盘点Elasticsearch中的查询套路
引言
Elasticsearch作为一款比较火的分布式的全文搜索索引,里面的查询方式比较多,也比较细。ElasticSearch中的查询语句嵌套的都很灵活,基于RESTful风格,以json的方式拼接。如果有学习过MongoDB的同学,学这个应该比较轻松。本文简单理了一下ES中的查询套路,并附上一些总结。
文章导读
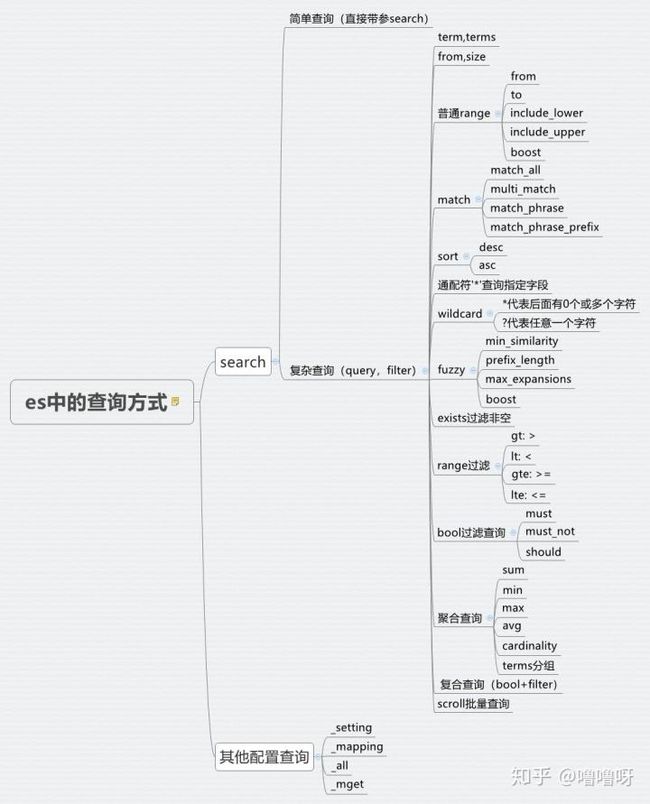
ElasticSearch的查询操作
一、数据准备
创建索引 lib6,指定主分片与副本数量,就用默认的好了。然后自定义映射,设置数据类型,是否分词。
我使用的是ik的中文分词器,分两种:
ik_max_word:会将文本做最细粒度的查分,尽可能多的拆分出词语
ik_smart:会做最粗粒度的拆分,已被分出的词语将不再被其他词语占有
在favor中指定了ik_max_word分词器,很简单就完事了。
PUT lib6
{
"settings": {
"number_of_shards": 5
, "number_of_replicas": 1
},
"mapings":{
"user":{
"properties":{
"name":{"type":"text"},
"age":{"type":"text","index":false},
"bitrhday":{"type":"date","index":false},
"address":{
"properties":{
"province":{
"type":"keyword"
},
"city":{
"type":"keyword"
}
}
},
"favor":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
}使用bulk批量导入,就导5个用户吧。
POST /lib6/user/_bulk
{"index":{"_id":1}}
{"name":"赵爱花","age":55,"birthday":"1964-01-01","address":{"province":"zhejiang","city":"taizhou"},"favor":"drinking,singing,swimming"}
{"index":{"_id":2}}
{"name":"牛二妞","age":12,"birthday":"2007-01-01","address":{"province":"heilongjiang","city":"harbin"},"favor":"singing,swimming"}
{"index":{"_id":3}}
{"name":"马冬梅","age":20,"birthday":"1999-01-01","address":{"province":"jiangsu","city":"suzhou"},"favor":"swimming,singing"}
{"index":{"_id":4}}
{"name":"王春丽","age":25,"birthday":"1994-01-01","address":{"province":"guangdong"},"favor":"drinking"}
{"index":{"_id":5}}
{"name":"噜噜","age":22,"birthday":"1997-01-01","address":{"province":"beijing"},"favor":"swimming"}二、其他配置查询
GET _all/_settings
查看所有索引的配置。
GET /lib6/_settings
查看索引的配置。
GET /lib6/_mapping
查看索引的配置。
GET /lib6/user/1?_source=age,favor
查看id=1用户的age,favor。
GET /lib6/user/_mget{"ids":["1","2"]}
指定id,批量读取对应id的用户。
GET /_mget
{
"docs" : [
{
"_index" : "lib6",
"_id" : "1"
},
{
"_index" : "lib6",
"_id" : "2"
}
]
}可以指定type,也可以不指定。因为6.0版本以后一个索引下只能有一种类型。查询结果与上一个一致。
三、基于search的简单查询
es中绝大部分的查询都是通过_search的。
GET /lib6/user/_search?q=name:噜噜
查看name=噜噜的所有用户
GET /lib6/user/_search?q=name:马冬梅&sort=age:desc
查看所有name=噜噜的用户并且结果按年龄排序
四、基于search的复杂查询(核心)
简单说下query和filter。query默认是会计算相关度分数的,可以嵌套filter,但必须设置为constant_score。filter单独使用时可以用post_filter。filter查询是不计算相关性的(也就是不计算max_score),一些filter还能缓存。因此filter的速度要快于query。
