flume组合模式之高可用配置
一、flume简介
1、概念简述
Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中。轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均衡。并且它拥有非常丰富的组件。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,三者组建了一个Agent。三者的职责如下所示:
•Source:用来消费(收集)数据源到Channel组件中
•Channel:中转临时存储,保存所有Source组件信息
•Sink:从Channel中读取,读取成功后会删除Channel中的信息
下图是Flume NG的架构图,如下所示:
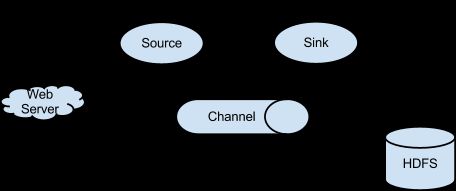
图中描述了,从外部系统(Web Server)中收集产生的日志,然后通过Flume的Agent的Source组件将数据发送到临时存储Channel组件,最后传递给Sink组件,Sink组件直接把数据存储到HDFS文件系统中。
2、常见模式
- Setting multi-agent flow(设置多个agent流)

为了让数据可以流过多个agents或者hops,前面那个agent的sink和当前的hop的source都必须是avro类型并且sink还要指向source的主机名(IP地址)和端口。
这种模式是将多个flume给顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量,就像路由器的桥接一样,多了网速会慢,flume过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
- Consolidation(结合)
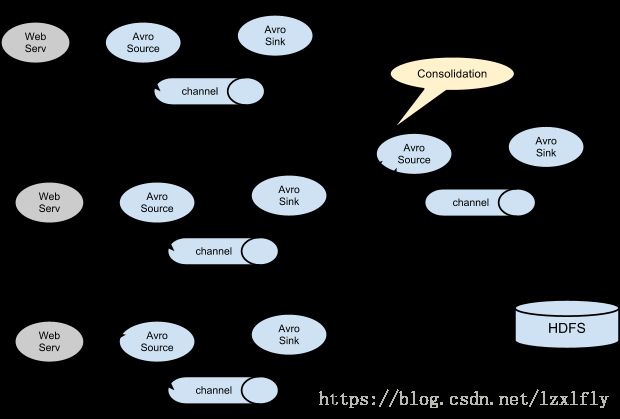
这种模式也是我们日常常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。
产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器一个flume采集日志,
传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase、jms等,进行日志分析。
- Multiplexing the flow(选择分流)
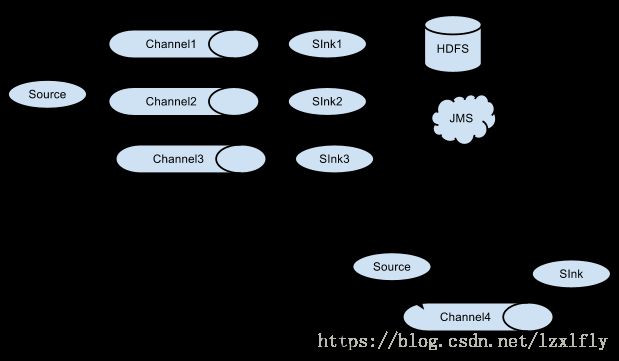
此模式,Flume支持将事件流向一个或者多个目的地。这个可以通过定义一个流的能够复制或者可选路径的多路选择器来将事件导向一个或者多个Channel来实现。
这种模式将数据源复制到多个channel中,每个channel都有相同的数据,sink可以选择传送的不同的目的地。
二、模式应用
1、 编辑hosts
这里用5台机搭建flume-HA集群,hosts加入以下内容
192.168.1.71 node01
192.168.1.72 node02
192.168.1.73 node03
192.168.1.74 node04
192.168.1.75 node052、案例说明-Consolidation(结合-高可用)
假设node01、node02、node03是我们的部署web应用的服务器,在每个服务器上flume Agent模式部署,采集web应用产生的日志,并传送给Collector。node04、node05是flume Collector模式部署,负责接收每个Agent传送过来的日志,并上传到hdfs。
| nodes | Web Server | flume Agent | flume Collector |
| node01 | 1 | 1 | |
| node02 | 1 | 1 | |
| node03 | 1 | 1 | |
| node04 | 1(主) | ||
| node05 | 1(备) |
三、下载安装
去http://flume.apache.org/download.html下载,这里下载最新稳定版apache-flume-1.8.0-bin.tar.gz
在node01下,/opt/bigdata/ 路径下,解压
tar -zxvf apache-flume-1.8.0-bin.tar.gz为了方便,重命名下
mv apache-flume-1.8.0-bin ./flume-1.8.0四、配置flume
1、配置环境变量
在/opt/bigdata/ 下,默认flume-env.sh.template,复制一份命名flume-env.sh
cp flume-1.8.0/conf/flume-env.sh.template flume-1.8.0/conf/flume-env.sh编辑 vim flume-1.8.0/conf/flume-env.sh,指定jdk路径
export JAVA_HOME=$JAVA_HOME
或直接指定jdk路径 export JAVA_HOME=/usr/local/jdk1.82、配置启动参数
在node01,/opt/bigdata/ 下,默认flume-conf.properties.template,复制一份命名flume-conf.properties
cp flume-1.8.0/conf/flume-conf.properties.template flume-1.8.0/conf/flume-conf.properties由于node01、node02、node03上的flume是Agent角色,所以这三台flume-conf.properties配置一样。编辑 vim flume-1.8.0/conf/flume-conf.properties,设置相关参数。
(1)Agent配置如下
