MySQL深入学习——第五章 慢查询&索引优化实战学习笔记
一、什么是慢查询?
慢查询日志,顾名思义,就是查询慢的日志,是指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志。该日志能为SQL语句的优化带来很好的帮助。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
1、慢查询配置
1.1、慢查询基本配置
slow_query_log 启动停止技术慢查询日志
slow_query_log_file 指定慢查询日志得存储路径及文件(默认和数据文件放一起)
long_query_time 指定记录慢查询日志SQL执行时间得伐值(单位:秒,默认10秒)
log_queries_not_using_indexes 是否记录未使用索引的SQL
log_output 日志存放的地方【TABLE】【FILE】【FILE,TABLE】
配置了慢查询后,它会记录符合条件的SQL
包括:查询语句,数据修改语句,已经回滚得SQL
实操:通过下面命令查看下上面的配置:
show VARIABLES like '%slow_query_log%';
show VARIABLES like '%slow_query_log_file%';
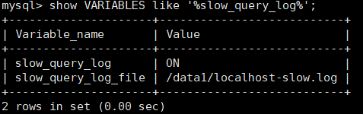
show VARIABLES like '%long_query_time%'; -- 10秒 默认
show VARIABLES like '%log_queries_not_using_indexes%'; -- 默认off
show VARIABLES like 'log_output';
参数设置:
set global long_query_time=0; --- 默认10秒,这里为了演示方便设置为0
set GLOBAL slow_query_log=1; -- 开启慢查询日志
set global log_output='FILE,TABLE'; -- 项目开发中日志只能记录在日志文件中,不能记表中
设置完成后,查询一些列表可以发现慢查询的日志文件里面有数据了。
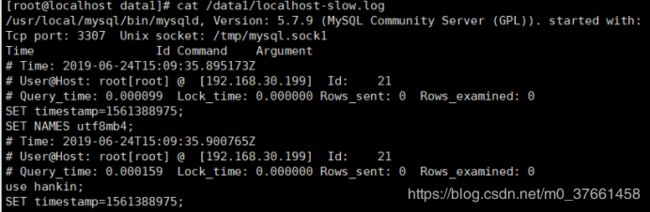
cat /data1/localhost-slow.log -- 多实例
cat /usr/local/mysql/data/localhost-slow.log -- 单实例
1.2、慢查询解读
从慢查询日志里面摘选一条慢查询日志,数据组成如下:
# User@Host: root[root] @ [192.168.30.199] Id: 21
# Query_time: 0.000078 Lock_time: 0.000000 Rows_sent: 4 Rows_examined: 4
SET timestamp=1561389688;
# administrator command: Init DB;
# Time: 2019-06-24T15:21:28.258812Z
# User@Host: root[root] @ [192.168.30.199] Id: 21
# Query_time: 0.000402 Lock_time: 0.000167 Rows_sent: 8 Rows_examined: 8
SET timestamp=1561389688;
SHOW COLUMNS FROM `hankin`.`t_user`;
慢查询格式显示:
第一行:用户名 、用户的IP信息、线程ID号
第二行:执行花费的时间【单位:毫秒】
第三行:执行获得锁的时间
第四行:获得的结果行数
第五行:扫描的数据行数
第六行:这SQL执行的具体时间
第七行:具体的SQL语句
2、慢查询分析
慢查询的日志记录非常多,要从里面找寻一条查询慢的日志并不是很容易的事情,一般来说都需要一些工具辅助才能快速定位到需要优化的SQL语句,下面介绍两个慢查询辅助工具
2.1、Mysqldumpslow
常用的慢查询日志分析工具,汇总除查询条件外其他完全相同的SQL,并将分析结果按照参数中所指定的顺序输出。
语法:mysqldumpslow -s r -t 10 slocalhost-slow.log
-s order (c,t,l,r,at,al,ar)
c:总次数, t:总时间,l:锁的时间, r:总数据行
at,al,ar :t,l,r平均数 【例如:at = 总时间/总次数】
-t top 指定取前面几天作为结果输出
mysqldumpslow -s t -t 10
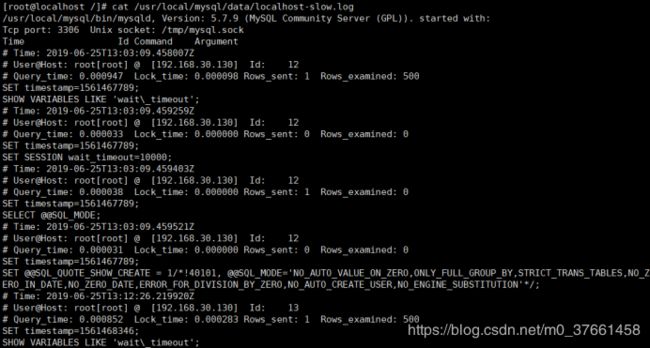
cat /data1/localhost-slow.log (多实例路劲)
cat /usr/local/mysql/data/localhost-slow.log
2.1、pt_query_digest
是用于分析mysql慢查询的一个工具,与mysqldumpshow工具相比,py-query_digest 工具的分析结果更具体,更完善。有时因为某些原因如权限不足等,无法在服务器上记录查询,这样的限制我们也常常碰到。
perl的模块:
yum install -y perl-CPAN perl-Time-HiRes
安装步骤:
方法一:rpm安装
cd /usr/local/src
wget percona.com/get/percona-toolkit.rpm
yum install -y percona-toolkit.rpm
工具安装目录在:/usr/bin
方法二:源码安装
cd /usr/local/src
wget percona.com/get/percona-toolkit.tar.gz
tar zxf percona-toolkit.tar.gz
cd percona-toolkit-2.2.19
perl Makefile.PL PREFIX=/usr/local/percona-toolkit
make && make install
工具安装目录在:/usr/local/percona-toolkit/bin
首先来看下一个命令:
yum -y install 'perl(Data::Dumper)';
yum -y install perl-Digest-MD5
yum -y install perl-DBI
yum -y install perl-DBD-MySQL
查看慢查询命令:
perl ./pt-query-digest --explain h=192.168.30.130,u=root,p=root /usr/local/mysql/data/localhost-slow.log

