Shell工具(下)
今天我们继续学一些Shell的工具
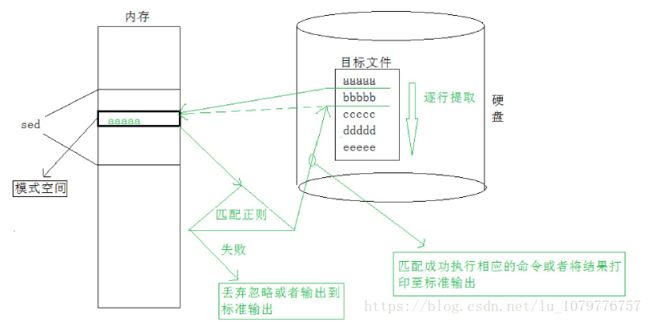
sed
sed是一种流编辑器,它是文本处理中非常重要的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,
把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,
处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,
除非你使用重定向存储输出。sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed默认安照Basic规范基本匹配!
命令格式:
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)常见的基本应用:
- /pattren/p:打印匹配pattern的行

使用p命令需要注意的是,sed是把待处理的文件的内容联通处理结果一起输出到标准输出中,因此p命令除了把源文件的所有内容打印出来,额外的还打印一遍匹配到pattern的行,要想只输出处理结果,那么我们应该加上一个选项 -n 。
- /pattern/d:删除所有匹配pattern的行

我们这时候再查看一下源文件的内容:

我们发现源文件的内容并没有做任何的改变,虽然sed命令删除了所有匹配到的内容,但是源文件的内容并没有做任何修改。因此我们可以知道sed 命令不会修改源文件的内容,删除命令只是表示某些行不打印输出,而不是从原文件中删除,如果要影响源文件,那我们就加上 -i 选项。我们现在来试试看:

- /pattern/s/pattern1/pattern2/ :查找符合pattern的行,将该行第一个匹配pattern1的字符串替换成pattern2。
使用sed,注释C代码当中的所有的printf。

- /pattern/s/pattern1/pattern2/ g:查找符合pattern的行,将该行第一个匹配pattern1的字符串替换成pattern2。

我们发现,这个选项和上一个很相似,只是在最后多加了一个g。那么我们实践了之后,很明显,我们发现它们之间还是有区别的,如果不加g,替换的则是替换第一个匹配到的内容,而加g则是替换匹配到的所有内容。


&是已匹配字符串标记,可以表示匹配pattern1之后的所有字符。
\(……\)用于匹配子串,对于匹配到的第一个子串就标记为\1,依此类推匹配到的第二个结果就是\2,我们通过对标签进行重组,从而完成数据逆置。
看例子:

- 定址
用于决定对哪些进行编辑。地址形式可以是数字,正则表达式,或者二者的结合。如果没有指定定址,那么sed将会处理输入文件的所有行。

- 退出状态:
sed和grep不太一样,它不想grep,不管是否找到指定的模式,它的退出状态都是0。只有当命令存在语法错误时,它的退出状态才不是0。
模式空间保持空间
sed在正常情况下,将处理的行读入模式空间(pattern space),脚本中的“sed-command(sed命令)”就一条接着一条进行处理,直到脚本执行完毕。然后该行被输出,模式(pattern space)被清空;接着,在重复执行刚才的动作,文件中的新的一行被读入,直到文件处理完毕。 一般情况下,数据的处理只使用模式空间(pattern space),按照如上的逻辑即可完成主要任务。但是某些时候,使用通过使用保持空间(hold space),还可以带来意想不到的效果。
- 模式空间(pattern space):可以想象成工程里面的流水线,数据直接在它上面进行处理。
- 保持空间(hold space):可以想象成仓库,我们在进行数据处理时,作为数据的暂存区域。正常情况下,如果不显示是用的某些高级命令,保持空间不会使用到!
sed的高级命令:
- g: 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
- G: 将hold space中的内容append(追加)到pattern space\n后
- h: 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
- H:将pattern space中的内容append到hold space\n后
- d: 删除pattern space中的所有行,并读入下一新行到pattern space中
- D: 删除multiline pattern中的第一行,不读入下一行
- x:交换保持空间(hold space)和模式空间(pattern space)的内容
- n:读取下一行到pattern space
- N:将下一行添加到pattern space中
1、给每一行结尾添加一行空行;

2、倒序输出

3、追加匹配行到行尾

4、删除匹配的内容,并追加到行尾

-e 选项允许在同一行例执行多条命令。
5、行列转换

6、打印奇偶行

7、1~100求和
法1:

![]()
法2:

:a 表示标签a,ba表示跳转到a标签,!表示不做后续的操作,所以!ba表示不做跳转,不跳转至标签a,结束此操作。
awk
sed以行为单位处理文件,awk比sed强的地方在于不仅能以行为单位还能以列为单位处理文件。awk缺省的行分隔符是换行,缺省的列分隔符是连续的空格和Tab,但是行分隔符和列分隔符都可以自定义,比如/etc/passwd文件的每一行有若干个字段,字段之间以 : 分隔,就可以重新定义awk的列分隔符为 : 并以列为单位处理这个文件。awk实际上是一门很复杂的脚本语言,还有像C语言一样的分支和循环结构,但是基本用法和sed类似,awk命令行的基本形式为 : awk option 'script' file1 file2 ... awk option -f scriptfile file1 file2 ... 和sed一样,awk处理的文件既可以由标准输入重定向得到,也可以当命令行参数传入,编辑命令可以直接当命令行参数传入,也可以用-f参数指定一个脚本文件,编辑命令的格式为:
/pattern/{actions}
condition{actions}其实,awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK的确拥有自己的语言: AWK 程序设计语言 ,三位创建者已将它正式定义为“样式扫描和处理语言”。
print命令

使用printf命令输出符合正则表达式的结果行,这里的 $0 代表输出整条记录, $1 输出指定的域(列)

当输入多个域时,print使用 “,”作为分隔符

根据条件进行输出

同样的awk还支持printf命令。

这里的printf命令和C语言几乎是一样的。我们之后可以在继续了解一下。
awk定制输入输出符
awk默认按照空格作为分隔符,如果想定制分隔符,常用的方法是使用-F 选项

我们发现用了-F选项,将分隔符设置为 : 这时输出的第一列就是hello
-F 也可以支持多种符号进行定制分隔符。举个例子来看一下:

可以用 -F 选项设置多个分隔符,在[ ]里设置多个。
BEGIN & END
BEGIN 和 END,是awk中两个具有特色的表达式,可以用他们作为文本处理之前的准备工作,之后的收尾工作,其基本格式如下:
BEGIN{} /REG/{} END{}
BEGIN{} condition{} END{}任何在BEGIN之后列出的操作(在{}内的)将在awk开始扫描输入之前执行,在END之后列出的操作将在awk扫描完全部的输入之后执行。因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果。
统计文本中,成绩合格的人数,这里awk中的变量,语法的使用要注意一下的。都是类C的。

awk脚本
awk除了上面的基本命令行的使用之外,还有awk脚本方式,其基本语法和命令行相同,语法也是类C的。
通过awk脚本,统计产品的档次,90以上为优;80~90为良;60~70为中;60以下为差。
现在我们来编写awk脚本语言:

这样,我们就编写了awk脚本,实现了产品的档次分类。
我们来看一下awk脚本语言是如何编写的:

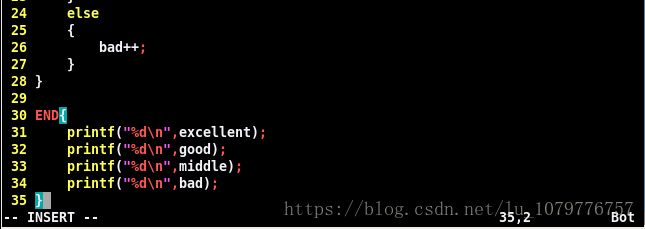
编写代码之前和shell脚本语言很相似,在前面加了
#!/usr/bin/awk -fFS = ":"即设置分隔符为 : ,和 -F 选项作用一样。
在执行前我们要修改一下权限,命令如下:
![]()
awk内置变量
上例中的,awk BEGIN{}中间有一个FS ,这个变量叫做awk的内置变量,类似于shell的内置变量。常见的内置变量有:
- ARGC: 命令行参数个数
- ENVIRON: 支持队列中系统环境变量的使用
- FILENAME: awk浏览的文件名
- FNR: 浏览文件的记录数
- FS: 设置输入域分隔符,等价于命令行 -F选项
- NF: 浏览记录的域的个数
- NR: 已读的记录数
- OFS: 输出域分隔符
- ORS: 输出记录分隔符
- RS: 控制记录分隔符
我们举几个例子:



其中NF表示字后一个域,而(NF-1)表示倒数第二个域,FS是定制输入分隔符的,OFS是定制输出分隔符的。
find
Linux下find命令在目录结构中搜索文件,并执行指定的操作。Linux下find命令提供了相当多的查找条件,功能很强大。由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。
find pathname -options [-print -exec -ok ……]用于查找文件树种查找文件,并作出相应的处理(可能访问磁盘)
- pathname : find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
- -print:find命令将匹配的文件输出到标准输出。其中 print 我们之前已经见过面了。
- -exec:find命令对匹配的文件执行该参数所给出的 shell 命令。相应命令的形式为'command' {} \;注意{}和\; 之间的空格。
- -ok:和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
- -name: 按照文件名查找文件。
- -perm: 按照文件权限来查找文件。
- -prune: 使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-
- prune将被find命令忽略。
- -depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
- -user: 按照文件属主来查找文件。
- -group: 按照文件所属的组来查找文件。
- -nogroup: 查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在
- -nouser: 查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在
- -newer file1 ! -newer file2: 查找更改时间比文件file1新但比文件file2旧的文件
- -type: 查找某一类型的文件,诸如:
- -b: 块设备文件。
- -d: 目录。
- -c: 字符设备文件。
- -p: 管道文件。
- -l: 符号链接文件。
- -f: 普通文件。
- -size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
查找系统中所有名为test.c的文件