linux下Hadoop1.0.4_单机伪分布式部署和分布式部署
本文是参考HDFS分布式文件系统的深度实践和北风网视频后的总结,以后学习的参考。
一、现在我们看一下CentOS5.6(32)的设置流程
1,首先将虚拟机的网卡设置为host-only
物理机器的虚拟网卡VMnet1的IP设置为192.168.1.1,以后建立的虚拟集群都在这个网段
2,启动系统,进入root用户
3,CentOS刚安装完毕,要进行初始化设置,使得一些基本命令可以直接使用,不用再输入绝对路径,
如:
[user@localhost ~]$ ifconfig
bash: ifconfig: command not found
3.1 配置/etc/profile文件,
在文件末加入以下语句:
PATH=$PATH:/sbin #在PATH变量后追加/sbin目录
export PATH=$PATH:/sbin#设置变量为全局的
3.2 配置/home/user/.bash_profile文件,
在PATH后面添加/sbin:/usr/sbin:/usr/local/sbin:/usr/kerberos/sbin这几个路径。
4,编辑/etc/sudoers文件,使得普通用户可以以root权限执行命令,就是命令前可以使用“sudo”
4.1 添加文件的写权限。chmod u+w /etc/sudoers。
4.2 编辑/etc/sudoers文件。在"root ALL=(ALL) ALL"下面添加"user ALL=(ALL) ALL"(这里的user是用户名),退出。
4.3 注释掉:Defaults requiretty所在的行。即:#Defaults requiretty
4.4 撤销文件的写权限。chmod u-w /etc/sudoers。
5,编辑/etc/sysconfig/network-scripts/ifcfg-eth0,设置网卡的为静态获取IP,并设置IP地址
DEVICE=eth0
BOOTPROTO=static
HWADDR=00:0C:29:67:87:79
IPADDR=192.168.1.11
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
ONBOOT=yes
6,编辑/etc/sysconfig/network和/etc/hosts设置机器名
network修改为:
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=namenode0
hosts修改为:
127.0.0.1 localhost
192.168.1.11 namenode0
127.0.0.1 namenode0(可要可不要)
7,重启虚拟机
8,可以看到sudo已经可以使用了,ifconfig也可以直接用了,主机名也已经改了
需要说明的是:
VMWare安装centos5.6后,例子:
选用NAT/Birdged方式的ifcfg-eth0内容如下:
# Advanced Micro Devices [AMD] 79c970 [PCnet32 LANCE]
DEVICE=eth0
BOOTPROTO=dhcp
DHCPCLASS=
HWADDR=00:0C:29:0E:20:58
ONBOOT=yes
要进行修改如下:
首先将虚拟机的网卡设置为host-only, 物理机器的虚拟网卡VMnet1的IP设置为192.168.1.1,以后建立的虚拟集群都在这个网段
编辑/etc/sysconfig/network-scripts/ifcfg-eth0,设置网卡的为静态获取IP,并设置IP地址
DEVICE=eth0
BOOTPROTO=static
HWADDR=00:0C:29:67:87:79
IPADDR=192.168.1.11
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
ONBOOT=yes
二、安装JDK
进入root,安装jdk。
进入user/123456用户 编辑~/.bashrc文件(或/etc/profile),加入以下几行
export JAVA_HOME=/home/user/jdk1.6.0_24
export JRE_HOME=/home/user/jdk1.6.0_24/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
source /etc/profile
java -version
可以看到java的版本信息,安装成功
三、假设虚拟机器
现在我们看一下虚拟集群的架设流程
1,连接到虚拟机namenode0(192.168.1.11)