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000 #channel中存储 events 的最大数量
agent1.channels.c1.transactionCapacity = 100 #事物容量,不能大于capacity,不能小于batchSize
#agent1.sources.r1.type = exec
#agent1.sources.r1.command = tail -F /data/logdfs/f.log #实时采集文件
#agent1.sources.r1.channels = c1
agent1.sources.r1.type = spooldir #spooldir类型
agent1.sources.r1.spoolDir = /data/logdfs #此路径下每产生新文件,flume就会自动采集
agent1.sources.r1.fileHeader = true
agent1.sources.r1.channels = c1
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node04
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro #协议类型
agent1.sinks.k2.hostname = node05
agent1.sinks.k2.port = 52020
#set gruop
agent1.sinkgroups = g1
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover #故障转移,若node04故障,node05自动接替node04工作
agent1.sinkgroups.g1.processor.priority.k1 = 10 #优先级10
agent1.sinkgroups.g1.processor.priority.k2 = 5 #优先级5
agent1.sinkgroups.g1.processor.maxpenalty = 10000 #最长等待10秒转移故障(2)分发flume到各个节点
scp flume-1.8.0 node02:`pwd`
scp flume-1.8.0 node03:`pwd`
scp flume-1.8.0 node04:`pwd`
scp flume-1.8.0 node05:`pwd`node04、node05上的flume是Collector角色,而node04承担了master角色,node05承担了slave角色,所以配置不一样,清空node04、node05配置,从新配置。
(3) Collector配置如下
node04如下:
a1.sources = r1
a1.channels = kafka_c1 hdfs_c2
a1.sinks = kafka_k1 hdfs_k2
#properties of avro-AppSrv-source
a1.sources.r1.type = avro
a1.sources.r1.bind = node04
a1.sources.r1.port = 52020
a1.sources.r1.channels=kafka_c1 hdfs_c2 #设置sources的channels
#增加拦截器 所有events,增加头,类似json格式里的"headers":{" key":" value"}
a1.sources.r1.interceptors = i1 #拦截器名字
a1.sources.r1.interceptors.i1.type = static #拦截器类型
a1.sources.r1.interceptors.i1.key = Collector #自定义
a1.sources.r1.interceptors.i1.value = node04 #自定义
#set kafka channel
a1.channels.kafka_c1.type = memory
a1.channels.kafka_c1.capacity = 1000
a1.channels.kafka_c1.transactionCapacity = 100
#set hdfs channel
a1.channels.hdfs_c2.type = memory
a1.channels.hdfs_c2.capacity = 1000
a1.channels.hdfs_c2.transactionCapacity = 100
#set sink to kafka
a1.sinks.kafka_k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_k1.channel=kafka_c1 #传输的channel名
a1.sinks.kafka_k1.topic = rwb_topic #kafka中的topic
a1.sinks.kafka_k1.brokerList = node01:9092,node02:9092,node03:9092
a1.sinks.kafka_k1.requiredAcks = 1
a1.sinks.kafka_k1.batchSize = 1000
#set sink to hdfs
a1.sinks.hdfs_k2.type=hdfs #传输到hdfs
a1.sinks.hdfs_k2.channel=hdfs_c2 #传输的channel名
a1.sinks.hdfs_k2.hdfs.path=hdfs://mycluster:8020/flume/logdfs #这里hadoop集群时HA集群,所以这里写的是集群的Namespace
a1.sinks.hdfs_k2.hdfs.fileType=DataStream