汇总信息【总的查询时间】、【总的锁定时间】、【总的获取数据量】、【扫描的数据量】、【查询大小】
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
1)扩展阅读:
语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]
--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。
--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。
--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
--limit 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
--host mysql服务器地址
--user mysql用户名
--password mysql用户密码
--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。
--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
--until 截止时间,配合—since可以分析一段时间内的慢查询。
2)分析pt-query-digest输出结果
第一部分:总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
# 该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 340ms user time, 140ms system time, 23.99M rss, 203.11M vsz
# 工具执行时间
# Current date: Fri Nov 25 02:37:18 2016
# 运行分析工具的主机名
# Hostname: localhost.localdomain
# 被分析的文件名
# Files: slow.log
# 语句总数量,唯一的语句数量,QPS,并发数
# Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency
# 日志记录的时间范围
# Time range: 2016-11-22 06:06:18 to 06:11:40
# 属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# 语句执行时间
# Exec time 3s 640ms 2s 1s 2s 999ms 1s
# 锁占用时间
# Lock time 1ms 0 1ms 723us 1ms 1ms 723us
# 发送到客户端的行数
# Rows sent 5 1 4 2.50 4 2.12 2.50
# select语句扫描行数
# Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k
# 查询的字符数
# Query size 455 15 440 227.50 440 300.52 227.50
第二部分:查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT
# 2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
# Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: all events occurred at 2016-11-22 06:11:40
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 50 1
# Exec time 76 2s 2s 2s 2s 2s 0 2s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 20 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0
# Query size 3 15 15 15 15 15 0 15
# String:
# Databases test
# Hosts 192.168.8.1
# Users mysql
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(2)\G
二、索引
1、生活中的索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。
上面的理解比较抽象,举一个例子,平时看任何一本书,首先看到的都是目录,通过目录去查询书籍里面的内容会非常的迅速。
另外通过目录(索引),可以快速查询到目录里面的内容,它能高效获取数据,通过这个简单的案例可以理解所以就是高效获取数据的数据结构。
再来看一个发杂的情况,

