http编程系列(二)——java爬虫实现刷个人博客的访问量
实现功能
这里实现的功能是一个根据个人博客主页,搜索出所有的个人博文链接,然后一个一个去访问,从而增加访问量。这里我发现一个问题,csdn既没有做接口ip访问量的限制,访问量统计时也没有做同一ip相同时间段的重复访问重复计数的处理。这也时这个程序能够刷访问量的原因。
思路
进入个人博客主页,如我的博客:”http://blog.csdn.net/luo4105”,它会出来一个博客的列表(blogListPage),但是,它没有显示所有的博客,而是分页显示,这里我们就找到下一页
的链接并访问它,然后如此递归,直到尾页为止。这样我们就获得了所有的分页博客的地址。然后访问所有的分页博客,拿到它们的页面数据,找出所有的博客链接,访问。
这里工作就分为以下几步
1.根据个人主页url,访问个人主页并拿到页面数据
2.找出下一页的URL并访问,重复该动作直到没有下一页,将每个url都存到set集合中
3.遍历set集合,访问所有的博客列表页面,获得页面数据,找到页面数据中所有的博客链接,存入博客链接的set集合
4.遍历博客链接的set集合,访问所有博客链接
具体实现步骤
1.根据个人主页url,访问个人主页并拿到页面数据
访问url,并拿到响应的代码如下,为了重复使用,我将其放入工具类中。
访问URL并拿到响应代码
public class HttpUtil {
public static InputStream doGet(String urlstr) throws IOException {
URL url= new URL(urlstr);
HttpURLConnection conn= (HttpURLConnection) url.openConnection();
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
InputStream inputStream= conn.getInputStream();
return inputStream;
}
}public class StreamUtil {
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}
}综合使用就是
public void addBlogListPageUrl(String pageUrl, Set pagelistUrls) throws IOException {
InputStream is = HttpUtil.doGet(pageUrl);
String pageStr = StreamUtil.inputStreamToString(is, "UTF-8");
is.close();
System.out.println(pageStr);
} 2.找出下一页的URL并访问,重复该动作直到没有下一页,将每个url都存到set集合中
开启f12,我们来看下一页是怎么样的。
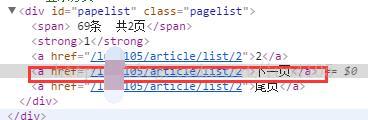
这里我们可以通过下面的正则匹配
private String nextPagePanner = "下一页"; //下一页的正则表达式private String nextPageUrlPanner = "/luo4105/article/list/[0-9]{1,10}"; //下一页Url的正则表达式private String csdnBlogUrl = "http://blog.csdn.net/";
private String nextPagePanner = "下一页"; //下一页的正则表达式
private String nextPageUrlPanner = "/luo4105/article/list/[0-9]{1,10}"; //下一页Url的正则表达式
/**
* 通过下一页,遍历所有博客目录页面链接
* @param pageUrl
* @param pagelistUrls
* @throws IOException
*/
public void addBlogListPageUrl(String pageUrl, Set pagelistUrls) throws IOException {
InputStream is = HttpUtil.doGet(pageUrl);
String pageStr = StreamUtil.inputStreamToString(is, "UTF-8");
is.close();
Pattern nextPagePattern = Pattern.compile(nextPagePanner);
Matcher nextPagematcher = nextPagePattern.matcher(pageStr);
if (nextPagematcher.find()) {
nextPagePattern = Pattern.compile(nextPageUrlPanner);
nextPagematcher = nextPagePattern.matcher(nextPagematcher.group(0));
if (nextPagematcher.find()) {
pagelistUrls.add(csdnBlogUrl + nextPagematcher.group(0));
System.out.println("成功添加博客列表页面地址:" + csdnBlogUrl + nextPagematcher.group(0));
//addBlogListPageUrl(csdnBlogUrl + nextPagematcher.group(0), pagelistUrls);这是调用添加blog链接的方法
}
}
} 3.遍历set集合,访问所有的博客列表页面,获得页面数据,找到页面数据中所有的博客链接,存入博客链接的set集合
我们先看看再blog列表页面中的blog链接
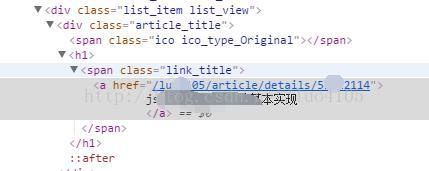
匹配/luo4105/art......的正则如下
private String artlUrl = "/luo4105/article/details/[0-9]{8,8}"; //博客utl的正则表达式private String artlUrl = "/luo4105/article/details/[0-9]{8,8}"; //博客utl的正则表达式
/**
* 添加搜索博客目录的博客链接
* @param blogListURL 博客目录地址
* @param artlUrls 存放博客访问地址的集合
* @throws IOException
*/
public void addBlogUrl(String blogListURL, Set artlUrls) throws IOException {
InputStream is = HttpUtil.doGet(blogListURL);
String pageStr = StreamUtil.inputStreamToString(is, "UTF-8");
is.close();
Pattern pattern = Pattern.compile(artlUrl);
Matcher matcher = pattern.matcher(pageStr);
while (matcher.find()) {
String e = matcher.group(0);
System.out.println("成功添加博客地址:" + e);
artlUrls.add(e);
}
} 代码如下
@Test