a1.sinks.hdfs_k2.hdfs.writeFormat=TEXT #文本格式
a1.sinks.hdfs_k2.hdfs.rollInterval=1 #失败1s回滚
a1.sinks.hdfs_k2.hdfs.filePrefix=%Y-%m-%d #文件名前缀
a1.sinks.hdfs_k2.hdfs.fileSuffix=.txt #文件名后缀
a1.sinks.hdfs_k2.hdfs.useLocalTimeStamp = true node05如下:
a1.sources = r1
a1.channels = kafka_c1 hdfs_c2
a1.sinks = kafka_k1 hdfs_k2
#properties of avro-AppSrv-source
a1.sources.r1.type = avro
a1.sources.r1.bind = node05
a1.sources.r1.port = 52020
a1.sources.r1.channels=kafka_c1 hdfs_c2 #设置sources的channels
#增加拦截器 所有events,增加头,类似json格式里的"headers":{" key":" value"}
a1.sources.r1.interceptors = i1 #拦截器名字
a1.sources.r1.interceptors.i1.type = static #拦截器类型
a1.sources.r1.interceptors.i1.key = Collector #自定义
a1.sources.r1.interceptors.i1.value = node04 #自定义
#set kafka channel
a1.channels.kafka_c1.type = memory
a1.channels.kafka_c1.capacity = 1000
a1.channels.kafka_c1.transactionCapacity = 100
#set hdfs channel
a1.channels.hdfs_c2.type = memory
a1.channels.hdfs_c2.capacity = 1000
a1.channels.hdfs_c2.transactionCapacity = 100
#set sink to kafka
a1.sinks.kafka_k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_k1.channel=kafka_c1 #传输的channel名
a1.sinks.kafka_k1.topic = rwb_topic #kafka中的topic
a1.sinks.kafka_k1.brokerList = node01:9092,node02:9092,node03:9092
a1.sinks.kafka_k1.requiredAcks = 1
a1.sinks.kafka_k1.batchSize = 1000
#set sink to hdfs
a1.sinks.hdfs_k2.type=hdfs #传输到hdfs
a1.sinks.hdfs_k2.channel=hdfs_c2 #传输的channel名
a1.sinks.hdfs_k2.hdfs.path=hdfs://mycluster:8020/flume/logdfs #这里hadoop集群时HA集群,所以这里写的是集群的Namespace
a1.sinks.hdfs_k2.hdfs.fileType=DataStream
a1.sinks.hdfs_k2.hdfs.writeFormat=TEXT #文本格式
a1.sinks.hdfs_k2.hdfs.rollInterval=1 #失败1s回滚
a1.sinks.hdfs_k2.hdfs.filePrefix=%Y-%m-%d #文件名前缀
a1.sinks.hdfs_k2.hdfs.fileSuffix=.txt #文件名后缀
a1.sinks.hdfs_k2.hdfs.useLocalTimeStamp = true 3、启动flume
(1)启动Collector
在node04、node05/opt/bigdata/下分别如下命令启动
flume-1.8.0/bin/flume-ng agent --conf conf --conf-file flume-1.8.0/conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console > flume-1.8.0/logs/flume-server.log 2>&1 &(2)启动Agent
在node01、node02、node03 /opt/bigdata/下分别如下命令启动
flume-1.8.0/bin/flume-ng agent --conf conf --conf-file flume-1.8.0/conf/flume-conf.properties --name agent1 -Dflume.root.logger=DEBUG,console > flume-1.8.0/logs/flume-server.log 2>&1 &a1、agent1 为各自flume的代理名
五、高可用测试
在node01、node02、node03任一节点 /data/logdfs下,产生新文件,该节点下的flume就会采集传送的node04的flume。
1、这里在node01下 复制cp /root/install.log 到 /data/logdfs 下,此时tail -f flume-1.8.0/logs/flume-server.log 查看node04的flume日志,部分日志如下:
18/06/17 14:54:22 INFO hdfs.HDFSEventSink: Writer callback called.