我们要去图书馆找一本书,这图书馆的书肯定不是线性存放的,它对不同的书籍内容进行了分类存放,整索引由于一个个节点组成,根节点有中间节点,中间节点下面又由子节点,最后一层是叶子节点。
可见,整个索引结构是一棵倒挂着的树,其实它就是一种数据结构,这种数据结构比前面讲到的线性目录更好的增加了查询的速度。
2、MySql中的索引

MySql中的索引其实也是这么一回事,我们可以在数据库中建立一系列的索引,比如创建主键的时候默认会创建主键索引,上图是一种BTREE的索引,每一个节点都是主键的ID。当我们通过ID来查询内容的时候,首先去查索引库,在到索引库后能快速的定位索引的具体位置。
3、谈下B+Tree
要谈B+TREE说白了还是Tree,但谈这些之前还要从基础开始讲起
3.1、二分查找
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录。
其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。
# 给出一个例子,注意该例子已经是升序排序的,且查找 数字 48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
步骤一:设 low 为下标最小值 0 , high 为下标最大值 9 ;
步骤二:通过 low 和 high 得到 mid ,mid=(low + high) / 2,初始时 mid 为下标 4 (也可以=5,看具体算法实现);
步骤三 : mid=4 对应的数据值是31,31 < 48(我们要找的数字);
步骤四:通过二分查找的思路,将low设置为31对应的下标 4 ,high 保持不变为9,此时mid为 6 ;
步骤五 :mid=6 对应的数据值是42,42 < 48(我们要找的数字);
步骤六:通过二分查找的思路,将low设置为42对应的下标6 ,high保持不变为9,此时mid为7 ;
步骤七 :mid=7对应的数据值是48,48 == 48(我们要找的数字),查找结束;
通过3次 二分查找 就找到了我们所要的数字,而顺序查找需8
3.2、二叉树(Binary Tree)
每个节点至多只有二棵子树;
• 二叉树的子树有左右之分,次序不能颠倒;
• 一棵深度为k,且有 个节点,称为满二叉树(Full Tree);
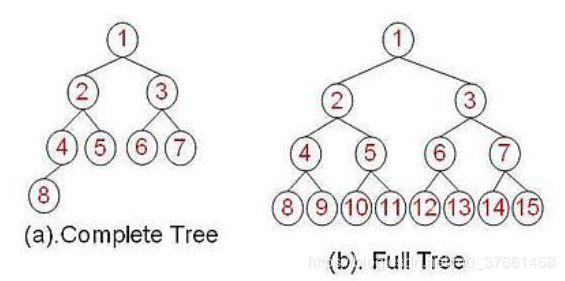
• 一棵深度为k,且root到k-1层的节点树都达到最大,第k层的所有节点都 连续集中 在最左边,此时为完全二叉树(Complete Tree)
3.3、平衡二叉树(AVL-树)
- 左子树和右子树都是平衡二叉树;
- 左子树和右子树的高度差绝对值不超过1;
1)平衡二叉树的遍历
- 前序 :6 ,3, 2, 5,7, 8(ROOT节点在开头, 中 -左-右 顺序)
- 中序 :2, 3, 5, 6,7, 8(中序遍历即为升序,左- 中 -右 顺序)
- 后序 :2, 5, 3, 8,7, 6 (ROOT节点在结尾,左-右- 中 顺序)
2)平衡二叉树的旋转