以下过滤器默认不缓存:
numeric_range,script,geo_bbox,geo_distance,geo_distance_range,geo_polygon,geo_shape,and,or,not
而exists,missing,range,term,terms默认是开启缓存的!
4.1 term,terms查询
GET /lib6/user/_search
{
"query":{
"term":{"name":"噜"}
}
}返回所有name中有"噜"的用户。
GET /lib6/user/_search
{
"query":{
"terms":{
"favor":["drinking","singing"]
}
}
}返回所有favor中有drinking或singing的用户,按照查询相关度排序。
4.2 from,size查询
from:从查询结果的第几个文档开始。
to:本次共查几个用户。
GET /lib6/user/_search
{
"from":0,
"size":2,
"query":{
"terms":{
"favor":["drinking","singing"]
}
}
}查询favor中有drinking或singing的用户,在结果集中取前两个返回。
4.3 普通range查询
from,to,include_lower,include_upper,boost
include_lower:是否包含范围的左边界,默认是true
include_upper:是否包含范围的右边界,默认是true
boost:权重,会影响查询分数
GET /lib6/user/_search
{
"query":{
"range":{
"age":{
"from":20,
"to":25,
"include_lower":true,
"include_upper":false
}
}
}
}查20<=年龄<25的所有用户。
4.4 match查询
4.4.1 match_all查询
GET /lib6/user/_search
{
"query":{
"match_all":{}
}
}查询lib6索引下全部文档。
4.4.2 multi_match查询
使用multi_match可以指定多个字段查询。
GET lib6/user/_search
{
"query":{
"multi_match":{
"query":"swimming",
"fields":["name","favor"]
}
}
}精准查询,查找name或favor属性中有swimming的用户。
4.4.3 match_phrase查询
短语匹配查询,es引擎会先分析查询字符串,从分析后的文本中构建短语查询,必须匹配短语中的所有分词,并且保证各个分词的相对位置不变。
GET lib6/user/_search
{
"query":{
"match_phrase":{
"favor":"swimming,singing"
}
}
}返回favor属性有swimming,singing并且顺序不可变。
4.4.4 match_phrase_prefix查询
前缀匹配查询
GET /lib6/user/_search
{
"query":{
"match_phrase_prefix":{
"name":{
"query":"噜"
}
}
}
}返回所有name以"噜"开头的用户。
4.5 sort查询
desc:降序
asc:升序
GET /lib6/user/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"age":{"order":"asc"}
}
]
}将所有用户按照年龄升序排序。
4.6 使用通配符查询指定字段
* 表示后面有0个或n个字符,这种方式只能使用*。
GET /lib6/user/_search
{
"_source":{
"includes":"add*",
"excludes":["name","ag*"]
},
"query":{
"match_all":{}
}
}查询所有用户中,add开头的属性。当includes与excludes在一起时,excludes不生效,只看includes。所以结果中就没有favor。
4.7 wildcard查询
允许使用通配符* 和 ?来进行查询
*代表后面有0个或多个字符
?代表任意一个字符
GET /lib6/user/_search
{
"query":{
"wildcard":{
"name":"噜*"
}
}
}返回name中以"噜"开头的所用用户。
4.8 fuzzy模糊查询
boost:查询的权值,默认值是1.0。
min_similarity:设置匹配的最小相似度,默认值为0.5,对于字符串,取值为0-1(包括0和1);对于数值,取值可能大于1;对于日期型取值为1d,1m等,1d就代表1天。
prefix_length:指明区分词项的共同前缀长度,默认是0。