18/06/17 14:58:28 INFO ipc.NettyServer: Connection to /192.168.1.73:34166 disconnected.
18/06/17 14:59:21 INFO ipc.NettyServer: [id: 0xeffc35bb, /192.168.1.71:34175 => /192.168.1.74:52020] OPEN
18/06/17 14:59:21 INFO ipc.NettyServer: [id: 0xeffc35bb, /192.168.1.71:34175 => /192.168.1.74:52020] BOUND: /192.168.1.74:52020
18/06/17 14:59:21 INFO ipc.NettyServer: [id: 0xeffc35bb, /192.168.1.71:34175 => /192.168.1.74:52020] CONNECTED: /192.168.1.73:34175
18/06/17 14:59:21 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
18/06/17 14:59:21 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961816.txt.tmp
18/06/17 14:59:21 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961816.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961816.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529261961816.txt
18/06/17 14:59:22 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961817.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961817.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961817.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529261961817.txt
18/06/17 14:59:22 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961818.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961818.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961818.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529261961818.txt
18/06/17 14:59:22 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961819.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961819.txt.tmp
18/06/17 14:59:22 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529261961819.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529261961819.txt与此此时看node05的flume日志是没有任何情况的,也就是node05的flume没有工作
2、接下啦kill掉node04的flume,在node01下,复制一个新文件到cp /root/install.log.syslog 到 /data/logdfs 下,部分日志如下
18/06/17 14:24:17 INFO hdfs.HDFSEventSink: Writer callback called.
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.71:51692 => /192.168.1.75:52020] OPEN
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.71:51692 => /192.168.1.75:52020] BOUND: /192.168.1.75:52020
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.71:51692 => /192.168.1.75:52020] CONNECTED: /192.168.1.71:51692
18/06/17 14:39:45 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
18/06/17 14:39:45 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785844.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785845.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785846.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785847.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785848.txt可以看到node01与node05建立的连接,node05把采集到的文件开始上传到hdfs,node05-flume接替了node04-flume的工作,故障自动转移了。
3、此时在重新启动node04的flume,这次我们换台机,在node02 /data/lodfs下产生新文件,
复制cp /root/nohup.out 到 /data/lodfs 下,查看node04的flume日志,部分日志如下
18/06/17 14:24:17 INFO hdfs.HDFSEventSink: Writer callback called.
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.72:51692 => /192.168.1.74:52020] OPEN
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.72:51692 => /192.168.1.74:52020] BOUND: /192.168.1.74:52020
18/06/17 14:39:42 INFO ipc.NettyServer: [id: 0x7079374a, /192.168.1.72:51692 => /192.168.1.74:52020] CONNECTED: /192.168.1.72:51692
18/06/17 14:39:45 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
18/06/17 14:39:45 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785844.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785844.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785845.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785845.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785846.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785846.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785847.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785847.txt
18/06/17 14:39:46 INFO hdfs.BucketWriter: Creating hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Closing hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp
18/06/17 14:39:46 INFO hdfs.BucketWriter: Renaming hdfs://mycluster:8020/flume/logdfs/2018-06-17.1529260785848.txt.tmp to hdfs://myclu
ster:8020/flume/logdfs/2018-06-17.1529260785848.txt可以看到node02与node04建立的连接,node04的flume把采集到的文件开始上传到hdfs,node04的flume启动后,又重新下恢复正常工作了
参考:https://blog.csdn.net/shouhuzhezhishen/article/details/64904848
参考:https://www.cnblogs.com/simple-focus/p/6138896.html
参考:http://flume.apache.org/FlumeUserGuide.html