《applying deep learning to answer selection:a study and an open task》QA问答模型笔记
聊天机器人本质上是一个范问答系统,既然是问答系统就离不开候选答案的选择,利用深度学习的方法可以帮助我们找到最佳的答案,本节我们来讲述一下用深度学习来做自动问答的一般方法
语料库的获取方法
对于一个范问答系统,一般我们从互联网上收集语料信息,比如百度、谷歌等,用这些结果构建问答对组成的语料库。然后把这些语料库分成多个部分:训练集、开发集、测试集
问答系统训练其实是训练一个怎么在一堆答案里找到一个正确答案的模型,那么为了让样本更有效,在训练过程中我们不把所有答案都放到一个向量空间中,而是对他们做个分组,首先,我们在语料库里采集样本,收集每一个问题对应的500个答案集合,其中这500个里面有正向的样本,也会随机选一些负向样本放里面,这样就能突出这个正向样本的作用了
基于CNN的系统设计
CNN的三个优点:sparse interaction(稀疏的交互),parameter sharing(参数共享),equivalent respresentation(等价表示)。正是由于这三方面的优点,才更适合于自动问答系统中的答案选择模型的训练。
我们设计卷积公式表示如下(不了解卷积的含义请见《 机器学习教程 十五-细解卷积神经网络 》):
假设每个词用三维向量表示,左边是4个词,右边是卷积矩阵,那么得到输出为:
如果基于这个结果做1-MaxPool池化,那么就取o中的最大值
模型结构
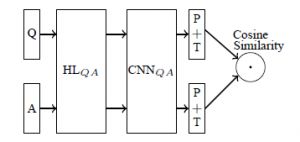
HL是一个非线性变换g(W*x+b),P是maxpooling,T是tanh激活函数。问题Q和答案A分别通过模型,得到两个向量。最后计算两个向量的余弦距离。
模型中,Q与A共用HL变化和CNN网络模型参数。
通用的训练方法
训练时获取问题的词向量Vq,和一个正向答案的词向量Va+,和一个负向答案的词向量Va-, 然后比较问题和这两个答案的相似度,如果两个相似度的差值cos(Vq,Va+)-cos(Vq,Va-)<阈值m就用来更新模型参数,因为当cos(Vq,Va+)-cos(Vq,Va-)
cos(Vq,Va+)-cos(Vq,Va-)
参数更新方式和其他卷积神经网络方式相同,都是梯度下降、链式求导
对于测试数据,计算问题和候选答案的cos距离,相似度最大的那个就是正确答案的预测
神经网络结构设计
以下是六种结构设计,解释一下,其中HL表示hide layer隐藏层,它的激活函数设计成z = tanh(Wx+B),CNN是卷积层,P是池化层,池化步长为1,T是tanh层,P+T的输出是向量表示,最终的输出是两个向量的cos相似度
图中HL或CNN连起来的表示他们共享相同的权重。CNN的输出是几维的取决于做多少个卷积特征,如果有4个卷积,那么结果就是4*3的矩阵(这里面的3在下一步被池化后就变成1维了)
以上结构的效果在论文《Applying Deep Learning To Answer Selection- A Study And An Open Task》中有详细说明,这里不赘述
总结
要把深度学习运用到聊天机器人中,关键在于以下几点:
1. 对几种神经网络结构的选择、组合、优化
2. 因为是有关自然语言处理,所以少不了能让机器识别的词向量
3. 当涉及到相似或匹配关系时要考虑相似度计算,典型的方法是cos距离
4. 如果需求涉及到文本序列的全局信息就用CNN或LSTM
5. 当精度不高时可以加层
6. 当计算量过大时别忘了参数共享和池化
模型实现
参见52NLP文章
insurance数据集https://github.com/shuzi/insuranceQA
方法文章
实现代码githubhttps://github.com/white127/insuranceQA-cnn-lstm
其中有cnn_theano , cnn_tensorflow , lstm_cnn_theano 三个版本的代码