4、B+树需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销。
4.1、B+树的定义
数据只存储在叶子节点上,非叶子节点只保存索引信息;
非叶子节点(索引节点)存储的只是一个Flag,不保存实际数据记录;
索引节点指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag 叶子节点本身按照数据的升序排序进行链接(串联起来);
叶子节点中的数据在 物理存储上是无序 的,仅仅是在 逻辑上有序 (通过指针串在一起);
4.2、B+树的作用
在块设备上,通过B+树可以有效的存储数据;
所有记录都存储在叶子节点上,非叶子(non-leaf)存储索引(keys)信息;
B+树含有非常高的扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少IO操作;
4.3、B+树的扇出(fan out)
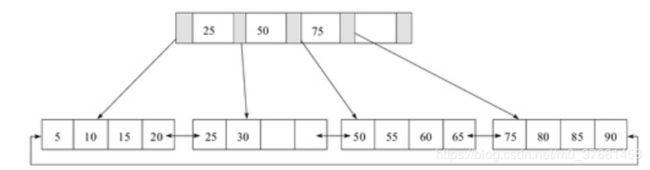
- 该 B+ 树高度为 2
- 每叶子页(LeafPage)4条记录
- 扇出数为5
- 叶子节点(LeafPage)由小到大(有序)串联在一起
扇出:是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针
扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1
图例中的索引节点(Non-LeafPage)最大可以存放4个关键字,但实际使用了3个;
4.4、B+树的插入操作
• B+树的插入
B+树的插入必须保证插入后叶子节点中的记录依然排序。
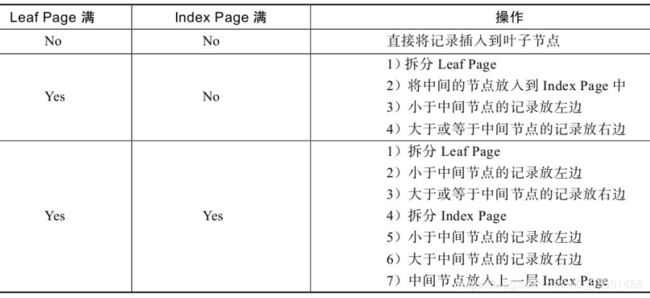
问题:1 插入28:

结果:因为叶子节点未满,可以插入成功,总扇出数不变,顺序也保持不变。
问题2:插入70:

结果:由于叶子节点不能满足直接插入,需要裂变,多出一个扇出60,对应叶子节点变化如上图。
问题3:插入95:

更多细节可以参考:https://blog.csdn.net/shenchaohao12321/article/details/83243314
5、索引的分类
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
6、基础语法
查看索引:
SHOW INDEX FROM table_name\G创建索引:
CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length));
ALTER TABLE 表名 ADD [UNIQUE ] INDEX [indexName] ON (columnname(length))删除索引:
DROP INDEX [indexName] ON mytable;
三、执行计划
什么是执行计划
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
执行计划的作用:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
以上的这些作用会在执行计划详解里面介绍到,在这里不做解释。
执行计划的语法:
执行计划的语法其实非常简单: 在SQL查询的前面加上EXPLAIN关键字就行。
比如:EXPLAIN select * from table1,重点的就是EXPLAIN后面你要分析的SQL语句。
执行计划详解
通过EXPLAIN关键分析的结果由以下列组成,接下来挨个分析每一个列:
id | select_type | table| partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
1、ID列
ID列:描述select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
根据ID的数值结果可以分成一下三种情况
- id相同:执行顺序由上至下
- id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- id相同不同:同时存在
分别举例来看:
1)Id相同

如上图所示,ID列的值全为1,代表执行的允许从t1开始加载,依次为t3与t2
EXPLAIN
select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id and t1.other_column = '';2)Id不同

如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
EXPLAIN select t2.* from t2 where id = (
select id from t1 where id = (select t3.id from t3 where t3.other_column=''));3)Id相同又不同

id如果相同,可以认为是一组,从上往下顺序执行;
在所有组中,id值越大,优先级越高,越先执行
EXPLAIN select t2.* from (select t3.id from t3 where t3.other_column = '' ) s1 ,t2 where s1.id = t2.id2、select_type列
Select_type:查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询
类型如下:

1)SIMPLE类型
EXPLAIN select * from t1;
简单的 select 查询,查询中不包含子查询或者UNION

2)PRIMARY与SUBQUERY类型
PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为
SUBQUERY:在SELECT或WHERE列表中包含了子查询
EXPLAIN select t1.*,(select t2.id from t2 where t2.id = 1 ) from t1

3)DERIVED类型
在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询, 把结果放在临时表里。
select t1.* from t1 ,(select t2.* from t2 where t2.id = 1 ) s2 where t1.id = s2.id;

