oracle的sql优化
sql优化应该是基于对数据库优化器和执行计划的深入理解,明白sql语句从解析到执行中间的过程,以及优化器是如何选择某一执行路径作为最终的执行计划。
1. 什么是优化器
优化器是数据库中的一个核心子系统,优化器的目的就是按照一定的规则根据目标sql得到最佳的执行计划。oracle 10g以后默认的优化器是CBO,CBO是基于成本的优化器,mysql的优化器也是基于成本的优化器,成本值,即sql语句需要的io流,cup使用率,网络传输啊,以及相关的统计信息,更加这些统计信息选择成本最低的执行路径作为执行计划。如下图是oracle的sql执行流程。图片来自(基于Oracle的sql优化)

2.执行计划
为了执行sql语句,oracle会进行很多步骤,oracle用来执行目标sql语句的步骤的聚合就是执行计划。
如果使用plsql我们可以很轻松的执行计划,打开plsql按下F5,我们可以看到执行目标sql内部具体的步骤,操作名,谓词信息,列信息,cbo评估出来的结果(即受影响的行),cpu消耗,运行时间等。
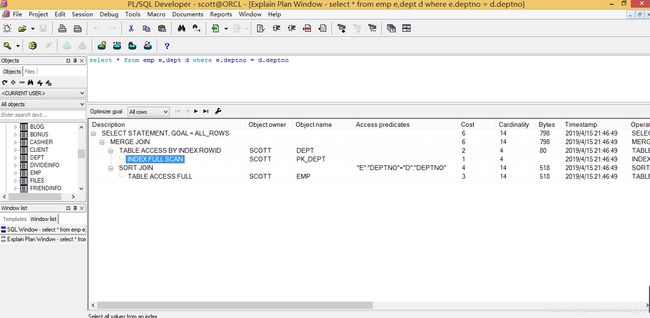
其实plsql也是封装了底层的explain plan 命令。
打开我们的sqlplus
输入explain for + sql语句,执行之后,oracle会将产生的执行计划存入PLAN_TABLE$表中,
执行select * from table(dbms_xplan.display);
会将执行计划格式化展现处理,执行计划只在当前session中可见。各各session相互无法干扰。
AUTOTRACE开关
sqlpus中的AUTOTRACE开关默认是关闭的,AUTOTRACE打开,我们不仅能查出sql的执行结果,而且能得到执行计划和sql执行所消耗的资源,如物理读,逻辑读,产生的redo的数量等。
SET AUTOTRACE {OFF|ON|TRANCEONLY}
执行计划执行的顺序,对不并列的列,最右的先执行,对于并列的列,上面的先执行。
2.1 表连接方式
oracle常用的表连接方式有排序合并连接,嵌套循环连接,哈希连接。
**排序合并连接:**假定有表t1,t2。
1.sql语句带上谓词条件访问t1,并排序,得到结果集c1。
2.sql语句带上谓词条件访问t2,并排序,得到结果集c2。
3.最后将2个结果集根据条件进行合并,具体过程如下,依次取c1结果集的数据,然后按照连接条件匹配c2结果集,如果找到则删除或记录下c2结果集数据的位置,找到所有结果后返回,继续c1的下一条记录,直到完成所有匹配。
排序合并连接效率远不如哈希连接,但是hash连接适用于等值连接,而排序合并还可以用于非等值连接。
**嵌套循环连接:**2个表在做连接时依靠2层嵌套循环分别为外循环和内循环得到结果集的连接方式。
1.优化器会决定t1,t2谁是驱动表,驱动表作为外层循环,非驱动表作为内层循环,这里假设t1是驱动表。t1带上谓词条件过滤得到c1结果集,然后依次取c1中的记录去匹配c2结果集的记录,c1有多少条记录,c2就会被循环匹配多少次。所以称为嵌套循环连接。嵌套循环可以第一时间返回已经完成的结果,这是其他连接所不具备的。
**哈希连接:**利用hash运算来得到连接后的结果集,适用于大表连小表。小表过滤后的结果集记为c1,t1会作为驱动表,toracle会构造一个hashtable,一个hash table由许多个hash partition组成,一个hash partition又由很多个hash bucket组成,oracle内置了2个hash函数,我们简称为hash_fun1(),hash_fun2(),这个hash函数会对c1结果集中的每条记录,做hash运算,得到的结果我们称为hash_fun1_value,hash_fun2_value,根据hashf1_value找到对应hash bucket,同时将hashf2_value存入其中,hashf2_value具体连接信息(可以类比java的hashmap的实现)用来后续区别唯一的。oracle还会为每个hash partition构建一个位图来判断每一个hash bucket是否有记录。(如果数据量比较大时,oracle会把填满了的hash分区存到磁盘上去),被驱动表t2根据谓词过滤得到c2结果集,针对每条数据采用同样的hash算法,去和已经存在的hash bucket匹配。直到处理完所有的数据。hash连接效率比较高的情况下,消耗的时间相当于全表扫描大表的时间。
3.优化的方法
1.查询尽量避免全表扫描,数据量大时,应当考虑在连接列和where条件后的某些列建立索引。
2.对where条件 的列 做null 判断,算术符运算,使用 like ‘%test%’ 做模糊查询时,以%为头,进行函数操作都将导致不走索引查询。
3 尽量避免使用in 或not in 将导致不走索引,可以用 between 或 exist 代替。
4 避免select * 的查询 ,不要返回不需要用到的字段。
5.union all 代替union 如何结果集允许重复的话。
6使用预绑定,减少sql的硬解析,充分的利用缓存。
7.order by 的列和join的列尽量索引。
8.用join 连接查询来代替嵌套子查询,因为子查询会生成一张临时表。
9 在表设计时适当的冗余字段,查询减少表的连接。
10 分库分表
总结
很多人以为sql优化就是加索引,这是很肤浅的认识,如果一个表的数据量很大有1000万,加了某个索引,查询出的数据有900万,那么走索引查询还不如走全表扫描,索引查了到数据位置后,还要回表查一次,如果加索引查出的数据占总数很大比重,那么使用索引查询反而会使效率降低。而且比如oracle全表扫描采用多块读,有时候效率反而高于索引查询,只是全表扫描在数据增长之后,其效率会降低的很快,极不稳定。索引查询只是sql优化的一种手段,sql优化的核心还是应当深入的理解优化器和执行计划。