2, 查看一下开机自动启动的服务,关闭其中一些不必要的,可以加快开机速度并减少内存占用
在SecureRCT中,直接右键就可以粘贴了,
有很多服务没必要开启
chkconfig --list
需要关闭的服务有如下几个:
echo "123456" | sudo -S 这个前缀可以使得普通用户不必在使用root权限
的时候再输入密码了,看一下,每次都要输入密码很麻烦。ok了!这里没问题。
echo "123456" | sudo -S chkconfig sendmail off
echo "123456" | sudo -S chkconfig bluetooth off
echo "123456" | sudo -S chkconfig NetworkManager off
echo "123456" | sudo -S chkconfig acpid off
echo "123456" | sudo -S chkconfig apmd off
echo "123456" | sudo -S chkconfig dund off
echo "123456" | sudo -S chkconfig pand off
echo "123456" | sudo -S chkconfig capi off
echo "123456" | sudo -S chkconfig cups off
echo "123456" | sudo -S chkconfig iptables off
echo "123456" | sudo -S chkconfig ip6tables off
echo "123456" | sudo -S chkconfig irda off
echo "123456" | sudo -S chkconfig isdn off
echo "123456" | sudo -S chkconfig kudzu off
echo "123456" | sudo -S chkconfig lm_sensors off
echo "123456" | sudo -S chkconfig mdmonitor off
echo "123456" | sudo -S chkconfig pcscd off
3,通过SecureFX将一些必要的软件copy到虚拟机里,速度比较慢。copy完了
4,关闭虚拟机
5,将虚拟机的镜像文件copy成3,一共4个虚拟机
注意:虚拟集群需要足够大的硬盘空间,另外物理机的内存也要足够大,实验中的物理机是8g的内存,如果内存不是很大,用3-4个虚拟机组成集群也可以,其中要有两个是作为namenode节点的,其他的作为datanode节点,当然把虚拟机的内存调小一些也可以。
6,启动一个新的虚拟机镜像
7,一个虚拟机副本copy完并启动之后,vmware会重新给其网卡分配一个mac地址,所以需要修改mac地址,IP也要改
copy后mac相同,怎么办?,办法:在VMware的每个虚拟机器的settings中 generate 一个,那这个去修改,不能随机修改。
这样就建立了如下的几个虚拟linux:
7.1 ifconfig 查看其它各个机器的eth0网卡的IP和mac地址
7.2 编辑其它各个机器的etc/sysconfig/network-scripts/ifcfg-eth0,IP地址
8,重启网卡
sudo service network restart
9,编辑/etc/sysconfig/network和/etc/hosts修改机器名
10,重启
11,可以看到这台虚拟机已经配置好了。
四、单机伪分布式部署(简单化conf)
我们首先拿namenode0进行伪分布式部署(conf简单配置)
1、实现SSH无密码登陆
1.1 实现无密码本机登录namenode0:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
直接回车,完成后会在 ~/.ssh/ 生成两个文件: id_dsa 和 id_dsa.pub 。这两个是成对出现,类似钥匙和锁。再把 id_dsa.pub 追加到授权 key 里面 ( 当前并没有 authorized_key s文件 ) :
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
还是要输入密码,一般这种情况都是因为目录或文件的权限问题,
sudo tail /var/log/secure -n 20
看看系统日志,确实是权限问题, 、ok了,.ssh下的authorized_keys权限为600,其父目录和祖父目录应为755,
$chmod 755 .