public void visitBlog() throws IOException {
addBlogUrl();
/** 这里可以写循环 **/
for(String blogUrl : blogUrls) {
String artlUrl = csdnBlogUrl + blogUrl;
InputStream is = HttpUtil.doGet(artlUrl);
if (is != null) {
System.out.println(artlUrl + "访问成功");
}
is.close();
}
/** 这里可以写循环 **/
}访问URL并拿到响应工具类
public class HttpUtil {
public static InputStream doGet(String urlstr) throws IOException {
URL url= new URL(urlstr);
HttpURLConnection conn= (HttpURLConnection) url.openConnection();
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
InputStream inputStream= conn.getInputStream();
return inputStream;
}
}public class StreamUtil {
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}
}/**
* @author 逝夕诚
* 刷csdn博客访问量
*/
public class AddCsdnBlogPV {
private String csdnBlogUrl = "http://blog.csdn.net/";
private String firstBlogListPageUrl = "http://blog.csdn.net/luo4105"; //博客主页
private String nextPagePanner = "下一页"; //下一页的正则表达式
private String nextPageUrlPanner = "/luo4105/article/list/[0-9]{1,10}"; //下一页Url的正则表达式
private String artlUrl = "/luo4105/article/details/[0-9]{8,8}"; //博客utl的正则表达式
private Set blogListPageUrls = new TreeSet<>();
private Set blogUrls = new TreeSet<>();
@Test
public void visitBlog() throws IOException {
addBlogUrl();
for(String blogUrl : blogUrls) {
String artlUrl = csdnBlogUrl + blogUrl;
InputStream is = HttpUtil.doGet(artlUrl);
if (is != null) {
System.out.println(artlUrl + "访问成功");
}
is.close();
}
}
/**
* @throws IOException
* 加载所有的bolg地址
*/
@Test
public void addBlogUrl() throws IOException {
blogListPageUrls.add(firstBlogListPageUrl);
addBlogListPageUrl(firstBlogListPageUrl, blogListPageUrls);
for (String bolgListUrl : blogListPageUrls) {
addBlogUrl(bolgListUrl, blogUrls);
}
}
/**
* 通过下一页,遍历所有博客目录页面链接
* @param pageUrl
* @param pagelistUrls
* @throws IOException
*/
public void addBlogListPageUrl(String pageUrl, Set pagelistUrls) throws IOException {
InputStream is = HttpUtil.doGet(pageUrl);
String pageStr = StreamUtil.inputStreamToString(is, "UTF-8");
is.close();
Pattern nextPagePattern = Pattern.compile(nextPagePanner);
Matcher nextPagematcher = nextPagePattern.matcher(pageStr);
if (nextPagematcher.find()) {
nextPagePattern = Pattern.compile(nextPageUrlPanner);
nextPagematcher = nextPagePattern.matcher(nextPagematcher.group(0));
if (nextPagematcher.find()) {
pagelistUrls.add(csdnBlogUrl + nextPagematcher.group(0));
System.out.println("成功添加博客列表页面地址:" + csdnBlogUrl + nextPagematcher.group(0));
addBlogListPageUrl(csdnBlogUrl + nextPagematcher.group(0), pagelistUrls);
}
}
}
/**
* 添加搜索博客目录的博客链接
* @param blogListURL 博客目录地址
* @param artlUrls 存放博客访问地址的集合
* @throws IOException
*/
public void addBlogUrl(String blogListURL, Set artlUrls) throws IOException {
InputStream is = HttpUtil.doGet(blogListURL);
String pageStr = StreamUtil.inputStreamToString(is, "UTF-8");
is.close();
Pattern pattern = Pattern.compile(artlUrl);
Matcher matcher = pattern.matcher(pageStr);
while (matcher.find()) {
String e = matcher.group(0);
System.out.println("成功添加博客地址:" + e);
artlUrls.add(e);
}
}
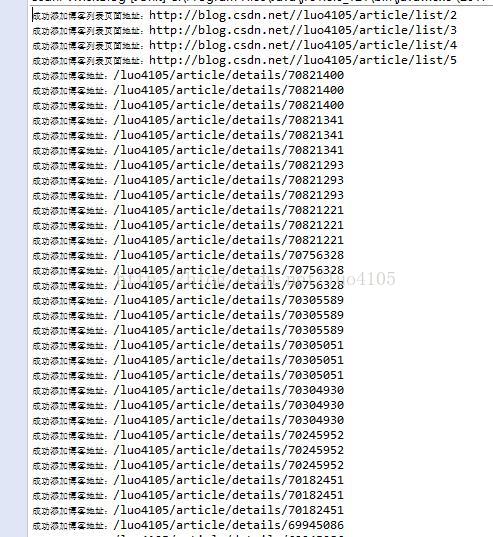
} 
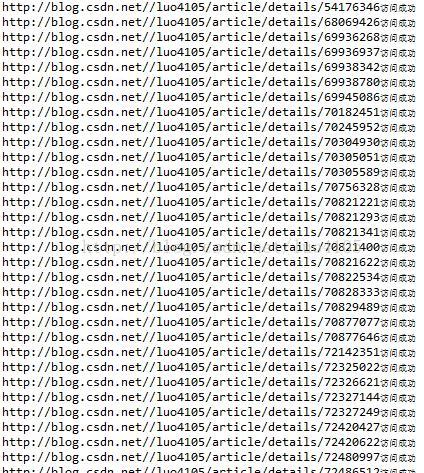
结语
功能实现主要技术点是
1.java http的请求、响应。
2.正则的匹配。
今天是星期六又是520,我又孤独的坐在宝安图书馆三楼期刊后面的角落,又默默的写着这无聊到蛋疼的程序、以及教别人如何写这无聊到蛋疼的博客,念及此不觉潸然泪下。
代码地址:https://code.csdn.net/luo4105/study_http/tree/history/src/main/java/com/lc/https/AddCsdnBlogPV.java