mysql数据库总结(1)
mysql数据库,是当前应用非常广泛的一款关系型数据库
主要知识点包括: 1数据库与表的操作 2数据的增加、修改、删除 3数据的查询(重点) 4与python交互
E-R模型
当前物理的数据库都是按照E-R模型进行设计的
E表示entry,实体
R表示relationship,关系
一个实体转换为数据库中的一个表
关系描述两个实体之间的对应规则,包括
- 一对一 合法的情况下:一个男人娶一个女人,一个女人嫁一个男人
- 一对多 目前教室里,一个老师教多个学生,一个学生被一个老师教,一个教室里有很多学生,一个学生只能一个教室
- 多对多 1在大学中,一个学生选很多课程,一个课程被学生选。2在大学里,一个学生可以有很多老师,一个老师可以教很多学生 3关系转换为数据库表中的一个列在关系型数据库中一行就是一个对象
三范式
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式。在一定程度上,为了提高访问性能,可以允许一定的冗余。
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
- 第一范式(1NF) 简而言之,第一范式就是无重复的域。
- 第二范式(2NF) 简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
- 第三范式(3NF) 简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。
说明:后一个范式,都是在前一个范式的基础上建立的
安装管理 sudo apt-get install mysql-server mysql-client
- 启动 service mysql start
- 停止 service mysql stop
- 重启 service mysql restart
- 查询服务是否启动 netstat -tap | grep mysql
允许远程连接
- 找到mysql配置文件并修改 sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf 将bind-address=127.0.0.1注释
- 重启mysql /etc/init.d/mysql restart 或者 service mysql restart
卸载管理
删除mysql的数据文件
sudo rm /var/lib/mysql/ -R
删除mqsql的配置文件
sudo rm /etc/mysql/ -R
自动卸载mysql的程序
sudo apt-get autoremove mysql* --purge
sudo apt-get remove apparmor
数据库的常见操作命令:
1登录
ps -aux|grep '.*mysql.*'
sudo service mysql restart
mysql -uroot -p 密码
2选择哪个数据库
use 数据库名
3创建新的数据库
create database 数据库名字 default charset = utf8;
4删除数据库
drop database 数据库名字
5创建表
create table 表面(
列名 类型,
列名 类型,
列名 类型,
........
类型:int,deximal,char,varchar,longtext,date,time,datatime
)
6删除表
drop table 表名
7显示当前数据库有多少表
show tables;
8创建表,加约束
如果有主键表
先创建主键表,再创建外键表
如果有主外键
先删除外键表,再删主键表
drop table if exists student;
drop table if exists grade;
create table student(
sid int primary key,
sname varchar (20),
ssex char(1) not null,
snickame varchar(20) unique,
saddress varchar(200) default ' 未知 ',
dnum int not null,
constraint student_dnum_grade foreign key(dnum) references grade(gid) on delete cascade
);
create table grade(
gid int primary key;
gname varchar(20) unique not null
);
约束
目的:保证数据的正确性。
- 主键primary key,默认是唯一
- 非空not null
- 惟一unique
- 默认default
- 外键foreign key
使用图形窗口连接
windows下的navicat点击“连接”弹出窗口,按照提示填写连接信息,如下图
- 连接成功后,会在连接名称下面显示出当前的数据库
- 双击选中数据库,就可以编辑此数据库
- 下次再进入此软件时,通过双击完成连接、编辑操作
数据库操作
- 在连接的名称上右击,选择“新建数据库”,弹出窗口,并按提示填写

- 在数据库上右击,选择“删除数据库”可以完成删除操作
表操作
- 当数据库显示为高亮时,表示当前操作此数据库,可以在数据中创建表
- 一个实体对应一张表,用于存储特定结构的数据
- 点击“新建表”,弹出窗口,按提示填写信息

- 主键的名称一般为id,设置为int型,无符号数,自动增长,非空
- 自动增长表示由mysql系统负责维护这个字段的值,不需要手动维护,所以不用关心这个字段的具体值
- 字符串varchar类型需要设置长度,即最多包含多少个字符