$chmod 755 ~/.ssh
$chmod 600 ~/.ssh/authorized_keys
2、下载hadoop-1.0.4.tar.gz 下载hadoop-1.0.4.bin.tar.gz也可以。
3,修改hadoop配置文件,指定JDk安装路径
vi conf/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.6.0_21
6,修改Hadoop核心配置文件core-site.xml,配置HDFS的地址和端口号
vi conf/core-site.xml
7,修改Hadoop中HDFS的配置,修改replication
vi conf/hdfs-site.xml
8,修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口
vi conf/mapred-site.xml
9,格式化Hadoop的文件系统HDFS
bin/hadoop namenode -format
10,启动hadoop
bin/start-all.sh
最后,验证Hadoop是否安装成功。打开浏览器,分别输入一下网址:
http://localhost:50030 (MapReduce的Web页面)
http://localhost:50070 (HDfS的web页面)
如果都能查看,说明安装成功。
五、分布式集群配置
1,准备3个服务器,分别为
机器名 IP地址 作用
namenode0 192.168.1.11 NameNode,JobTracker(也可作为DataNode,TaskTracker,但没这样做)
datanode00 192.168.1.13 DataNode,TaskTracker
datanode01 192.168.1.14 DataNode,TaskTracker
注:3台主机必须使用相同的用户名运行hadoop
1.2 实现无密码登录其他机器
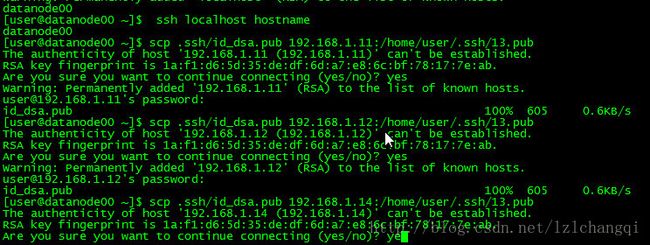
拷贝id_dsa.pub 文件到其他机器,scp是远程copy命令,192.168.1.11上的id_dsa.pub已经copy到其他机器上了,同样的,将每台机器上的id_dsa.pub copy到其他机器上。 登录其他机器 ,执行 cat 1x.pub >> .ssh/authorized_keys ok,都配通了,ssh的无密码登陆配置,容易出现很多问题,配置时一定要注意!!!
无密码登录是为了在namenode启动时能登录从而启动datanode,所以只需要master->slave拷贝就行了。而此处是互相拷贝(datanode不过不需要登录namenode就不需要copy了)。如下图
对namenode生成key,同样其它机器也类似,之后把1.11的copy到其它机器上,

同样其它机器生成后也需要scp到1.11上,如下的是把datanode00的copy到其它机器上
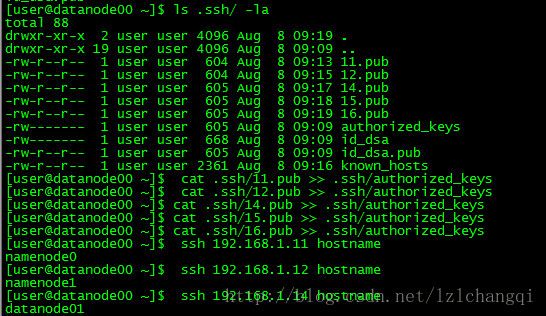
如下是namenode0和datanode00执行 cat 1x.pub >> .ssh/authorized_keys

进入user/123456 账户分别在这两个主机上,按照单机版的安装方法,安装hadoop,不过为了可以区别开,下面的流程是先对namenode0进行配置,然后copy 拷贝配置后的hadoop-1.0.4到其它机器上并修改conf中的文件。
2,修改/usr/local目录的权限,将hadoop-1.0.4的tar包copy到/usr/local/下
修改 权限sudo chmod 777 /usr/local/
如果从datanode00 copy到datanode01上,则需要先[user@datanode01 .ssh]$ sudo chmod 777 /usr/local/
才能[user@datanode00 local]$ scp -r /usr/local/hadoop-1.0.4 datanode01:/usr/local
不然会提示文件权限,不允许访问
3,配置 ~/.bashrc
在最后加入
export HADOOP_HOME=/usr/local/hadoop-1.0.4
export PATH=$HADOOP_HOME/bin:$PATH
5,配置/etc/hosts
192.168.1.11 namenode0
#192.168.1.12 namenode1
192.168.1.13 datanode00
192.168.1.14 datanode01
6,配置 conf/masters 和 conf/slaves
conf/masters
192.168.1.11
