Linux上搭建spark环境
Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。Spark 正如其名,最大的特点就是快(Lightning-fast),可比 Hadoop MapReduce 的处理速度快 100 倍。此外,Spark 提供了简单易用的 API,几行代码就能实现 WordCount。

注意:
我的环境:
scala:2.11.12
spark:2.3.0
java:1.8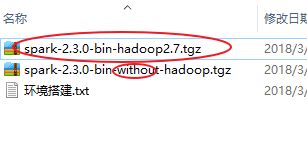
vim ~/.bashrc
#set spark environment
export SPARK_HOME=/home/cxx/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
#set scala environment
export SCALA_HOME=/home/cxx/bigdata/scala
export PATH=$PATH:$SCALA_HOME/bin
vim spark/conf/sprak-env.sh 在末尾添加
export SCALA_HOME=/home/cxx/bigdata/spark
export SPARK_WORKER_MEMORY=2g
export SPARK_MASTER_IP=spark
export MASTER=spark://spark:7077
export JAVA_HOME=/home/cxx/bigdata/jdk测试
1.在命令行输入:spark-shell(可在安装目录中bin里面找到)
2.进入bin目录,输入./run-example SparkPi 10(迭代次数) 计算π的值
![]()
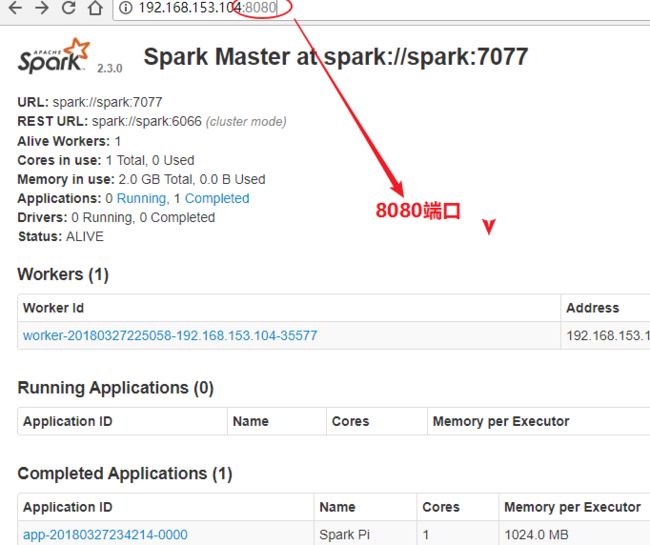
3.启动界面
./sbin/start-all.sh
基础操作
Spark 的主要抽象是分布式的元素集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDDs 可以通过 Hadoop InputFormats 创建(如 HDFS),或者从其他 RDDs 转化而来。
我们从 ./README 文件新建一个 RDD,代码如下(本文出现的 Spark 交互式命令代码中,与位于同一行的注释内容为该命令的说明,命令之后的注释内容表示交互式输出结果):
textFile.count() // RDD 中的 item 数量,对于文本文件,就是总行数
// res0: Long = 95
textFile.first() // RDD 中的第一个 item,对于文本文件,就是第一行内容
// res1: String = # Apache Spark

接着演示 transformation,通过 filter transformation 来返回一个新的 RDD,代码如下:
val linesWithSpark = textFile.filter(line => line.contains("Spark")) // 筛选出包含 Spark 的行
linesWithSpark.count() // 统计行数
// res4: Long = 17可以看到一共有 17 行内容包含 Spark,这与通过 Linux 命令 cat ./README.md | grep "Spark" -c 得到的结果一致,说明是正确的。action 和 transformation 可以用链式操作的方式结合使用,使代码更为简洁:
textFile.filter(line => line.contains("Spark")).count() // 统计包含 Spark 的行数
// res4: Long = 17RDD的更多操作
RDDs 支持两种类型的操作
- actions: 在数据集上运行计算后返回值
- transformations: 转换, 从现有数据集创建一个新的数据集
RDD 的 actions 和 transformations 可用在更复杂的计算中,例如通过如下代码可以找到包含单词最多的那一行内容共有几个单词:
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
// res5: Int = 14代码首先将每一行内容 map 为一个整数,这将创建一个新的 RDD,并在这个 RDD 中执行 reduce 操作,找到最大的数。map()、reduce() 中的参数是 Scala 的函数字面量(function literals,也称为闭包 closures),并且可以使用语言特征或 Scala/Java 的库。例如,通过使用 Math.max() 函数(需要导入 Java 的 Math 库),可以使上述代码更容易理解:
import java.lang.Math
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
// res6: Int = 14WordCount:
Hadoop MapReduce 是常见的数据流模式,在 Spark 中同样可以实现(下面这个例子也就是 WordCount):
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 实现单词统计
// wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at :29
wordCounts.collect() // 输出单词统计结果
// res7: Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing.,1), (Because,1), (The,1)...) 缓存
Spark 支持在集群范围内将数据集缓存至每一个节点的内存中,可避免数据传输,当数据需要重复访问时这个特征非常有用,例如查询体积小的“热”数据集,或是运行如 PageRank 的迭代算法。调用 cache(),就可以将数据集进行缓存:
linesWithSpark.cache()