【Hadoop】Windows 10 在Intellij IEDA本地运行Hadoop MapReduce实例
环境:
操作系统:Windows 10
Hadoop版本:2.7.3
Java版本: 1.8
- 前期准备:
- 1. 配置hadoop环境。
- 2. 配置maven环境。
- 3. 在idea创建Maven工程
- 2.运行MR实例
- 1.编写JavaWordCount
- 3. 运行问题解决
- 1. NativeIO问题
- 2.FileUtils问题
- 3. 每次Maven import changes后Java版本变1.5
- 4.某一个依赖下的类都找不到
- 5.无log信息
前期准备:
1. 配置hadoop环境。
按【Windows部署Hadoop(无Cygwin)】的方法配置Hadoop环境。
2. 配置maven环境。
1.下载maven部署包apache-maven-3.5.3-bin.zip,解压到D:\envpath\apache-maven目录下。
2.在apache-maven目录下新建文件夹repository,这个文件夹用来存放maven下载的jar包。
3.修改apache-maven-3.5.3-bin的conf文件夹下settings.xml文件。将修改的settings.xml文件复制到apache-maven目录下。
<localRepository>D:/envpath/apache-maven/repositorylocalRepository>
<mirrors>
<mirror>
<id>alimavenid>
<mirrorOf>centralmirrorOf>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/repositories/central/url>
mirror>
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>centralid>
<name>Maven Repository Switchboardname>
<url>http://repo1.maven.org/maven2/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>repo2id>
<mirrorOf>centralmirrorOf>
<name>Human Readable Name for this Mirror.name>
<url>http://repo2.maven.org/maven2/url>
mirror>
<mirror>
<id>ibiblioid>
<mirrorOf>centralmirrorOf>
<name>Human Readable Name for this Mirror.name>
<url>http://mirrors.ibiblio.org/pub/mirrors/maven2/url>
mirror>
<mirror>
<id>jboss-public-repository-groupid>
<mirrorOf>centralmirrorOf>
<name>JBoss Public Repository Groupname>
<url>http://repository.jboss.org/nexus/content/groups/publicurl>
mirror>
<mirror>
<id>google-maven-centralid>
<name>Google Maven Centralname>
<url>https://maven-central.storage.googleapis.com
url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>maven.net.cnid>
<name>oneof the central mirrors in chinaname>
<url>http://maven.net.cn/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
mirrors>
<profiles>
profiles>
settings>4.配置系统环境变量。
1) 变量名:MAVEN_HOME 变量值:D:/envpath/apache-maven/repository(maven包的目录)
2) 变量名:MAVEN_OPTS 变量值:-Xms128m -Xmx512m -Duser.language=zh -Dfile.encoding=UTF-8
3) 将%MAVEN_HOM%bin加入Path变量。
4.测试maven是否配置成功。在cmd输入mvn -v。如下,表示成功。
C:\Users\DELL_PC>mvn -v
Apache Maven 3.5.3 (3383c37e1f9e9b3bc3df5050c29c8aff9f295297; 2018-02-25T03:49:05+08:00)
Maven home: D:\envpath\apache-maven\apache-maven-3.5.3\bin\..
Java version: 1.8.0_111, vendor: Oracle Corporation
Java home: D:\envpath\jdk1.8.0_111\jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"3. 在idea创建Maven工程
1.配置idea的maven。
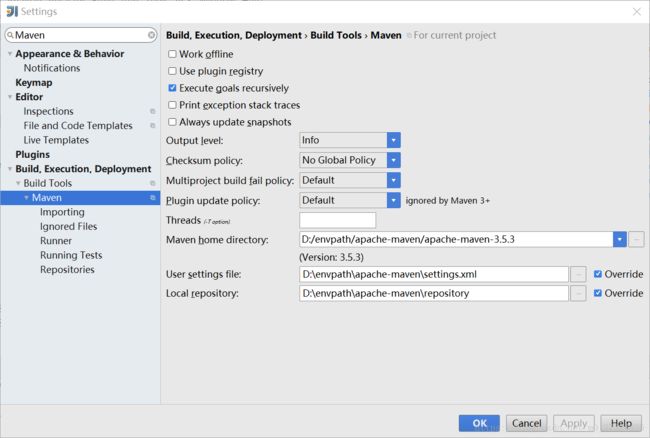
打开file-Settings,搜索maven。idea默认使用内嵌的maven。如下,将maven的home目录改为为本地的maven目录,settings.xml和repository也一并修改。
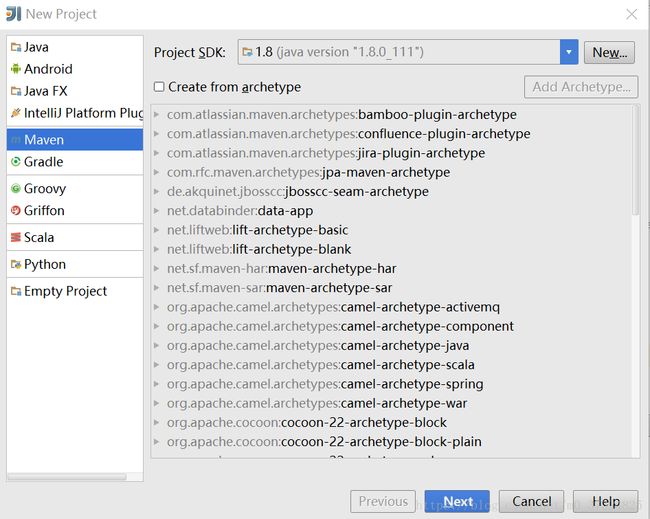
打开idea,创建project时,选择创建maven工程。
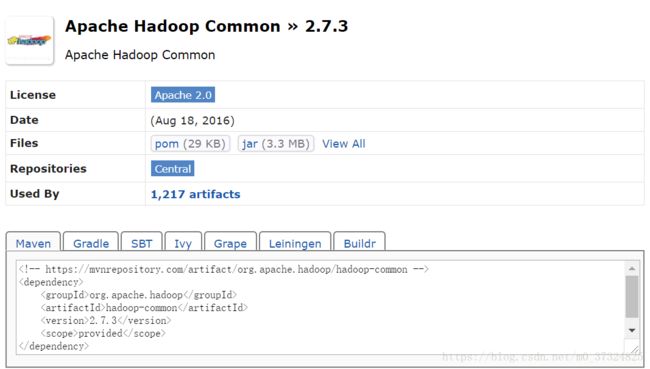
工程创建好后会有一个pom.xml文件。在pom.xml文件中添加hadoop所需的依赖。如果不知道依赖该怎么写,可以直接到MVNRepository搜索。选择相应的版本,直接复制。
