史上最简单MySQL教程详解(基础篇)之多表联合查询
-
- 常用术语
- 表连接的方式
- 数据准备
- student表
- college表
- 内连接
- 外连接
- 左外连接
- 右外连接
- 注意事项:
- 自连接
- 子查询
在上篇文章史上最简单MySQL教程详解(基础篇)之数据库设计范式及应用举例我们介绍过,在关系型数据库中,我们通常为了减少数据的冗余量将对数据表进行规范,将数据分割到不同的表中。当我们需要将这些数据重新合成一条时,就需要用到我们介绍来将要说到的表连接。
常用术语
- 冗余(Redundancy):存储两次数据,以便使系统更快速。
- 主键(Primary Key):主键是唯一的。同一张表中不允许出现同样两个键值。一个键值只对应着一行。
- 外键(Foreign Key):用于连接两张表。
表连接的方式
- 内连接
- 外连接
- 自连接
我们接下来将对这三种连接进行详细的介绍。
数据准备
我们需要创建下面的数据表来作为示例:
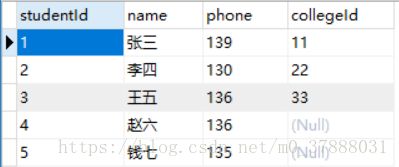
student表
表结构:
| 字段 | 解释 |
|---|---|
| studentId | 学号(主键) |
| name | 姓名 |
| phone | 电话 |
| collegeId | 学生所在学院ID(外键) |
SQL语句:
CREATE TABLE `student` (
`studentId` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`name` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`phone` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`collegeId` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`studentId`),
KEY `collegeId` (`collegeId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;数据:
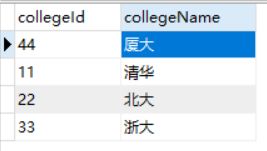
college表
表结构:
| 字段 | 解释 |
|---|---|
| collegeId | 学院ID(主键) |
| collegeName | 学院名 |
SQL语句:
CREATE TABLE `college` (
`collegeId` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`collegeName` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`collegeId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;数据:
内连接
内连接就是表间的主键与外键相连,只取得键值一致的,可以获取双方表中的数据连接方式。语法如下:
SELECT 列名1,列名2... FROM 表1 INNER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;运行结果:
mysql> SELECT student.name,college.collegeName FROM student INNER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
+——+————-+
3 rows in set (0.04 sec)
这样,我们就成功将【student】表中的【name】和【college】表中的【collegeName】进行了重新结合,并检索出来。
外连接
与取得双方表中数据的内连接相比,外连接只能取得其中一方存在的数据,外连接又分为左连接和右连接两种情况。接下来,我们将介绍这两种连接方式。
左外连接
左连接是以左表为标准,只查询在左边表中存在的数据,当然需要两个表中的键值一致。语法如下:
SELECT 列名1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;运行结果:
mysql> SELECT student.name,college.collegeName FROM student LEFT OUTER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
| 赵六 | NULL |
| 钱七 | NULL |
+——+————-+
5 rows in set (0.00 sec)
我们可以看出,与内连接查询结果不同的是:【赵六】、【钱七】这两个学生虽然没有学校ID但是也被查出来了,这就是我们所说的,他会以左连接中的左表的全部数据作为基准进行查询。
右外连接
同理,右连接将会以右边作为基准,进行检索。语法如下:
SELECT 列名1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;运行结果:
mysql> SELECT student.name,college.collegeName FROM student RIGHT OUTER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
| NULL | 厦大 |
+——+————-+
4 rows in set (0.00 sec)
我们可以看出,这里就是以右边的表【college】为基准进行了检索,因为【student】中并没有【厦大】的学生,所以检索出来的为【NULL】
注意事项:
- 内连接是抽取两表间键值一致的数据,而外连接(左连接,右连接)时,是以其中一个表的全部记录作为基准进行检索。
- 左连接和右连接只有数据基准的区别,本质上是一样的,具体使用哪一种连接,根据实际的需求所决定
- 无论是内连接还是外连接,在查询的时候最好使用【表名.列名】的方式指定需要查询的列名,否则一旦两个表中出现了列名一致的数据时,可能会报错,养成良好的习惯很重要。
- 表的别名:其实我们在查询的过程中,如果遇到了特别复杂的数据表名,我们可以通过取别名的方式来实现,使用的是我们以前使用过的【AS】语句,例如,我们的内连接就可以化简为下面的语句:
SELECT s.name,c.collegeName FROM student AS s INNER JOIN college AS c ON s.collegeId = c.collegeId;查询结果一致,是不是瞬间觉得语句简洁很多呢?
自连接
自连接顾名思义就是自己跟自己连接,有人或许会问,这样的连接有意义吗?答案是肯定的。
例如,我们将【student】的数据改为下图:
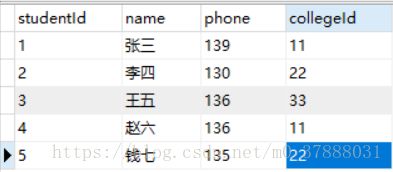
运行结果如图:
mysql> SELECT * FROM student s ,student a where a.collegeId=s.collegeId AND a.name <> s.name ORDER BY a.collegeId;
+———–+——+——-+———–+———–+——+——-+———–+
| studentId | name | phone | collegeId | studentId | name | phone | collegeId |
+———–+——+——-+———–+———–+——+——-+———–+
| 4 | 赵六 | 136 | 11 | 1 | 张三 | 139 | 11 |
| 1 | 张三 | 139 | 11 | 4 | 赵六 | 136 | 11 |
| 5 | 钱七 | 135 | 22 | 2 | 李四 | 130 | 22 |
| 2 | 李四 | 130 | 22 | 5 | 钱七 | 135 | 22 |
+———–+——+——-+———–+———–+——+——-+———–+
4 rows in set (0.00 sec)
可以看出,我们就将【student】表中在同一个学校的学生查出来了。
语句释义:
- 【student s】和【student a】的含义就是分别给我们的【student】表取了两个不同的别名;
- 【a.collegeId = s.collegeId AND a.name <> s.name 】的含义是找出【collegeId】相同,但是【name】不同的人.
- 【ORDER BY a.collegeId;】将结果顺序输出;
自连接的使用情况还是很多的,比如当我们找某个站点所经过的所有公交等,都可以采用自连接的方式进行检索;
子查询
通常我们在查询的SQL中嵌套查询,称为子查询。子查询通常会使复杂的查询变得简单,但是相关的子查询要对基础表的每一条数据都进行子查询的动作,所以当表单中数据过大时,一定要慎重选择。基本语法如下:
SELECT 列名1 ...FROM 表名 WHERE 列名 比较运算符 (SELECT 命令);例如:我们利用上面的内连接的例子,在它的基础上查出学校为【清华】的学生的姓名
mysql> SELECT * FROM (SELECT student.name,college.collegeName FROM student INNER JOIN college ON student.collegeId = college.collegeId)b WHERE b.collegeName = ‘清华’;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 赵六 | 清华 |
+——+————-+
2 rows in set (0.00 sec)
查询成功。
到此,已经介绍完了所有关于MySQL基础篇的内容,接下来,我们将介绍史上最简单MySQL教程详解(进阶篇)之存储引擎及默认引擎设置;