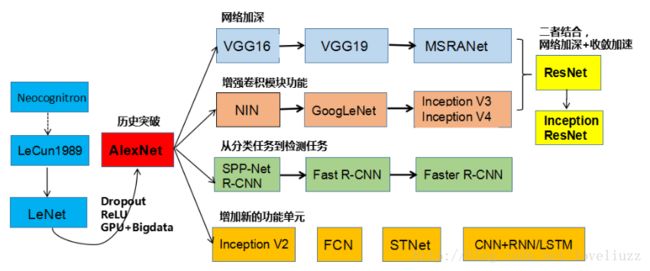
一网打尽深度学习之卷积神经网络的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
看过的最全最通俗易懂的卷积神经网络的经典网络总结,在此分享,供更多人学习。
一、CNN卷积神经网络的经典网络综述

下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344
二、LeNet-5网络
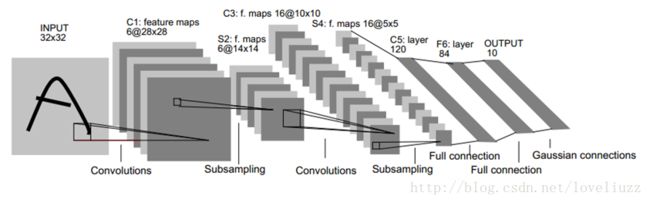

- 输入尺寸:32*32
- 卷积层:2个
- 降采样层(池化层):2个
- 全连接层:2个
- 输出层:1个。10个类别(数字0-9的概率)
LeNet-5网络是针对灰度图进行训练的,输入图像大小为32*32*1,不包含输入层的情况下共有7层,每层都包含可训练参数(连接权重)。注:每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
1、C1层是一个卷积层(通过卷积运算,可以使原信号特征增强,并且降低噪音)
第一层使用5*5大小的过滤器6个,步长s = 1,padding = 0。即:由6个特征图Feature Map构成,特征图中每个神经元与输入中5*5的邻域相连,输出得到的特征图大小为28*28*6。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
2、S2层是一个下采样层(平均池化层)(利用图像局部相关性的原理,对图像进行子抽样,可以1.减少数据处理量同时保留有用信息,2.降低网络训练参数及模型的过拟合程度)。
第二层使用2*2大小的过滤器,步长s = 2,padding = 0。即:特征图中的每个单元与C1中相对应特征图的2*2邻域相连接,有6个14*14的特征图,输出得到的特征图大小为14*14*6。池化层只有一组超参数 f 和 s,没有需要学习的参数。
3、C3层是一个卷积层
第三层使用5*5大小的过滤器16个,步长s = 1,padding = 0。即:由16个特征图Feature Map构成,特征图中每个神经元与输入中5*5的邻域相连,输出得到的特征图大小为10*10*16。C3有416个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共16个滤波器,共(5*5+1)*16=416个参数)。
4、S4层是一个下采样层(平均池化层)
第四层使用2*2大小的过滤器,步长s = 2,padding = 0。即:特征图中的每个单元与C3中相对应特征图的2*2邻域相连接,有16个5*5的特征图,输出得到的特征图大小为5*5*16。没有需要学习的参数。
5、F5层是一个全连接层
有120个单元。每个单元与S4层的全部400个单元之间进行全连接。F5层有120*(400+1)=48120个可训练参数。如同经典神经网络,F5层计算输入向量和权重向量之间的点积,再加上一个偏置。
6、F6层是一个全连接层
有84个单元。每个单元与F5层的全部120个单元之间进行全连接。F6层有84*(120+1)=10164个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。
7、Output输出层
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。 换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。
总结:
随着网络越来越深,图像的宽度和高度都在缩小,信道数量一直在增加。目前,一个或多个卷积层后边跟一个池化层,再接上一个全连接层的排列方式很常用。

| 层(layer) | 激活后的维度(Activation Shape) | 激活后的大小(Activation Size) | 参数w、b(parameters) |
| Input | (32,32,1) | 1024 | 0 |
| CONV1(f=5,s=1) | (28,28,6) | 4704 | (5*5+1)*6=156 |
| POOL1 | (14,14,6) | 1176 | 0 |
| CONV2(f=5,s=1) | (10,10,16) | 1600 | (5*5*6+1)*16=2416 |
| POOL2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 120*(400+1)=48120 |
| FC4 | (84,1) | 84 | 84*(120+1)=10164 |
| Softmax | (10,1) | 10 | 10*(84+1)=850 |

