": { "column": "ts", "format": "auto" } -
一个相对复杂的判断
数据格式:将记录只有存在 event_type 为 a 的数据才接入 datasource,service_info 的值可能是一个 json 对象也可能是一个 json 数组
// record1 "service_info":[{"event_type","a"},{"event_type","b"}] // record2 "service_info":{"event_type","a"}ingestion 描述:
"flattenSpec": { "fields": [{ "expr": "[try .service_info[].event_type, try .service_info.event_type] | contains([\"a\"])", "name": "isA", "type": "jq" }] } "transformSpec": { "filter": { "type": "and", "fields": [{ "type": "selector", "dimension": "isA", "value": "true", "extractionFn": null }] }, "transforms": [] }