Convolutional Neural Network For Sentence Classification(CNN情感分析yoom例子一)
转自http://blog.csdn.net/lyy14011305/article/details/72811140
用卷积神经网络对句子分类
Yoon Kim
纽约大学
[email protected]
摘要
针对句子级别的分类任务,我们使用卷积神经网络(CNN)结合预训练的词向量做了一系列的实验。我们证明一个少量调节超参数的简单CNN模型结合静态词向量可以在很多基准上取得非常好的结果。通过细粒度的调节参数学习特定任务的词向量可以进一步的提升结果。我们提出了对架构简单的修改,这样可以同时使用基于特定任务和静态的词向量。此处讨论的CNN模型在7个任务的4个当中取得目前最好的结果,包括情感分类和问题分类。
1.介绍
深度学习模型在计算机视觉(Krizhevskv et al., 2012)和语音识别(Graves et al., 2013)两大领域已经取得了显著的结果。在自然语言处理领域,基于深度学习模型的大量工作已经涉及通过神经语言模型(Bengio et al., 2003; Yih et al., 2011; Mikolov et al., 2013)学习词向量的表示和在训练好的词向量上组合特征用于分类任务(Collobert et al., 2011)。词向量,此处单词从一个稀疏、V(这里V是所有词的总数)维的编码通过一个隐藏层映射到一个低维的向量空间,这对将单词的语义特征编码到词向量中的特征抽取器来说非常重要。在这样稠密的表示中,语义相近的单词在低维空间中的欧式距离或余弦距离也会同样相近。
卷积神经网络(CNN)利用可以提取局部特征(Lecun et al., 1998)的卷积层。起初设计用来计算机视觉的CNN模型已经逐渐被证明在NLP领域内同样有效,并且在语义分析(Yin et al., 2014),搜索查询检索(Shen et al., 2014),句子模型(Kalchbrenner et al., 2014), 和其它NLP(Collobert et al., 2011)任务上已经取得了相当好的结果。
在这篇论文中,我们在通过非监督神经语言模型训练的词向量上训练一个只有一个卷积层的CNN。这些词向量是Mikolov et al.(2013)在10亿Google 新闻数据上训练出来的并且是公用的。我们开始是保持这些词向量不变仅改变模型的其它参数。尽管调节少量的参数,该简单的模型就在很多基准上达到了非常好的结果,这说明预训练的词向量是“通用的”特征抽取器,可以被应用在很多分类任务上。通过细粒度的调节训练的针对特定任务的词向量可以进一步提升结果。我们最终对架构做了简单的修改,借助多个通道可以同时使用预训练的词向量和特定任务的词向量。
我们的工作从哲学的角度上很像Razavian et al. (2014)的工作,其证明对于图像分类,通过预训练的深度神经学习模型设计的特征抽取器在很对任务上都表现的很好,包括很多和原始任务不同的任务。
2.模型 
图1:处理一个句子的两个通道的模型架构
模型的架构,如图1所示,是Collobert et al. (2011)CNN架构的微小变形。让x_i∈R^k表示句子中第i个词的k维词向量。一个包含n个单词的句子(必要的时候可以填充)可以表示成:
x_(1:n)=x_1⊕x_2⊕…⊕x_n (1)
这里⊕表示拼接操作。一般来说让x_(i ∶ i+j)表示单词x_i,x_(i+1),…,x_(i+j)的拼接。一个卷积操作涉及一个滤波器w∈R^hk,应用在一个h个单词的窗口产生一个新的特征。例如,特征c_i是对单词窗口x_(i∶ i+h-1)应用如下公式产生的:
c_i=f(w∙x_(i∶ i+h-1)+b) (2)
这里b∈R是偏置项,f是一个非线性函数如双曲正切函数。该滤波器应用在句子中{x_(1∶ h ), x_(2∶h+1),…,x_(n+h-1∶n) }每一个可能的单词窗口产生一个特征映射:
c=[c_1,c_2,…,c_(n+h-1) ](3)
这里c∈R^(n-h+1)。然后我们对特征映射采用最大池化策略(Collobert et al., 2011)即取最大的值c ̂=max{c}作为对应此滤波器的特征。此思路是去捕获最重要的特征——每个特征映射中最大的值。最大池化可以自然处理不同的句子长度。