- 点击“添加栏位”,可以添加一个新的字段
- 点击“保存”,为表定义名称
数据操作
- 表创建成功后,可以在右侧看到,双击表打开新窗口,如下图
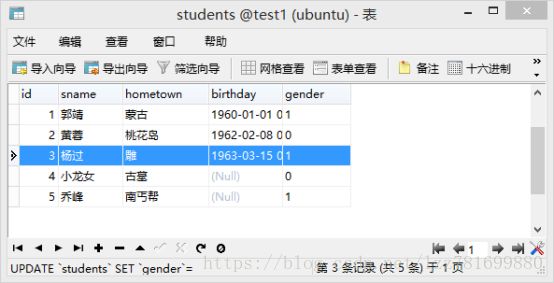
- 在此窗口中可以增加、修改、删除数据
逻辑删除
- 对于重要数据,并不希望物理删除,一旦删除,数据无法找回
- 一般对于重要数据,会设置一个isDelete的列,类型为bit,表示逻辑删除
- 大于大量增长的非重要数据,可以进行物理删除
- 数据的重要性,要根据实际开发决定
脚本命令操作
sql语句分为两大类:
dml 对表的数据内容进行增删改查,ddl 除了dml之外
使用命令连接
- 命令操作方式,在工作中使用的更多一些,所以要达到熟练的程度
- 打开终端,运行命令
mysql -hip -uname -ppassword
mysql -uroot -p
回车后输入密码,当前设置的密码为mysql
- 连接成功后如下图
- 退出登录 quit或exit
- 退出成功后如下图
![]()
远程连接
- 登录成功后,输入如下命令查看效果 : 查看版本:select version(); 显示当前时间:select now();
- 一般在公司开发中,可能会将数据库统一搭建在一台服务器上,所有开发人员共用一个数据库,而不是在自己的电脑中配置一个数据库
- 运行命令 mysql -hip地址 -uroot -p
- -h后面写要连接的主机ip地址
- -u后面写连接的用户名
- -p回车后写密码
数据库操作
- 创建数据库 create database 数据库名 charset=utf8;
- 删除数据库 drop database 数据库名;
- 切换数据库 use 数据库名;
- 查看当前选择的数据库 select database();
表操作
- 查看当前数据库中所有表 show tables;
- 创建表 auto_increment表示自动增长,只能是数字类型,主键本身是用来唯一标识这一行,没有业务逻辑意义,所以是什么值不重要,只要唯一就行,所以如果是主键不需要修改.
-
修改表create table 表名(列及类型); 如: create table students( id int auto_increment primary key, sname varchar(10) not null );
alter table 表名 add|modify|drop 列名 类型;
如:
alter table students add birthday datetime;删除表 drop table 表名;
查看表结构 desc 表名;
更改表名称 rename table 原表名 to 新表名;
查看表的创建语句 show create table '表名';
数据操作
- 查询 select * from 表名
- 增加 全列插入:insert into 表名 values(...), 缺省插入:insert into 表名(列1,...) values(值1,...), 同时插入多条 数据:insert into 表名 values(...),(...)...; 或insert into 表名(列1,...) values(值1,...),(值1,...)...;
- 主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准
- 修改 update 表名 set 列1=值1,... where 条件
- 删除 delete from 表名 where 条件
- 逻辑删除,本质就是修改操作update alter table students add isdelete bit default 0;如果需要删除则;update students isdelete=1 where ...;
备份与恢复
- 数据备份 进入超级管理员Sudra -s
- 运行mysqldump命令 mysqldump –uroot –p 数据库名 > ~/备份文件.sql;按提示输入mysql的密码
- 数据恢复 连接mysql,创建数据库,退出连接,执行如下命令,mysql -uroot –p 数据库名 < ~/备份文件.sql
根据提示输入mysql密码
总结
- 数据库解决的问题,E-R模型,三范式
- 图形界面操作数据库、表、数据
- 命令行操作数据库、表、数据
查询
- 查询的基本语法 select * from 表名;
- from关键字后面写表名,表示数据来源于是这张表
- select后面写表中的列名,如果是*表示在结果中显示表中所有列
- 在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中
- 如果要查询多个列,之间使用逗号分隔
-
消除重复行
- 在select后面列前使用distinct可以消除重复的行 select distinct gender from students;
条件
- 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中 语法如下: select * from 表名 where 条件;
比较运算符
- 等于=
- 大于>
- 大于等于>=
- 小于<
- 小于等于<=
- 不等于!=或<>
- 查询编号大于3的学生 select * from students where id>3;
- 查询编号不大于4的科目 select * from subjects where id<=4;
- 查询姓名不是“黄蓉”的学生 select * from students where sname!='黄蓉';