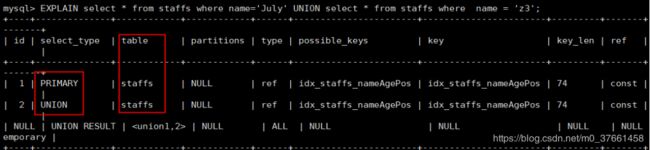
4)UNION RESULT 与UNION类型
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;
UNION RESULT:从UNION表获取结果的SELECT
# UNION RESULT ,UNION
EXPLAIN select * from staffs where name='July' UNION select * from staffs where name = 'z3';

3、table列
显示这一行的数据是关于哪张表的
4、Type列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
需要记忆的:
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
1)System与const访问类型
System:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
Const:表示通过索引一次就找到了。
const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快
如将主键置于where列表中,MySQL就能将该查询转换为一个常量

EXPLAIN SELECT * from (select * from t2 where id = 1) d1;

2)eq_ref访问类型
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描

EXPLAIN SELECT * from t1,t2 where t1.id = t2.id;

3)Ref访问类型
非唯一性索引扫描,返回匹配某个单独值的所有行。
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。

EXPLAIN select count(DISTINCT col1) from t1 where col1 = 'ac';

或者EXPLAIN select col1 from t1 where col1 = 'ac';
4)Range访问类型
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询
这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
EXPLAIN select * from t1 where id BETWEEN 30 and 60;
EXPLAIN select * from t1 where id in(1,2);

5)Index访问类型
当查询的结果全为索引列的时候,虽然也是全部扫描,但是只查询的索引库,而没有去查询数据。

EXPLAIN select c2 from testdemo
6)All访问类型
Full Table Scan,将遍历全表以找到匹配的行

5、possible_keys 与Key列
possible_keys:可能使用的key
Key:实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
这里的覆盖索引非常重要,后面会单独的来讲
EXPLAIN select col1,col2 from t1;

其中key和possible_keys都可以出现null的情况(结婚邀请朋友的例子)。
6、key_len列
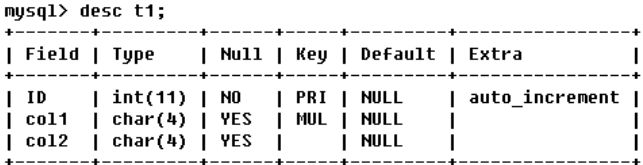
desc select * from ta where col1 ='ab';
desc select * from ta where col1 ='ab' and col2 = 'ac';

Key_len表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
注意:
根据底层使用的不通存储引擎,受影响的行数这个指标可能是一个估计值,也可能是一个精确值。及时受影响的行数是一个估计值(例如当使用InnoDB存储引擎管理表存储时),通常秦光霞这个估计值也足以使优化器做出一个有充分依据的决定。
- key_len表示索引使用的字节数,
- 根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
- char和varchar跟字符编码也有密切的联系,
- latin1占用1个字节,gbk占用2个字节,utf8占用3个字节。(不同字符编码占用的存储空间不同)
6.1、字符类型
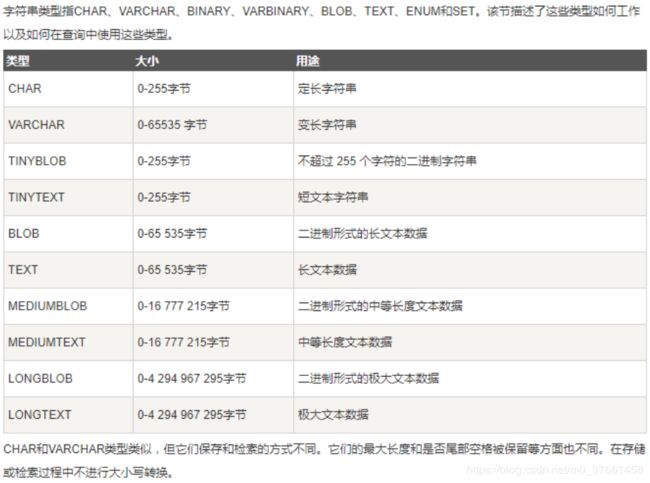
以上这个表列出了所有字符类型,但真正建所有的类型常用情况只是CHAR、VARCHAR
1)字符类型-索引字段为char类型+不可为Null时
CREATE TABLE `s1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(10) NOT NULL,
`addr` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s1 where name='enjoy';name这一列为char(10),字符集为utf-8占用3个字节
Keylen=10*3