我们已经描述通过一个滤波器抽取一个特征描述这个过程。使用多个滤波器(不同的窗口大小)的模型可以获取多个特征。这些特征组成了倒数第二层并且传给全连接的softmax层,输出标签的概率分布。
在其中一个模型变种中,我们做了将词向量分两个“通道”的实验,一个通道中的词向量在模型训练的过程中保持不变,另一个通过BP算法(3.2节)进行细粒度的调节。在多通道架构中,如图1所示,每个滤波器应用在两个通道,结果被加起来用等式(2)计算c_i。否则模型等价于单通道的架构。
2.1 正则化
对于正则化,在倒数第二层我们采用dropout策略并且限制权重向量(Hinton et al., 2012)的二范式大小。Dropout通过随机丢弃——例如在前向传播的过程中,每个隐层单元有p的概率被丢弃,从而防止隐层单元的共适应问题。即,给定倒数第二层z=[(c_1 ) ̂,…,(c_m ) ̂ ](指出我们有m个滤波器),不是使用:
y=w∙z+b (4)
在前向传播中对输出单元y,dropout使用:
y=w∙(z ○r)+b (5)
这里○是元素级的乘法操作并且r∈R^m是一个“掩盖”向量,向量中的元素都是一个伯努利随机变量有p的概率变为1。梯度仅仅可以通过非掩盖的单元反向传播。在测试阶段,权重向量通过因子p缩减例如w ̂=pw,并且w ̂被用来(没有使用dropout)给看不见的句子打分。我们另外限制权重向量的二范式,在每一步梯度下降之后,如果‖w‖_2>s,重新将w的二范式设置为‖w‖_2=s。
3.数据集和实验步骤 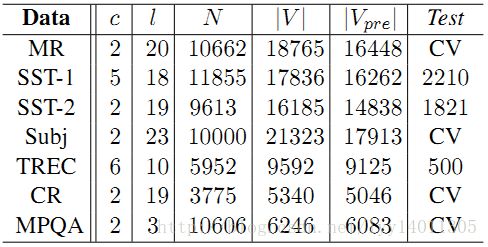
表1:分词之后的数据集的简要统计。C:目标类的个数。l:平均句子长度。N:数据集大小。|V|:单词总数。|V_pre |:出现在预训练词向量中词的个数。Test:测试集的大小(CV意味没有标准的训练/测试集并且采用十折交叉验证的方法)
我们在不同的基准上测试我们的模型。数据集的简要统计如表1所示。
- MR: 一句话的电影评论。分类涉及检测积极/消极的评论(Pang and Lee, 2005)。
- SST-1:斯坦福情感树库——MR数据的扩展,但是包含train/dev/test数据集的划分及细粒度的标签(非常积极、积极、中立、消极、非常消极),被Socher et al.(2013)重新标记。
- SST-2: 和SST-1一样,但是没有中立的评论,只有积极和消极两种标签。
- Subj:主观数据集,任务是去划分一个句子是主观性的还是客观性的(Pang and Lee. 2004)。
- TREC:TREC问题数据集——任务设计到将一个问题划分为六种问题类型(人,位置,数值信息等)(Li and Roth, 2002)。
- CR:不同产品(照相机、MP3s等等)的客户评论。任务是预测积极/消极的评论(Hu and Liu, 2004)。
- MPQA:MPQA数据集(Wiebe et al., 2005)的观点极性检测子任务。
3.1 超参数和训练过程
对于所有的数据集,我们使用:矫正线性单元,3, 4, 5三种卷积窗口(h),每种卷积窗口100个特征映射,0.5的dropout比例(p),二范式约束为3,mini-batch大小为50。这些值在SST-2 验证数据集上通过网格搜索选择。
我们除了在验证集上早停外没有另外进行任何特定数据集的调节。对于没有标准验证集的数据集,我们从训练数据集中随机选择10%的数据作为验证集。通过采用Adadelta更新规则(Zeiler, 2012)及随机mini-batches策略的随机梯度下降算法进行训练。
3.2 预训练的词向量
在没有大量监督训练集(Colobert et al., 2011; Socher et al., 2011; Iyyer et al., 2014)的情况下,使用从非监督神经语言模型训练得到的词向量进行初始化是用来提升结果的普遍方法。我们使用公用的、下哦那个10亿Google 新闻数据中训练出来的Word2vec词向量。此向量的维度是300并且是采用连续的词袋架构(Mikolov et al., 2013)训练出来的。没有出现在预训练词向量中的单词随机初始化。
3.3 模型变种
我们使用以下模型变种进行实验。