三、AlexNet网络
AlexNet网络共有:卷积层 5个,池化层 3个,全连接层:3个(其中包含输出层)。
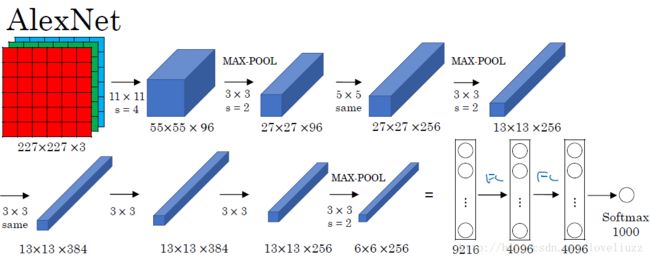

卷积神经网络的结构并不是各个层的简单组合,它是由一个个“模块”有机组成的,在模块内部,
各个层的排列是有讲究的。比如AlexNet的结构图,它是由八个模块组成的。
1、AlexNet——模块一和模块二
结构类型为:卷积-激活函数(ReLU)-降采样(池化)-标准化
这两个模块是CNN的前面部分,构成了一个计算模块,这个可以说是一个卷积过程的标配,从宏观的角度来看,
就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。
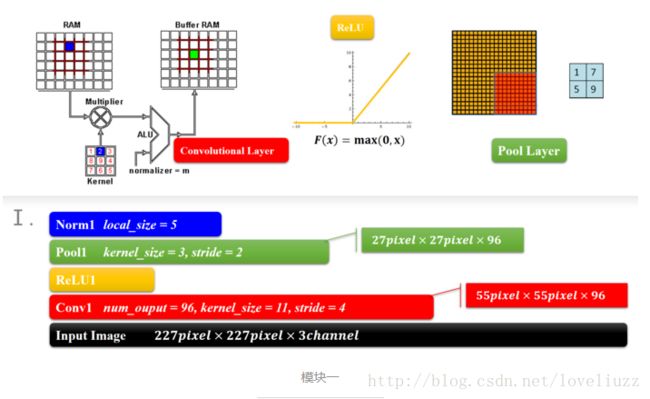
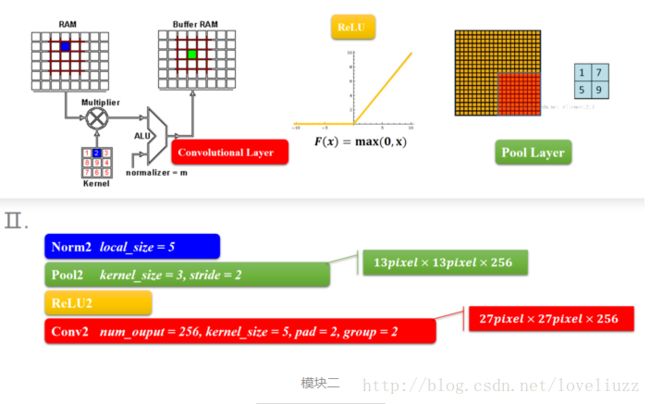
2、AlexNet——模块三和模块四
模块三和四也是两个same卷积过程,差别是少了降采样(池化层),原因就跟输入的尺寸有关,特征的数据量已经比较小了,
所以没有降采样。
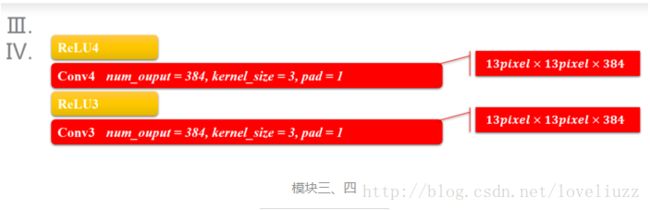
3、AlexNet——模块五
模块五也是一个卷积和池化过程,和模块一、二一样的。模块五输出的其实已经是6\6的小块儿了。
(一般设计可以到1\1的小块,由于ImageNet的图像大,所以6\6也正常的。)
原来输入的227\227像素的图像会变成6\*6这么小,主要原因是归功于降采样(池化层),
当然卷积层也会让图像变小,一层层的下去,图像越来越小。