max_expansions:查询中的词项可以扩展的数目,默认可以无限大。
GET /lib6/user/_search
{
"query":{
"fuzzy":{
"favor":"swimmi"
}
}
}查询所有favor中出现过swimmi的用户。这个和相关度分数有关,低于它默认的就查不到了。
4.9 filter查询
在过滤后留下符合设定条件的字段。
GET /lib6/user/_search
{
"post_filter": {
"terms": {
"age": [25,40]
}
}
}查询25<=age<=40的所有用户。
4.10 exists查询
可以与filter一起,过滤非空查询。
如果把外面那一层constant_score去掉,会报异常。这也从侧面说明了,可以把filter理解为不计算查询相关度的query。
GET /lib6/user/_search
{
"query":{
"constant_score":{
"filter":{
"exists":{"field":"address"}
}
}
}
}返回所有address字段存在的用户。
4.11 range过滤查询
gt: >
lt: <
gte: >=
lte: <=
GET /lib6/user/_search
{
"post_filter": {
"range": {
"age": {
"gt": 25,
"lt": 50
}
}
}
}查找25<年龄<50的用户。
4.12 bool过滤查询
must:必须满足的条件---and
should:可以满足也可以不满足的条件--or
must_not:不需要满足的条件--not
GET lib6/user/_search
{
"query":{
"bool":{
"must":{
"match":{"favor":"swimming"}
},
"must_not":{
"match":{"age": 55 }
},
"should":{
"range":{
"birthday":{
"lte":"2000-01-01"
}
}
}
}
}
}查询favor中有swimming且age不为55,或出生时间在2000-01-01之前的所有用户。
4.13 聚合查询
sum,min,max,avg,cardinality(求基数,不重复的值的数量),terms(分组)。
使用上都是差不多的,这里就列举sum和terms。
GET /lib6/user/_search
{
"size":0,
"aggs":{
#这个名字自己取
"age_of_sum":{
"sum":{
"field":"age"
}
}
}
}计算所有用户年龄和,不返回用户。
- terms分组
我们来看一个复杂的查询,将favor有swimming的用户按年龄分组,并求年龄的平均值,结果按平均年龄升序排列。
GET /lib6/user/_search
{
"size":0,
"query":{
"match":{
"favor":"swimming"
}
},
"aggs":{
"age_of_group":{
"terms":{
"field":"age",
"order":{
"age_of_avg":"asc"
}
},
"aggs":{
"age_of_avg":{
"avg":{
"field":"age"
}
}
}
}
}
}4.14 复合查询(bool+filter)
将多个基本查询组合成单一查询的查询,实质上是使用bool,filter查询。
GET lib6/user/_search
{
"query":{
"bool":{
"must":{
"match":{"favor":"swimming"}
},
"must_not":{
"match":{"age": 55 }
},
"should":{
"range":{
"birthday":{
"lte":"2000-01-01"
}
}
},
"filter":{
"range":{
"birthday":{
"lte":"1999-01-01"
}
}
}
}
}
}就是在上面的terms分组查询的基础上过滤后剩下birthday早于1999-01-01的用户。
4.15 scroll批量查询
在搜索大量数据时,可以用scroll技术滚动搜索。如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完为止。
GET /lib6/user/_search?scroll=1m
{
"query":{
"match_all":{}
},
"size":2
}一次查两个用户,一分钟内查出来。如果要进行下一次查询,需要在上一次结果中获取_scroll_id作为参数传入后查询。
总结
es的查询语言真不知道选哪个呀,就选了个JSON,求大佬告知......
过完一遍,加深理解,算是入门了吧。学的时候感觉挺乱的,学完之后一定要总结。
文章若有不当之处,欢迎评论指出~
如果喜欢我的文章,欢迎关注知乎专栏Java修仙道路~