- CNN-rand:我们的基准模型,所有的词被随机初始化,并在训练的工程中进行调节。
- CNN-static:使用预训练的词向量——Word2vec。所有的词——包括随机初始化的未出现在预训练词向量中的词——保持不变仅仅调节模型其它的参数。
- CNN-non-static:和CNN-static相似,但是预训练的词向量在每个任务中被细粒度的调节。
- CNN-multichannel:有两个词向量集合的模型。将每个向量集合看作一个“通道”并且每个滤波器应用在所有的通道,但是梯度只能通过其中一个通道进行反向传播。因此,模型能够细粒度的调节其中一个向量集合,而保持另外一个不变。
为了探究上述变种对其它随机因子的影响,我们消除其它随机化的根源——交叉验证次数赋值,未知词向量的初始化,CNN模型参数的初始化——在每个数据集上保持一致。
4.结果和讨论 
表2:CNN模型和其它结果的对比
我们模型和其它模型的结果对比被列在表2中。我们随机化所有词向量的基准模型(CNN-rand)就其本省而言表现的不是很好。然而我们期望通过预训练的词向量来提升效果的模型,我们对效果提升的幅度感到很吃惊。即使使用静态向量的简单模型(CNN-static)表现的相当好,产生了与利用复杂池化模式的复杂深度学习模型(Kalchbrenner et al., 2014)和需要提前计算解析树的模型(Socher et al., 2013)可比较的结果。这些结果说明预训练的词向量是好的,“通用”的特征抽取器,并且可以跨数据集使用。对每个任务细粒度的调节词向量可以进一步提升结果(CNN-non-static)。
4.1 多通道与单通道模型比较
我们一开始期望多通道的架构可以避免过拟合(通过确保学到词向量不会偏离初始值太远),并且比单通道的模型效果好,尤其在更小的数据集上。结果,然而是混合的,进一步在规范化细粒度调节过程的工作是必要的。例如,不使用额外的通道作为non-static的部分,也可以使用单通道,在训练过程中训练额外的维度。
4.2 静态与非静态表示比较
正如单通道非静态模型,多通道模型可以细粒度的调节非静态通道使它对手头的任务更具体。例如,在Word2vec中good和bad非常相似,大概是因为他们几乎语义相等。但是在SST-2数据集上,通过非静态通道调节的向量并不是这种情况。相似的,可以说在表达情感上,nice和great相比,与good更相近,这在训练的词向量中被真实的反映出来。
对于(随机初始化)不在预训练向量集合中的词,细粒度的调节允许它们学到更有意义的表示:网络训练得到感叹号经常与热情洋溢的表达联系在一起,并且逗号经常和连接副词联系在一起。
4.3 进一步观察
我们做了进一步的实验和观察。
Kalchbrenner et al.(2014)使用和我们单通道架构相同的CNN架构,但是却得到了不好的结果。例如,他们采用随机初始化词向量的Max-TDNN(时间延迟神经网络)模型在SST-1数据集上获得的结果是37.4%,和我们模型获得的45%相比。我们将此差异归因于我们的CNN有更大的容量(多个滤波器和特征映射)。
Dropout是如此好的正则化方法以致于用在一个比必要网络更大的网络上并且仅仅使用dropout去正则化效果是好的。Dropout一般可以将结果提升2%-4%。
当随机初始化不在Word2vec中的单词时,向量的每一维从U[-a,a]采样,结果获得了微小的提升,这里的a的选择要使随机初始化的词向量的方差和预训练的词向量有相同的方差。在初始化的过程中,尝试应用更复杂的方法反映预训练词向量的分布,看能否使结果得到提升是很有意思的事情。
我们在Collobert et al.(2011)通过维基百科训练的、另一个公用的词向量上进行试验,并且发现使用Word2vec的结果要远远优于它。目前不清楚是因为Mikovlov et al.(2013)的架构还是因为10亿的Google新闻数据集。
Adadelta(Zeiler,2012)和Adagrad(Duchi et al., 2011)的结果相似,但是需要更少的训练次数。
5.结论
在这篇论文中,我们使用卷积神经网络和Word2vec进行了一系列的实验。尽管微小的超参数调节,具有一个卷积层的简单CNN就表现的非常好。我们的实验再次证明:将深度学习应用在NLP领域,非监督预训练的词向量是一个非常重要的因素。