提供一个样例,如下所示。
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-coreartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>2.7.3version>
dependency>
dependencies>2.运行MR实例
1.编写JavaWordCount
新建一个java源文件,实例为WordCount,输入文件为data/input/wc.txt,data文件夹在工程的根目录下。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JavaWordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "D:\\envpath\\hadoop-2.7.3");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(JavaWordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("data/input/wc.txt"));//设置输入路径
FileOutputFormat.setOutputPath(job,
new Path("data/output/wc"));//设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 3. 运行问题解决
直接运行上述代码,发现遇到了很多问题。按发生的顺序依次记录。
1. NativeIO问题
具体表现:找不到org.apache.hadoop.io.nativeio.NativeIO&POSIX&Stat
1)按照网上的一些解决方法,将hadoop目录下的bin文件中的hadoop.dll和winutils.exe复制到c:\windows\System32。注意,从官网下载的hadoop的部署包是没有这两个文件的,只能通过其他途径找到相应hadoop版本的hadoop.dll和winutils.exe文件。
2)再次执行,还是无法解决。于是,重启。
3)重启后还是无法解决。又将其复制到了C:\Windows\SysWOW64。
4)还是无法解决,可能是hadoop.dll等文件版本不适配。于是,直接下载hadoop-2.7.3的源码文件。在maven工程中创建package,package与NativeIO.java的一致,为org.apache.hadoop.io.nativeio。将NativeIO.java复制到该目录下。
5)如果出现其他的无法找到的类的问题,也可以用这个方法解决。
2.FileUtils问题
具体表现:Exception in thread “main” java.io.IOException: Failed to set permissions of path: \tmp\hadoop-XXX\mapred\staging\XXX-XXX.staging to 0700
1)在maven工程创建org.apache.hadoops.fs的package,将FileUtils.java文件复制到该目录下,将checkReturnedValue内的代码注释掉。
private static void checkReturnValue(boolean rv, File p,
FsPermission permission
) throws IOException {
/*
if (!rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
}
*/
}2)编译工程。在工程的target目录下得到FileUtils.class文件。
3)在maven的respository目录搜索hadoop-core,搜索到hadoop-core-1.2.1.jar。解压这个jar文件。用新编译的FileUtils.class文件代替jar中相应的文件。然后,打包jar。可以通过cmd命令打包jar。
jar cvf hadoop-core-1.2.1.jar /hadoop-core-1.2.14)新打包的jar替换掉原来的jar包。问题解决。
3. 每次Maven import changes后Java版本变1.5
具体表现,每次更新pom.xml文件,import changes后,项目的language level变成1.5(虽然配置的jdk是1.8)。build后,会出现如下错误。
Error:(732, 9) java: -source 1.5 中不支持 try-with-resources
(请使用 -source 7 或更高版本以启用 try-with-resources)一个比较笨的方法是,每次import changes后去setting和project structure改变java bytecod version和language level。

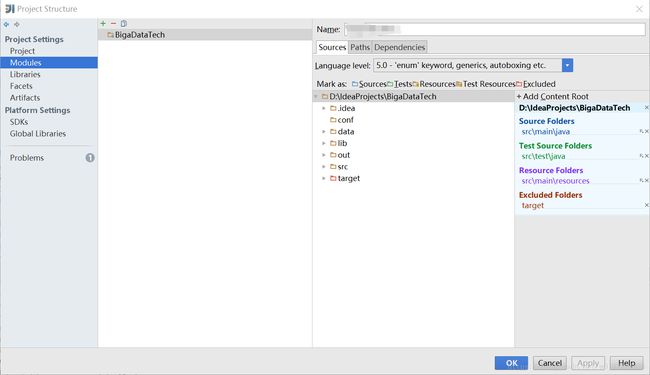
另一种就是在pom.xml添加设置。
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
plugins>4.某一个依赖下的类都找不到
查看pom.xml是否设置错误。相应依赖下是否设置了
比如下面这个例子,会导致hadoop-common包含类都找不到类。解决这个问题只需要将scope的定义去掉。
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.3version>
<scope>providedscope>
dependency>5.无log信息
具体表现:log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
解决:在src的resources文件夹下新建一个log4j.properties。在文件中添加如下内容。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/hadoop.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n