- 查询没被删除的学生 select * from students where isdelete=0;
逻辑运算符
- and
- or
- not
- 查询编号大于3的女同学 select * from students where id>3 and gender=0;
- 查询编号小于4或没被删除的学生 select * from students where id<4 or isdelete=0;
模糊查询
- like
- %表示任意多个任意字符
- _表示一个任意字符
- 查询姓黄的学生 select * from students where sname like '黄%';
- 查询姓黄并且名字是一个字的学生 select * from students where sname like '黄_';
- 查询姓黄或叫靖的学生 select * from students where sname like '黄%' or sname like '%靖%';
范围查询
- in表示在一个非连续的范围内
- 查询编号是1或3或8的学生
- select * from students where id in(1,3,8);
- between ... and ...表示在一个连续的范围内
- 查询学生是3至8的学生
- select * from students where id between 3 and 8;
- 查询学生是3至8的男生
- select * from students where id between 3 and 8 and gender=1;
空判断
- 注意:null与''是不同的
- 判空is null
- 查询没有填写地址的学生
- select * from students where hometown is null;
- 判非空is not null
- 查询填写了地址的学生
- select * from students where hometown is not null;
- 查询填写了地址的女生
- select * from students where hometown is not null and gender=0;
优先级
- 小括号,not,比较运算符,逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
聚合
- 为了快速得到统计数据,提供了5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
- 查询学生总数 select count(*) from students;
- max(列)表示求此列的最大值 查询女生的编号最大值 select max(id) from students where gender=0;
- min(列)表示求此列的最小值 查询未删除的学生最小编号 select min(id) from students where isdelete=0;
- sum(列)表示求此列的和 查询男生的编号之后 select sum(id) from students where gender=1;
- avg(列)表示求此列的平均值 查询未删除女生的编号平均值 select avg(id) from students where isdelete=0 and gender=0;
分组
select
from 分组之前的过滤
where
group by 分组之后的过滤
having
limit
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,只能查询被分组的列和聚合函数
- 可以对分组后的数据进行统计,做聚合运算
- 语法: select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
- 查询男女生总数 select gender as 性别,count(*) from students group by gender;
- 查询各城市人数 select hometown as 家乡,count(*) from students group by hometown;
分组后的数据筛选
- 语法: select 列1,列2,聚合... from 表名
group by 列1,列2,列3...
having 列1,...聚合...
- having后面的条件运算符与where的相同
- 查询男生总人数
对比where与having方案一 select count(*) from students where gender=1; ----------------------------------- 方案二: select gender as 性别,count(*) from students group by gender having gender=1; - where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
排序
查询未删除科目信息,按名称升序
- 为了方便查看数据,可以对数据进行排序
- 语法:
-
select * from 表名
order by 列1 asc|desc,列2 asc|desc,...
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 查询未删除男生学生信息,按学号降序
-
select * from students where gender=1 and isdelete=0 order by id desc;
select * from subject
where isdelete=0
order by stitle;