4、模块六、七、八
模块六和七就是所谓的全连接层了,全连接层就和人工神经网络的结构一样的,结点数超级多,连接线也超多,
所以这儿引出了一个dropout层,来去除一部分没有足够激活的层。
模块八是一个输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。

AlexNet总结:
- 输入尺寸:227*227*3
- 卷积层:5个
- 降采样层(池化层):3个
- 全连接层:2个
- 输出层:1个。1000个类别

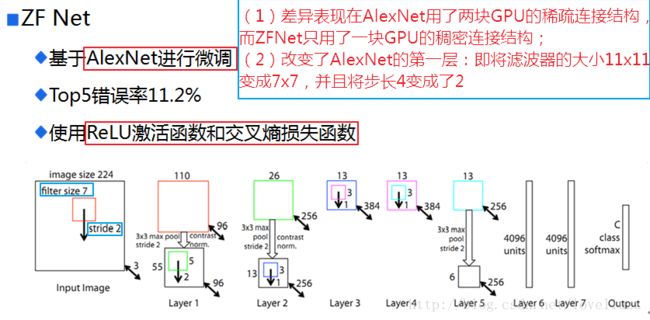
四、ZFNet

五、VGG-16网络

VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,
VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,
VGGNet论文中全部使用了3*3的小型卷积核和2*2的最大池化核,通过不断加深网络结构来提升性能。
VGG-16和VGG-19结构如下:


总结:
(1)VGG-16网络中的16代表的含义为:含有参数的有16个层,共包含参数约为1.38亿。
(2)VGG-16网络结构很规整,没有那么多的超参数,专注于构建简单的网络,都是几个卷积层后面跟一个可以压缩
图像大小的池化层。即:全部使用3*3的小型卷积核和2*2的最大池化层。
卷积层:CONV=3*3 filters, s = 1, padding = same convolution。
池化层:MAX_POOL = 2*2 , s = 2。
(3)优点:简化了卷积神经网络的结构;缺点:训练的特征数量非常大。
(4)随着网络加深,图像的宽度和高度都在以一定的规律不断减小,
每次池化后刚好缩小一半,信道数目不断增加一倍。
六、Inception网络(google公司)——GoogLeNet网络
(一)综述
获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),
但是这里一般设计思路的情况下会出现如下的缺陷:
1.参数太多,若训练数据集有限,容易过拟合;
2.网络越大计算复杂度越大,难以应用;
3.网络越深,梯度越往后穿越容易消失,难以优化模型。
解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。为了打破网络对称性和提高
学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,
所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。现在的问题是有没有一种方法,
既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
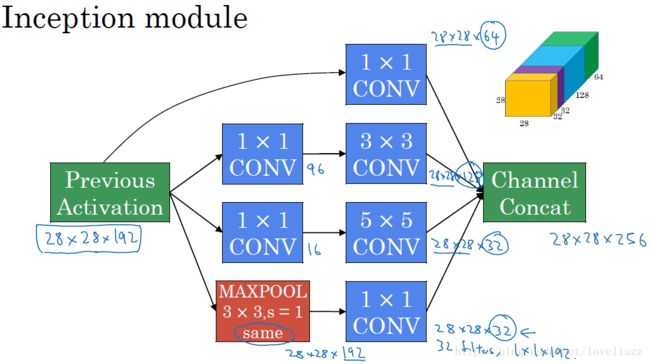
(二)Inception模块介绍
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。