conf/slaves
192.168.1.13
192.168.1.14
7,配置 conf/hadoop-env.sh
加入
export JAVA_HOME=/usr/java/jdk1.6.0_21
8,配置 conf/core-site.xml
加入
fs.default.name
hdfs://namenode0:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp

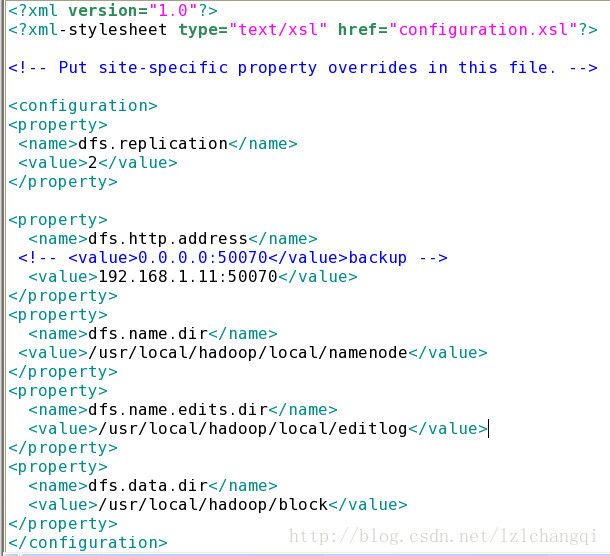
9,配置 conf/hdfs-site.xml
加入
dfs.replication
2
dfs.http.address
192.168.1.11:50070
dfs.name.dir
/usr/local/hadoop/local/namenode
dfs.name.edits.dir
/usr/local/hadoop/local/editlog
dfs.data.dir
/usr/local/hadoop/block
10,建立相关的目录(程序会根据上面的配置自动创建目录)
mkdir /usr/local/hadoop/tmp //hadoop临时目录
mkdir /usr/local/hadoop/local
mkdir /usr/local/hadoop/local/namenode //镜像存储目录
mkdir /usr/local/hadoop/local/editlog //日志存储目录
mkdir /usr/local/hadoop/block //数据块存储目录
如namenode00,虽然建立的block目录单,它不需要在目录,程序就不会创建,而datanode只会创建tmp和block,不会创建local。
注意如果在cygwin下这样配置,不会自动创建,而且手动创建后需要修改权限为755 ,不然会出现tasktracker启动失败问题,可以看tasktrack的日志
[user@namenode0 local]$ ls -sR hadoop
hadoop:
total 16
8 local 8 tmp
hadoop/local:
total 16
8 editlog 8 namenode
hadoop/local/editlog:
total 28
8 current 8 image 4 in_use.lock 8 previous.checkpoint
hadoop/local/editlog/current:
total 32
16 edits 8 fstime 8 VERSION
hadoop/local/editlog/image:
total 8
8 fsimage
hadoop/local/editlog/previous.checkpoint:
total 24
8 edits 8 fstime 8 VERSION
hadoop/local/namenode:
total 28
8 current 8 image 4 in_use.lock 8 previous.checkpoint
hadoop/local/namenode/current:
total 24
8 fsimage 8 fstime 8 VERSION
hadoop/local/namenode/image:
total 8
8 fsimage
hadoop/local/namenode/previous.checkpoint:
total 24
8 fsimage 8 fstime 8 VERSION
hadoop/tmp:
total 8
8 dfs
hadoop/tmp/dfs:
total 8
8 namesecondary
hadoop/tmp/dfs/namesecondary:
total 4
4 in_use.lock
11.修改namenode0配置文件masters

12 修改namenode0配置文件slaves
13.修改mapred-site.xml
mapred.job.tracker
namenode0:9001
mapred.child.tmp
/usr/local/hadoop/tmp
14,将hadoop远程copy到其他节点
scp -r hadoop-1.0.4 192.168.1.13:/usr/local/) 192.168.1.12也可以写为datanode00 (也可scp -r hadoop-1.0.4user@192.168.1.13:/usr/local/)
15,格式化Active namenode(192.168.1.11)
bin/hadoop namenode -format
16,启动集群 bin/start-all.sh