2)字符类型-索引字段为char类型+允许为Null时
CREATE TABLE `s2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(10) DEFAULT NULL,
`addr` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s2 where name='enjoyedu';name这一列为char(10),字符集为utf-8占用3个字节,外加需要存入一个null值
Keylen=10*3+1(null) 结果为31

3)索引字段为varchar类型+不可为Null时
CREATE TABLE `s3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`addr` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s3 where name='enjoyeud';Keylen=varchar(n)变长字段+不允许Null=n*(utf8=3,gbk=2,latin1=1)+2

4)索引字段为varchar类型+允许为Null时
CREATE TABLE `s3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`addr` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s3 where name='enjoyeud';Keylen=varchar(n)变长字段+允许Null=n*(utf8=3,gbk=2,latin1=1)+1(NULL)+2

6.2、数值类型

CREATE TABLE `numberKeyLen ` (
`c0` int(255) NOT NULL ,
`c1` tinyint(255) NULL DEFAULT NULL ,
`c2` smallint(255) NULL DEFAULT NULL ,
`c3` mediumint(255) NULL DEFAULT NULL ,
`c4` int(255) NULL DEFAULT NULL ,
`c5` bigint(255) NULL DEFAULT NULL ,
`c6` float(255,0) NULL DEFAULT NULL ,
`c7` double(255,0) NULL DEFAULT NULL ,
PRIMARY KEY (`c0`),
INDEX `index_tinyint` (`c1`) USING BTREE ,
INDEX `index_smallint` (`c2`) USING BTREE ,
INDEX `index_mediumint` (`c3`) USING BTREE ,
INDEX `index_int` (`c4`) USING BTREE ,
INDEX `index_bigint` (`c5`) USING BTREE ,
INDEX `index_float` (`c6`) USING BTREE ,
INDEX `index_double` (`c7`) USING BTREE
)ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
ROW_FORMAT=COMPACT;EXPLAIN select * from numberKeyLen where c1=1
EXPLAIN select * from numberKeyLen where c2=1
EXPLAIN select * from numberKeyLen where c3=1
EXPLAIN select * from numberKeyLen where c4=1
EXPLAIN select * from numberKeyLen where c5=1
EXPLAIN select * from numberKeyLen where c6=1
EXPLAIN select * from numberKeyLen where c7=16.3、日期和时间
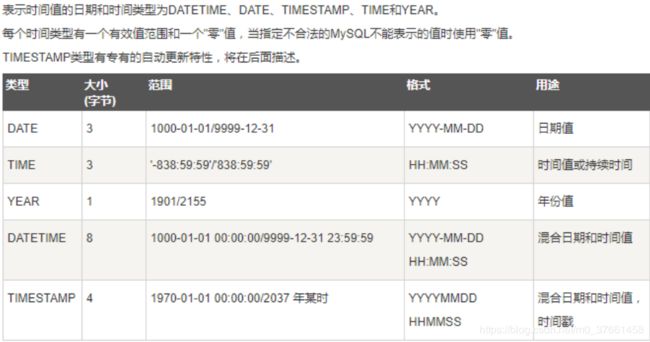
datetime类型在5.6中字段长度是5个字节
datetime类型在5.5中字段长度是8个字节
CREATE TABLE `datatimekeylen ` (
`c1` date NULL DEFAULT NULL ,
`c2` time NULL DEFAULT NULL ,
`c3` year NULL DEFAULT NULL ,
`c4` datetime NULL DEFAULT NULL ,
`c5` timestamp NULL DEFAULT NULL ,
INDEX `index_date` (`c1`) USING BTREE ,
INDEX `index_time` (`c2`) USING BTREE ,
INDEX `index_year` (`c3`) USING BTREE ,
INDEX `index_datetime` (`c4`) USING BTREE ,
INDEX `index_timestamp` (`c5`) USING BTREE
)ENGINE=InnoDB DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci ROW_FORMAT=COMPACT;
EXPLAIN SELECT * from datatimekeylen where c1 = 1;
EXPLAIN SELECT * from datatimekeylen where c2 = 1;
EXPLAIN SELECT * from datatimekeylen where c3 = 1;
EXPLAIN SELECT * from datatimekeylen where c4 = 1;
EXPLAIN SELECT * from datatimekeylen where c5 = 1;总结
字符类型:
变长字段需要额外的2个字节(VARCHAR值保存时只保存需要的字符数,另加一个字节来记录长度(如果列声明的长度超过255,则使用两个字节),所以VARCAHR索引长度计算时候要加2),固定长度字段不需要额外的字节。
而NULL都需要1个字节的额外空间,所以索引字段最好不要为NULL,因为NULL让统计更加复杂并且需要额外的存储空间。
复合索引有最左前缀的特性,如果复合索引能全部使用上,则是复合索引字段的索引长度之和,这也可以用来判定复合索引是否部分使用,还是全部使用。
整数/浮点数/时间类型的索引长度
NOT NULL=字段本身的字段长度
NULL=字段本身的字段长度+1(因为需要有是否为空的标记,这个标记需要占用1个字节)
datetime类型在5.6中字段长度是5个字节,datetime类型在5.5中字段长度是8个字节
7、Ref列
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值