对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1*1、3*3和5*5,主要是为了方便对齐。设定卷积步长stride=1之后,
只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
4 . 网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
Inception的作用:代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的
决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接
起来,网络自己学习它需要什么样的参数。
naive版本的Inception网络的缺陷:计算成本。使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。

为减少计算成本,采用1x1卷积核来进行降维。 示意图如下:
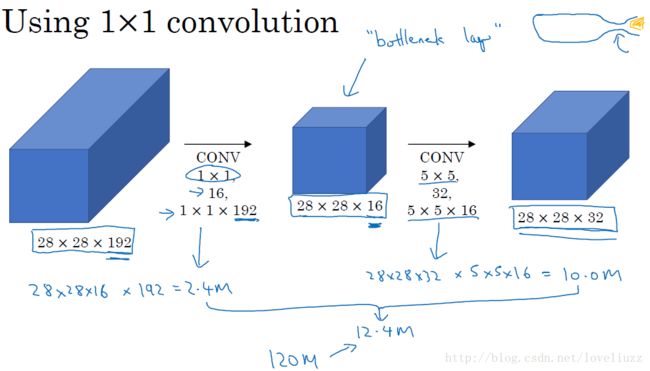
在3x3和5x5的过滤器前面,max pooling后分别加上了1x1的卷积核,最后将它们全部以通道/厚度为轴拼接起来,
最终输出大小为28*28*256,卷积的参数数量比原来减少了4倍,得到最终版本的Inception模块:
(三)googLeNet介绍
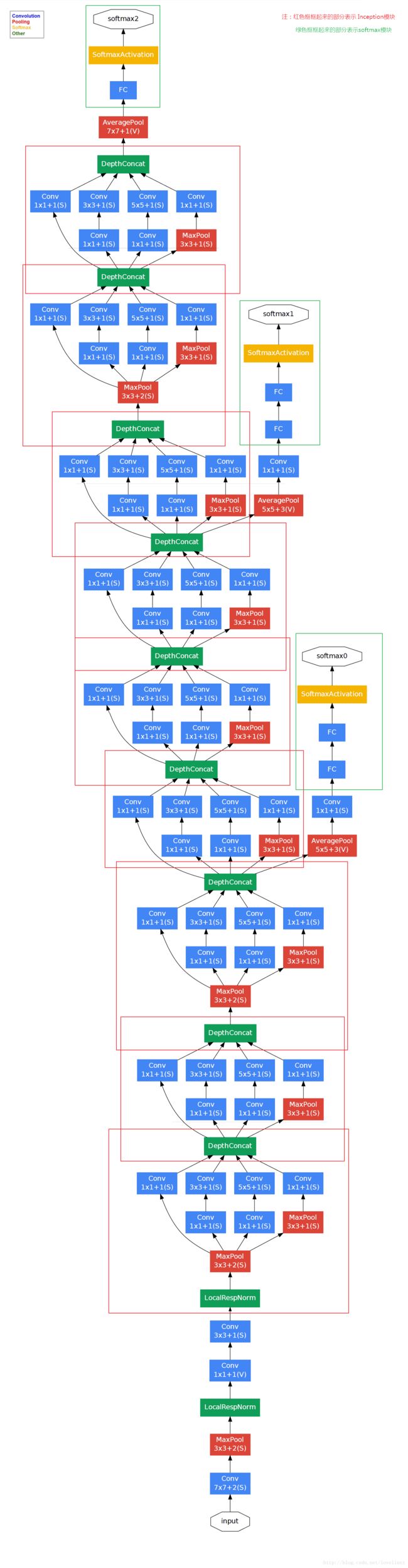
1、googLeNet——Inception V1结构
googlenet的主要思想就是围绕这两个思路去做的:
(1).深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,
googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2).宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,
但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,
所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,
max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
对上图做如下说明:
(1)显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
(2)网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,
事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。
此外,实际测试的时候,这两个额外的softmax会被去掉。
(5)上述的GoogLeNet的版本成它使用的Inception V1结构。
2、Inception V2结构
大尺寸的卷积核可以带来更大的感受野,也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。
为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,这便是Inception V2结构,
保持感受野范围的同时又减少了参数量,如下图:




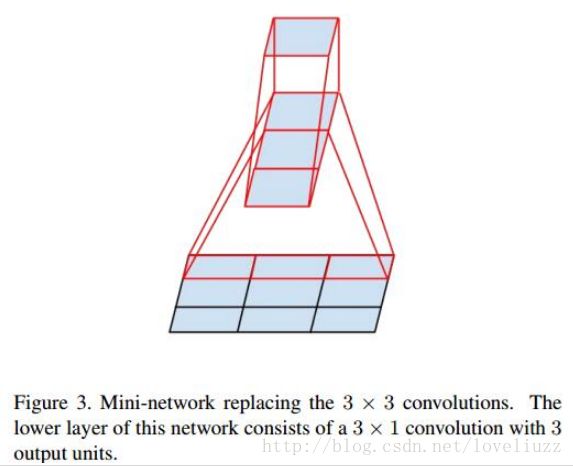
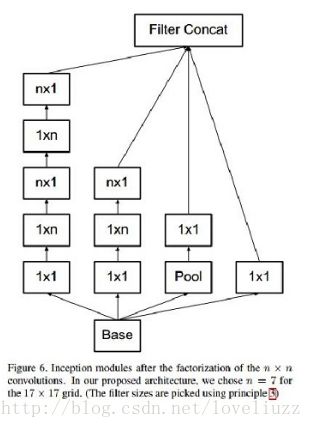
3、Inception V3结构
大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。
文章考虑了 nx1 卷积核,如下图所示的取代3x3卷积:
于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果
并不好,还有在中度大小的feature map上使用效果才会更好,对于mxm大小的feature map,建议m在12到20之间。
用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。


4、Inception V4结构,它结合了残差神经网络ResNet。
参考链接:http://blog.csdn.net/stdcoutzyx/article/details/51052847
http://blog.csdn.net/shuzfan/article/details/50738394#googlenet-inception-v2
七、残差神经网络——ResNet
(一)综述
深度学习网络的深度对最后的分类和识别的效果有着很大的影响,所以正常想法就是能把网络设计的越深越好,
但是事实上却不是这样,常规的网络的堆叠(plain network)在网络很深的时候,效果却越来越差了。其中原因之一
即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。 但是现在浅层的网络(shallower network)
又无法明显提升网络的识别效果了,所以现在要解决的问题就是怎样在加深网络的情况下又解决梯度消失的问题。
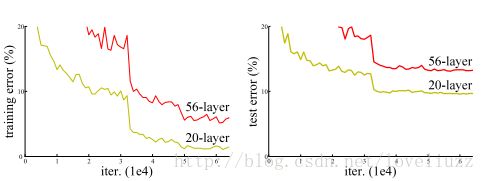
(二)残差模块——Residual bloack
通过在一个浅层网络基础上叠加 y=x 的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。
这反映了多层非线性网络无法逼近恒等映射网络。但是,不退化不是我们的目的,我们希望有更好性能的网络。
resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,
resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。
假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。
残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。


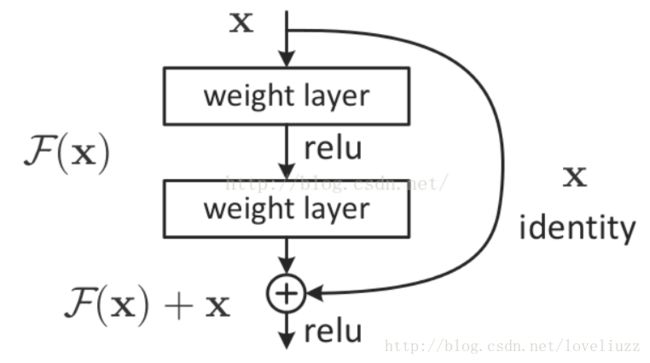
残差模块小结:
非常深的网络很难训练,存在梯度消失和梯度爆炸问题,学习 skip connection它可以从某一层获得激活,然后迅速反馈给另外一层甚至更深层,利用 skip connection可以构建残差网络ResNet来训练更深的网络,ResNet网络是由残差模块构建的。
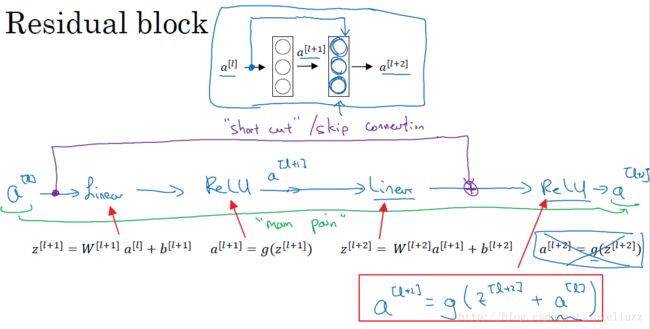
上图中,是一个两层的神经网络,在l层进行激活操作,得到a[l+1],再次进行激活得到a[l+2]。由下面公式:

a[l+2] 加上了 a[l]的残差块,即:残差网络中,直接将a[l]向后拷贝到神经网络的更深层,在ReLU非线性激活前面
加上a[l],a[l]的信息直接达到网络深层。使用残差块能够训练更深层的网络,构建一个ResNet网络就是通过将很多
这样的残差块堆积在一起,形成一个深度神经网络。
(三)残差网络——ResNet
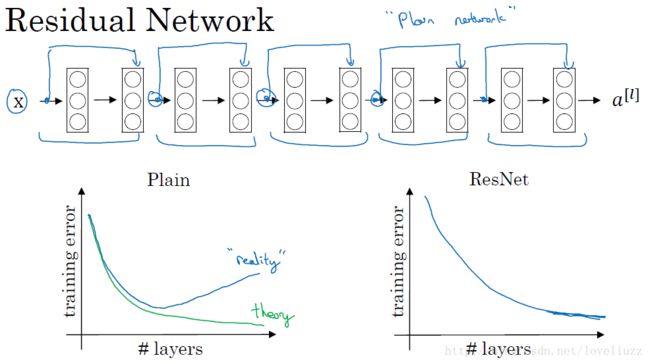
上图中是用5个残差块连接在一起构成的残差网络,用梯度下降算法训练一个神经网络,若没有残差,会发现
随着网络加深,训练误差先减少后增加,理论上训练误差越来越小比较好。而对于残差网络来讲,随着层数增加,
训练误差越来越减小,这种方式能够到达网络更深层,有助于解决梯度消失和梯度爆炸的问题,让我们训练更深网络
同时又能保证良好的性能。
残差网络有很好表现的原因举例:
假设有一个很大的神经网络,输入矩阵为X,输出激活值为a[l],加入给这个网络额外增加两层,最终输出结果为a[l+2],
可以把这两层看做一个残差模块,在整个网络中使用ReLU激活函数,所有的激活值都大于等于0。
对于大型的网络,无论把残差块添加到神经网络的中间还是末端,都不会影响网络的表现。
残差网络起作用的主要原因是:It's so easy for these extra layers to learn the itentity function.
这些残差块学习恒等函数非常容易。可以确定网络性能不受影响,很多时候甚至可以提高学习效率。
![]()

模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。

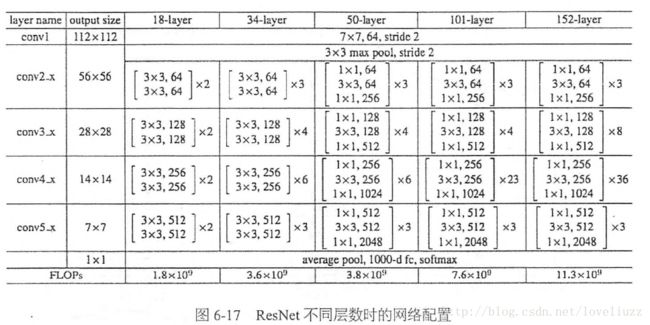
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。

转自:https://www.cnblogs.com/guoyaohua/p/8534077.html