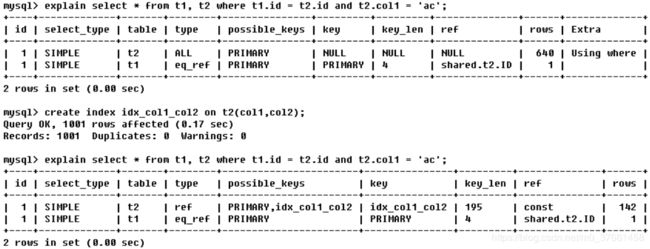
EXPLAIN select * from s1 ,s2 where s1.id = s2.id and s1.name = 'enjoy'
由key_len可知t1表的idx_col1_col2被充分使用,col1匹配t2表的col1,col2匹配了一个常量,即 'ac'
其中 【shared.t2.col1】 为 【数据库.表.列】
8、Rows列
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
9、Extra列
包含不适合在其他列中显示但十分重要的额外信息

1)Using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为“文件排序”,当发现有Using filesort 后,实际上就是发现了可以优化的地方。

上图其实是一种索引失效的情况,后面会讲,可以看出查询中用到了个联合索引,索引分别为col1,col2,col3

当我排序新增了个col2,发现using filesort 就没有了
EXPLAIN select col1 from t1 where col1='ac' order by col3;
EXPLAIN select col1 from t1 where col1='ac' order by col2,col3;
2)Using temporary
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。

尤其发现在执行计划里面有using filesort而且还有Using temporary的时候,特别需要注意
EXPLAIN select col1 from t1 where col1 in('ac','ab','aa') GROUP BY col2;
EXPLAIN select col1 from t1 where col1 in('ac','ab','aa') GROUP BY col1,col2;
3)Using index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;

如果没有同时出现using where,表明索引用来读取数据而非执行查找动作

EXPLAIN select col2 from t1 where col1 = 'ab';
EXPLAIN select col2 from t1 ;
覆盖索引:
覆盖索引(Covering Index),一说为索引覆盖。
理解方式一:就是select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引
注意:
如果要使用覆盖索引,一定要注意select列表中只取出需要的列,不可select *,
因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
所以,千万不能为了查询而在所有列上都建立索引,会严重影响修改维护的性能。
4)Using where 与 using join buffer
Using where 表明使用了where过滤
using join buffer 使用了连接缓存:
show VARIABLES like '%join_buffer_size%'
EXPLAIN select * from t1 JOIN t2 on t1.other_column = t2.other_column;

5)impossible where
where子句的值总是false,不能用来获取任何元组
EXPLAIN select * from t1 where 1=2;
EXPLAIN select * from t1 where t1.other_column ='enjoy' and t1.other_column = 'edu';
